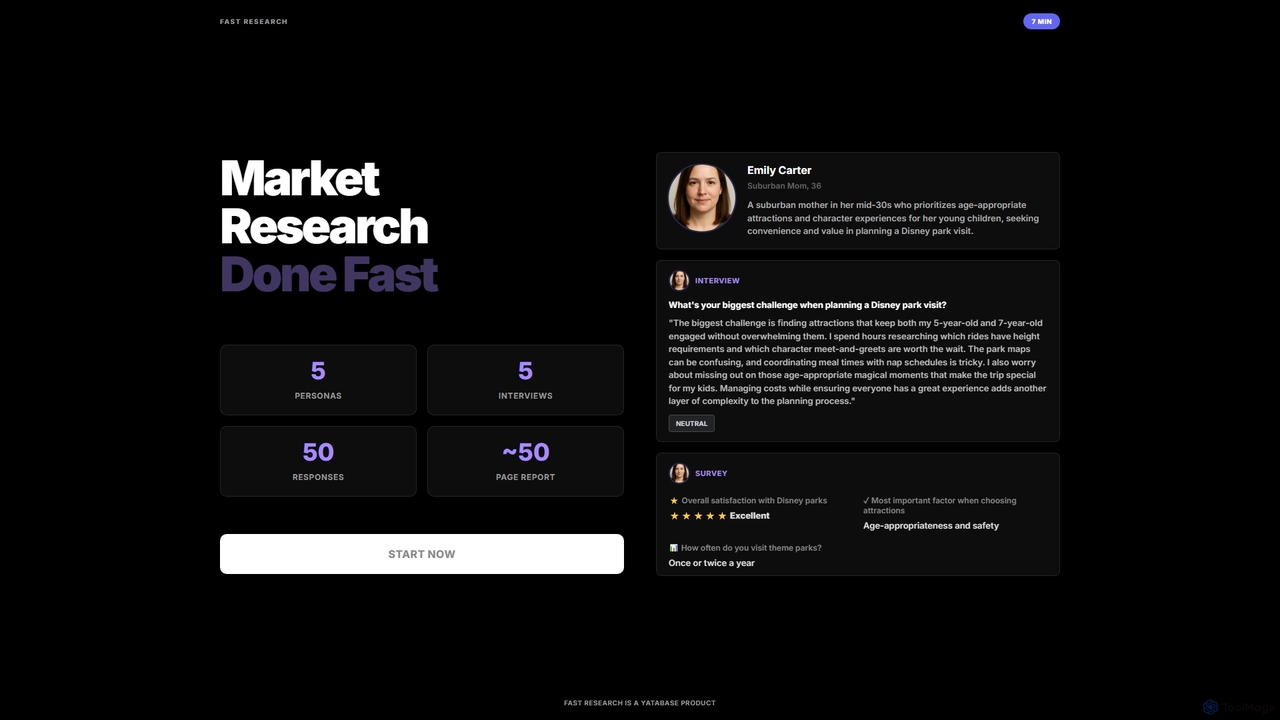
Fast Research
Fast Research is an AI-powered market research tool that rapidly generates synthetic data, including detailed personas, simulated interviews, …
Fast Research is an AI-powered market research tool that rapidly generates synthetic data, including detailed personas, simulated interviews, and survey responses. It delivers comprehensive reports, enabling businesses to gain quick, actionable insights for strategic decision-making without traditional data collection complexities.
About Synthetic Data
Synthetic Data refers to artificially generated datasets that mirror the statistical properties and patterns of real-world data without containing any actual personal or sensitive information. These AI-powered tools leverage advanced algorithms to create realistic data, addressing critical challenges like data privacy, scarcity, and bias. It provides a secure and flexible alternative for various analytical and developmental purposes, particularly within market research.
Core Features
- Privacy Preservation: Generates data that maintains statistical integrity while ensuring no real individual data is exposed.
- Data Augmentation: Creates additional data points to expand existing datasets, improving model training and robustness.
- Bias Mitigation: Allows for the generation of balanced datasets to reduce inherent biases found in real-world data.
- Realistic Simulation: Produces data that accurately reflects the distributions, correlations, and structures of original data.
- Scalability: Enables the generation of large volumes of data on demand, overcoming limitations of real data collection.
Use Cases
Businesses utilize synthetic data to test new product features, simulate market scenarios, or train AI models without compromising customer privacy. Researchers can analyze trends and patterns in sensitive domains like healthcare or finance, ensuring ethical data handling.
How to Choose
When selecting a synthetic data tool, consider the required fidelity (how closely it mimics real data), the types of data it can generate (tabular, image, text), its privacy guarantees, and integration capabilities with existing data pipelines. Evaluate the ease of use and the level of control offered over data characteristics.
Synthetic DataUse Cases
Developing Privacy-Preserving AI Models
Data scientists use synthetic data to train machine learning models for sensitive applications (e.g., healthcare diagnostics, financial fraud detection) without accessing or exposing real patient or customer information. This ensures compliance with strict privacy regulations like GDPR and HIPAA, allowing for robust model development in highly regulated industries.
Simulating Market Behavior for Product Testing
Market researchers generate synthetic customer datasets to simulate various market conditions and consumer responses to new product launches or marketing campaigns. This allows for risk-free A/B testing, scenario planning, and demand forecasting before real-world deployment, saving costs and mitigating potential negative impacts.
Overcoming Data Scarcity in Niche Markets
Startups or businesses in niche industries often lack sufficient real data for robust analytics or AI model training. Synthetic data tools help create extensive, representative datasets to fill these gaps, enabling comprehensive analysis, product development, and competitive intelligence even with limited original data sources.
Enhancing Software Testing and Development
Software developers use synthetic data to populate test environments, ensuring applications can handle diverse data inputs and edge cases without relying on sensitive production data. This accelerates testing cycles, improves software quality, and allows for more thorough validation of new features and updates in a controlled, secure setting.
Mitigating Bias in AI Training Datasets
AI ethics researchers and developers employ synthetic data generation to create balanced datasets that correct for biases present in real-world data (e.g., underrepresentation of certain demographics). This leads to fairer and more equitable AI systems, reducing discriminatory outcomes and improving the overall trustworthiness of AI applications.
Facilitating Data Sharing and Collaboration
Organizations can share synthetic versions of their proprietary or sensitive datasets with external partners, researchers, or regulatory bodies. This enables collaborative innovation and research while strictly adhering to data governance and confidentiality agreements, fostering a secure environment for data-driven insights across ecosystems.