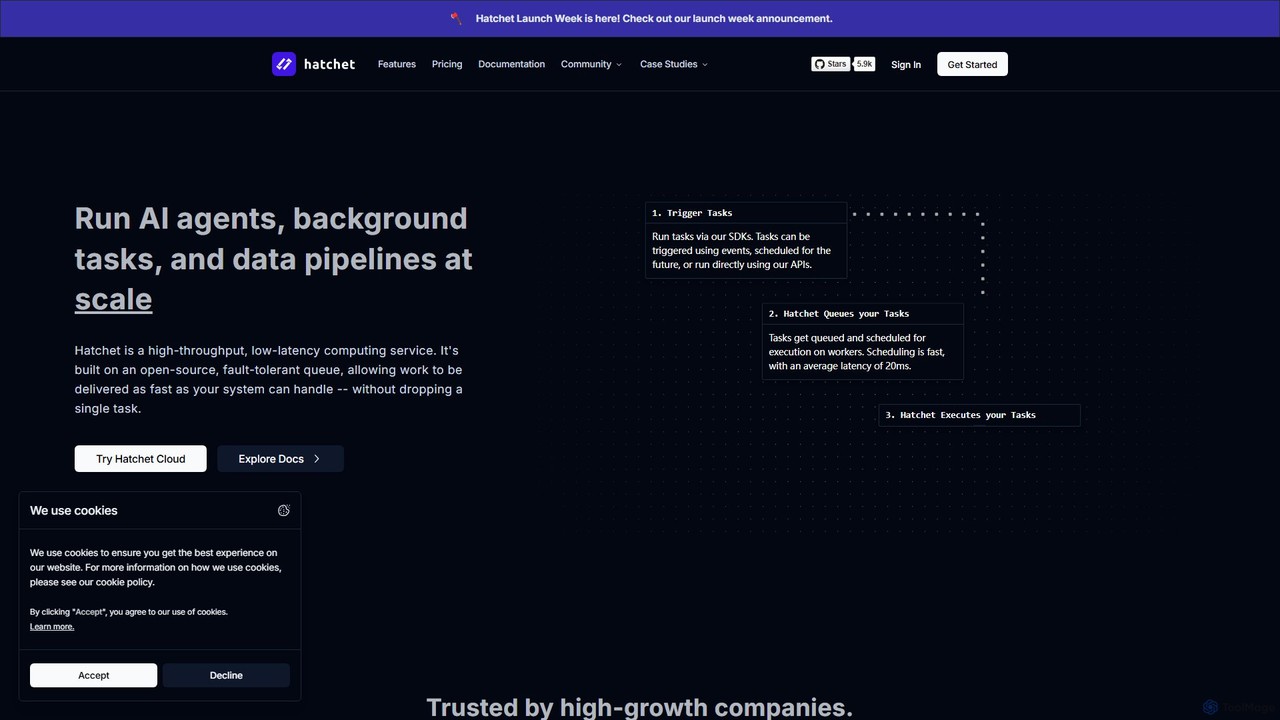
Hatchet
Hatchet is a distributed, fault-tolerant task queue designed to run AI agents, background tasks, and data pipelines at …
Hatchet is a distributed, fault-tolerant task queue designed to run AI agents, background tasks, and data pipelines at scale. It offers high-throughput, low-latency performance, ensuring no task is dropped. With SDKs for Python, Go, and TypeScript, developers can easily orchestrate complex workflows, schedule jobs, and monitor execution with built-in observability tools. It can be used as a managed cloud service or self-hosted.
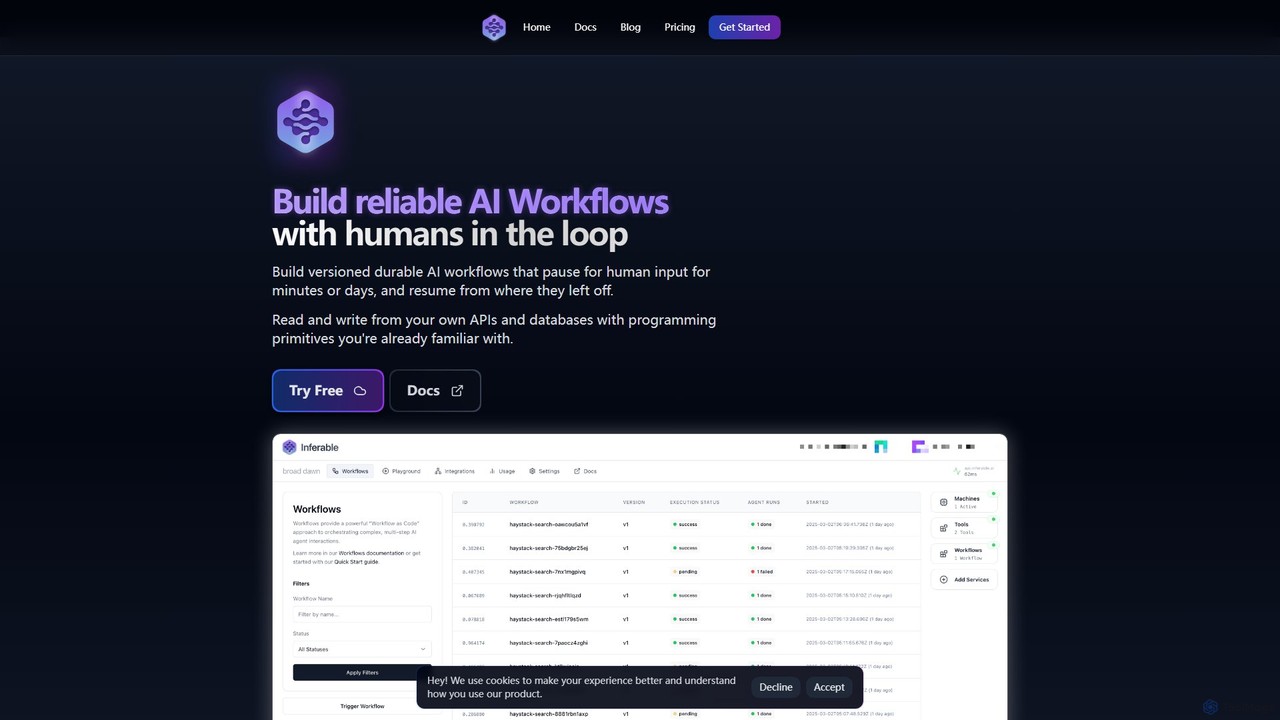
Inferable
Inferable is an open-source, self-hostable developer platform for building reliable, durable, and versioned AI agents and workflows. It …
Inferable is an open-source, self-hostable developer platform for building reliable, durable, and versioned AI agents and workflows. It enables the creation of complex, long-running processes with human-in-the-loop capabilities, structured outputs, and on-premise execution for maximum security and control.
About Orchestration
Orchestration tools are AI-powered solutions designed to automate the coordination, management, and scaling of complex AI workflows, models, and infrastructure components. These tools leverage advanced automation and resource management techniques to ensure that diverse AI services, data pipelines, and computational resources operate together seamlessly and efficiently. Their primary value lies in streamlining the entire AI lifecycle, from development and training to deployment and monitoring, significantly reducing manual overhead and accelerating innovation.
Core Features
- Workflow Automation: Automates the execution of sequential or parallel tasks within AI pipelines, including data preprocessing, model training, and deployment.
- Resource Management: Dynamically allocates and deallocates computational resources like GPUs and CPUs based on real-time workload demands.
- Model Lifecycle Management: Manages the versioning, deployment, scaling, and continuous monitoring of AI models throughout their operational lifespan.
- Integration Capabilities: Provides seamless connectivity with various AI services, data sources, and cloud or on-premise deployment environments.
- Monitoring & Logging: Offers comprehensive real-time insights into workflow status, resource utilization, and model performance, supported by detailed logging.
Applicable Scenarios
Orchestration tools are essential for ML engineers and data scientists managing end-to-end machine learning workflows, from data ingestion to model serving. They are also crucial for developers building multi-modal AI applications that require synchronized execution of different AI models, and for researchers training large models across distributed compute infrastructures.
How to Choose
When selecting an AI orchestration platform, prioritize its integration ecosystem with your existing tools and cloud providers. Evaluate its scalability and flexibility to adapt to varying workloads, and assess the robustness of its monitoring and observability features. Consider the platform's ease of use, level of abstraction, and overall cost efficiency to ensure it aligns with your operational and budgetary needs.
OrchestrationUse Cases
Automated MLOps Pipeline Deployment
ML engineers often face challenges in consistently deploying machine learning models to production, involving data validation, feature engineering, training, evaluation, and deployment. Orchestration tools automate these complex, multi-stage MLOps pipelines, triggering each step upon new data or code commits, and managing dependencies and resource allocation. This ensures reliable, rapid model deployment, reducing manual effort by up to 70% and accelerating time-to-market for AI solutions.
Scaling AI Inference Services
AI application developers need to ensure their inference endpoints can handle fluctuating user demand without over-provisioning expensive resources. Orchestration tools continuously monitor real-time traffic and model latency, automatically scaling up or down the number of inference instances (e.g., GPU pods) across Kubernetes clusters or serverless environments. This guarantees high availability and responsiveness for AI services, optimizing infrastructure costs by paying only for resources actively consumed.
Managing Distributed AI Model Training
AI researchers and ML engineers training large foundation models require distributing workloads across multiple GPUs or machines, which is complex to coordinate. An orchestration platform manages the distribution of data and model parameters, coordinates training jobs across a cluster, handles fault tolerance, and aggregates results. This enables efficient and robust training of large-scale AI models, significantly reducing training time and operational complexity while maximizing compute resource utilization.
Integrating Multi-modal AI Workflows
Building sophisticated AI applications, such as intelligent assistants combining speech recognition, NLP, and text-to-speech, demands seamless integration and sequential execution of distinct AI models. Orchestration tools define and manage the data flow between these diverse AI services, passing outputs from one model as inputs to the next, ensuring data consistency and timely execution. This simplifies the creation of complex, multi-functional AI applications by streamlining component coordination.
Automating Data Preprocessing for AI
Data engineers and scientists spend considerable time cleaning, transforming, and extracting features from raw data before model training. An orchestration system automates this entire data pipeline, from ingesting data from various sources through multiple preprocessing steps (e.g., normalization, tokenization) to storing prepared features. This ensures high-quality, consistent data for AI models, significantly reducing manual data preparation time and improving overall model performance and reliability.
Continuous AI Model Monitoring and Retraining
Deployed AI models can suffer from data drift or concept drift, leading to degraded performance over time. Manual monitoring and retraining are resource-intensive. Orchestration tools continuously track model performance metrics and data characteristics in production. If performance drops or drift is detected, the system automatically triggers a retraining pipeline and potentially redeploys the updated model. This maintains optimal model accuracy and relevance in dynamic environments, ensuring AI applications remain effective with minimal human intervention.