Scorecard
Scorecard is an end-to-end platform for evaluating, optimizing, and deploying enterprise AI agents. It helps teams replace subjective …
Scorecard is an end-to-end platform for evaluating, optimizing, and deploying enterprise AI agents. It helps teams replace subjective testing with structured evaluations, providing tools for continuous monitoring, prompt management, and performance metrics to build trustworthy and reliable AI applications with confidence.
About Evaluation
Evaluation tools are AI-powered solutions designed to systematically assess the performance, fairness, and robustness of AI models. These tools leverage various metrics, test datasets, and analytical frameworks to provide deep insights into model behavior. Their primary purpose is to ensure models are reliable, accurate, and ethically sound before and after deployment, playing a critical role in the broader AI model management lifecycle.
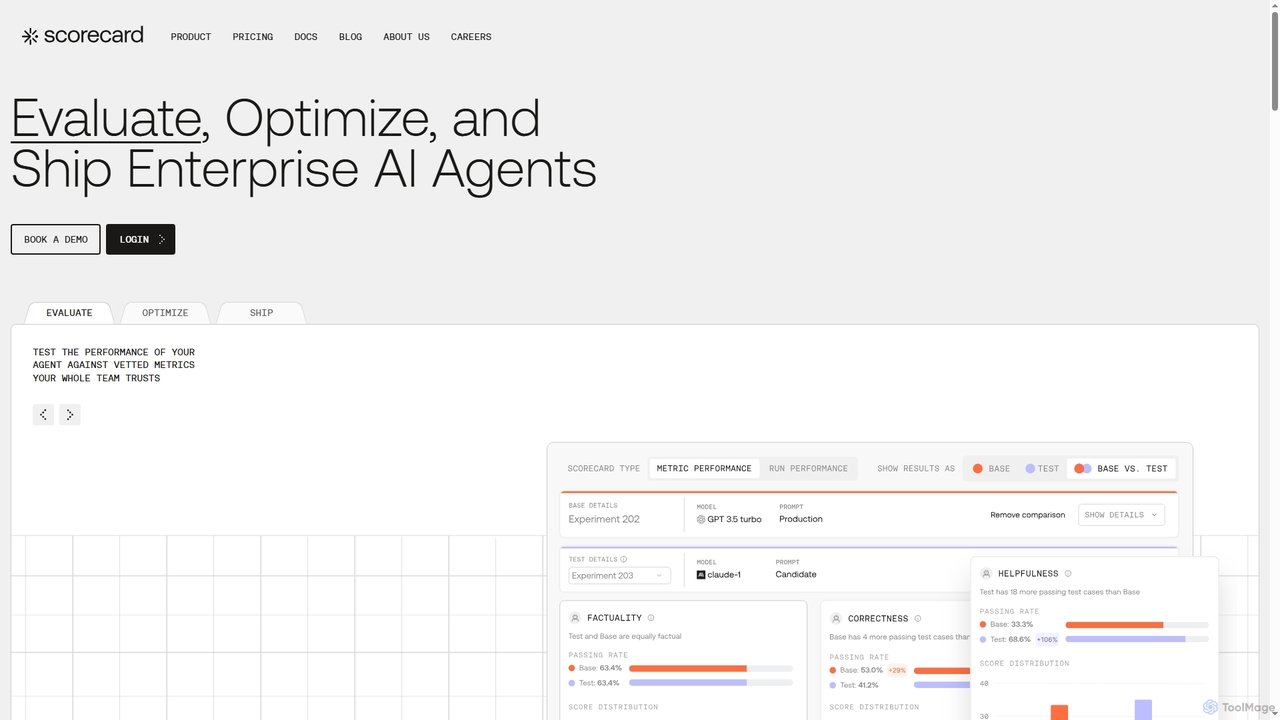
Core Features
- Performance Metrics Calculation: Quantify model accuracy, precision, recall, F1-score, and other relevant metrics.
- Bias Detection & Mitigation: Identify and measure algorithmic biases across different demographic groups or data segments.
- Robustness Testing: Evaluate model stability and resilience against adversarial attacks or unexpected data shifts.
- Explainability (XAI) Integration: Provide insights into why a model made a particular prediction, enhancing transparency.
- Model Version Comparison: Compare the performance of different model iterations or versions to track improvements.
Use Cases
AI model evaluation tools are essential across various stages of the AI lifecycle. Data scientists use them for rigorous pre-deployment validation, ensuring new models meet performance benchmarks. MLOps teams rely on them for continuous monitoring of deployed models, detecting performance drift or data quality issues. Additionally, researchers and developers leverage these tools to compare different model architectures and optimize their AI solutions.
How to Choose
Selecting an AI model evaluation tool requires considering several factors. Prioritize tools that support a comprehensive range of evaluation metrics relevant to your model type and business objectives. Look for strong integration capabilities with your existing MLOps pipelines and data sources. Scalability, interpretability features, and robust reporting functionalities are also crucial for effective model governance and compliance.
EvaluationUse Cases
Pre-deployment Model Validation
Data scientists use evaluation tools to rigorously test new AI models, such as a fraud detection system, against diverse datasets before deployment. This ensures the model meets accuracy and reliability benchmarks, identifying potential weaknesses or edge cases that could lead to costly errors in production. The process helps validate the model's readiness for real-world application, minimizing risks.
Bias and Fairness Assessment
AI ethicists and developers employ evaluation platforms to systematically detect and quantify biases within models, like those used for loan applications or hiring. By analyzing predictions across different demographic groups, they can identify unfair outcomes, understand their root causes, and implement strategies to mitigate discriminatory behavior, ensuring ethical AI deployment.
Continuous Performance Monitoring
MLOps engineers integrate evaluation tools into their production pipelines to continuously monitor the performance of deployed AI models, such as recommendation engines. These tools track key metrics over time, alerting teams to performance degradation, data drift, or concept drift, enabling proactive intervention to maintain model accuracy and relevance.
Comparative Model Selection
Machine learning researchers utilize evaluation tools to compare the performance of multiple candidate models or different versions of the same model. For instance, when developing a natural language processing model, they can objectively assess which architecture or set of hyperparameters yields the best results across various linguistic tasks, guiding optimal model selection.
Regulatory Compliance Reporting
Enterprises in regulated industries, like finance or healthcare, use evaluation tools to generate comprehensive audit trails and performance reports for their AI systems. This helps demonstrate adherence to industry standards and regulatory requirements, such as explainability mandates or fairness guidelines, providing transparency and accountability to auditors and stakeholders.
Adversarial Robustness Testing
Security specialists apply evaluation tools to test AI models, particularly in critical applications like autonomous driving or cybersecurity, against adversarial attacks. By simulating malicious inputs designed to trick the model, they can assess its robustness and identify vulnerabilities, strengthening the model's resilience against sophisticated threats and ensuring its reliability in hostile environments.