LastMile AI
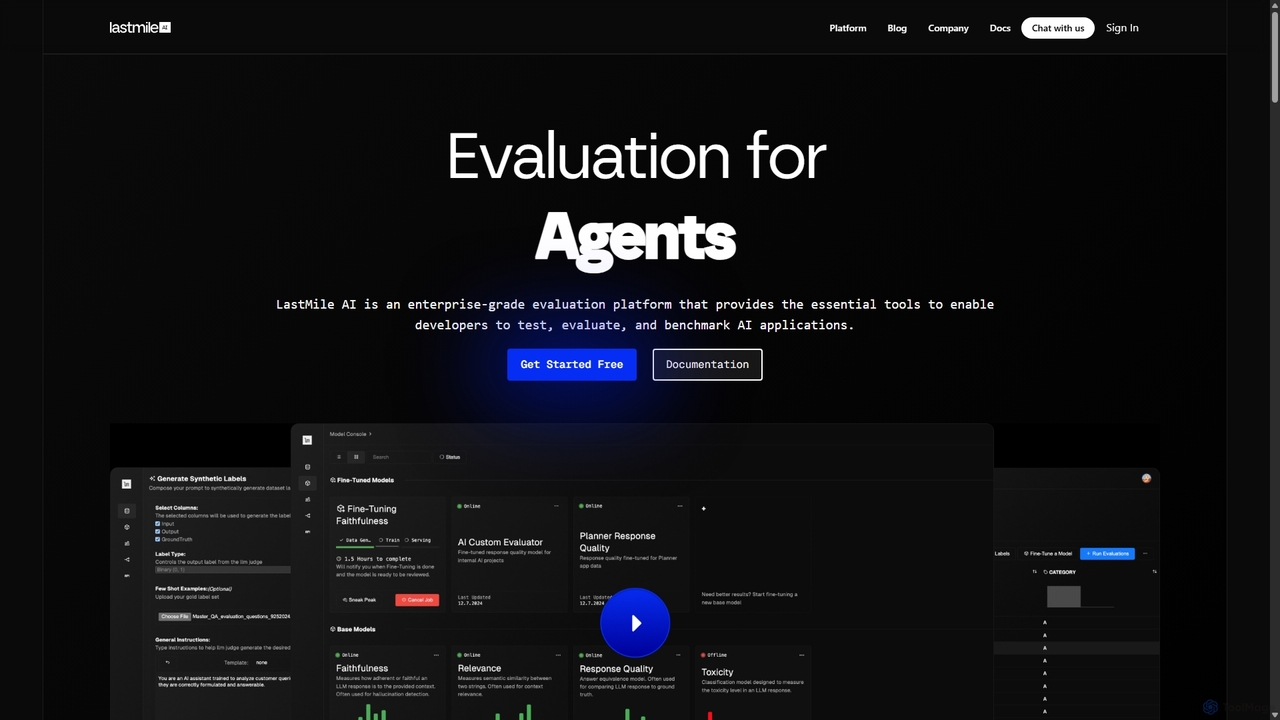
LastMile AI is an enterprise-grade developer platform for testing, evaluating, and monitoring generative AI applications. It provides tools …
LastMile AI is an enterprise-grade developer platform for testing, evaluating, and monitoring generative AI applications. It provides tools like AutoEval for custom evaluator fine-tuning, synthetic data generation, and real-time monitoring to ensure AI systems are reliable and production-ready.
About Experiment Tracking
Experiment Tracking tools are a specialized category of MLOps software for systematically logging, organizing, and comparing machine learning experiments. These platforms capture every component of a model's training run, including code versions, hyperparameters, datasets, and performance metrics. This comprehensive record-keeping enables data scientists and ML engineers to analyze results, reproduce past findings, and collaborate effectively on model development. By providing a centralized and structured repository for all experimental data, these tools eliminate manual tracking in spreadsheets and ensure a transparent, auditable development lifecycle.
Core Features
- Parameter & Metric Logging: Automatically record all hyperparameters, configurations, and performance metrics like accuracy and loss for each run.
- Code & Data Versioning: Link experiments to specific Git commits and data versions to ensure full context and traceability.
- Artifact Management: Store, version, and manage outputs such as trained model files, visualizations, and data checkpoints.
- Experiment Comparison: Utilize interactive dashboards to visually compare the performance and parameters of multiple experiments side-by-side.
- Reproducibility: Capture the complete environment, including dependencies, to guarantee that any experiment can be precisely replicated by team members.
Use Cases
These tools are essential for any team engaged in serious machine learning development. Data science teams use them for hyperparameter tuning and model architecture selection. ML engineering teams rely on them to ensure model reproducibility and to debug performance regressions. In regulated industries like finance and healthcare, they provide a critical audit trail for model governance and compliance.
How to Choose
When selecting an Experiment Tracking tool, consider its integration with your existing ML frameworks (e.g., PyTorch, TensorFlow). Evaluate its scalability for handling a large volume of experiments and artifacts. Decide between a managed cloud service (SaaS) for ease of use or a self-hosted solution for greater control. Finally, assess the platform's collaboration features, such as user roles, project organization, and reporting capabilities.
Experiment TrackingUse Cases
Optimizing Hyperparameters for a Recommendation Engine
A data scientist at an e-commerce company is tasked with improving the accuracy of their product recommendation engine. They use an Experiment Tracking tool to systematically test various combinations of hyperparameters, such as learning rate, batch size, and the number of hidden layers. For each experiment, the tool automatically logs the parameters, training/validation loss, and click-through rate. The interactive dashboard allows the scientist to quickly identify the top-performing models, visualize the impact of each hyperparameter, and share the results with the team, reducing the optimization cycle from weeks to days.
Comparing Computer Vision Model Architectures
An ML research team is developing an image classification system and needs to decide between several architectures (e.g., ResNet, EfficientNet, Vision Transformer). Using an Experiment Tracking platform, they run each architecture on the same dataset. The platform logs performance metrics like accuracy and F1-score, alongside computational costs such as training time and GPU memory usage. The comparison view makes it easy to create a trade-off analysis, helping the team select the architecture that provides the best balance of accuracy and efficiency for their specific deployment constraints.
Collaborative Development of a Fraud Detection Model
A distributed team of ML engineers at a fintech company is building a new fraud detection model. They use a central Experiment Tracking server to coordinate their work. Each engineer can push their experiments, which include code changes, new features, and model results. The platform serves as a single source of truth, allowing the team lead to review progress, compare different approaches side-by-side, and easily reproduce a colleague's results for verification. This prevents duplicated effort and ensures everyone is working with the most up-to-date information and best-performing model candidates.
Ensuring Reproducibility for Scientific Research
An academic researcher is publishing a paper on a novel machine learning algorithm. To ensure their results are verifiable and reproducible by the scientific community, they use an Experiment Tracking tool. The tool captures the exact code version (via Git commit hash), the dataset used, all hyperparameters, and the software environment (e.g., library versions). They can then share a link to the tracked experiment, providing a complete, transparent record that allows other researchers to replicate their findings precisely, strengthening the credibility and impact of their work.
Auditing Model Lineage for Regulatory Compliance
A financial institution is required to provide regulators with a complete audit trail for its credit scoring models. An ML Engineer uses an Experiment Tracking tool to create an immutable record for every model version. This record, or lineage, links the final model artifact back to the specific data it was trained on, the exact code used for training (Git commit), and the full set of hyperparameters. When an audit is requested, the engineer can generate a report directly from the platform, demonstrating compliance and providing full transparency into the model's development process.
A/B Testing Feature Engineering Strategies
A data science team wants to determine which feature engineering approach yields better results for their churn prediction model. They create two main experiments: one with features derived from polynomial expansion and another with features from domain-specific aggregations. The Experiment Tracking tool logs the results for both. By comparing the ROC AUC scores and precision-recall curves directly in the UI, the team can make a data-driven decision. They can also tag the winning experiment, making it easy to promote that specific feature engineering pipeline to production.