LastMile AI
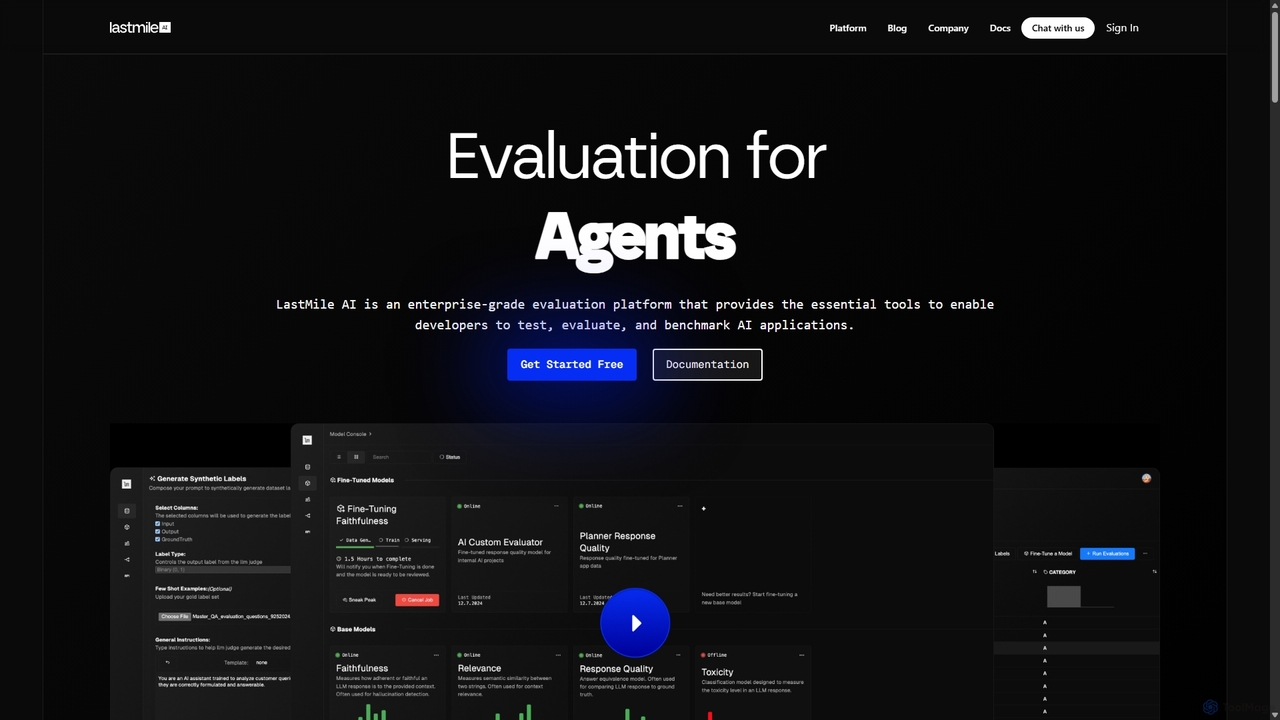
LastMile AI is an enterprise-grade developer platform for testing, evaluating, and monitoring generative AI applications. It provides tools …
LastMile AI is an enterprise-grade developer platform for testing, evaluating, and monitoring generative AI applications. It provides tools like AutoEval for custom evaluator fine-tuning, synthetic data generation, and real-time monitoring to ensure AI systems are reliable and production-ready.
About Model Evaluation
Model Evaluation tools are specialized platforms designed to assess the performance, fairness, and robustness of machine learning models. They automate the calculation of key metrics like accuracy, precision, and recall, providing deep insights into a model's behavior. These tools are essential for data scientists and MLOps engineers to validate models before deployment, compare different versions, and ensure they meet business objectives and ethical standards. They bridge the critical gap between model training and reliable real-world application.
Core Features
- Performance Metrics Calculation: Automatically computes standard metrics (e.g., accuracy, F1-score, AUC-ROC) for classification, regression, and other tasks.
- Bias and Fairness Auditing: Identifies and quantifies biases related to demographic groups or other sensitive attributes in data and model predictions.
- Explainability & Interpretability: Generates visualizations and reports (like SHAP values) to explain why a model makes specific predictions.
- Model Comparison & Versioning: Systematically compares the performance of multiple models or different versions of the same model on a given dataset.
- Robustness Testing: Evaluates model performance against adversarial attacks, data drift, and edge cases to ensure reliability in production.
Use Cases
These tools are primarily used by data science teams, machine learning engineers, and MLOps professionals in sectors like technology, finance, and healthcare. For example, a financial institution uses them to validate a credit scoring model for fairness and accuracy, while a healthcare company assesses a diagnostic model's reliability on diverse patient data before clinical use.
How to Choose
When selecting a tool, consider its support for your model frameworks (e.g., TensorFlow, PyTorch), the breadth of evaluation metrics offered, and its integration capabilities with your MLOps pipeline. Also, evaluate its features for collaborative reporting, visualization, and its scalability for handling large datasets and complex models.
Model EvaluationUse Cases
Pre-Deployment Validation of a Fraud Detection Model
A fintech company's machine learning team uses an evaluation tool to rigorously test a new transaction fraud model before it goes live. They analyze the confusion matrix to fine-tune the model's threshold, balancing precision (minimizing false positives that block legitimate users) and recall (maximizing the capture of actual fraud). The tool helps them generate a comprehensive report for compliance and stakeholder approval, demonstrating the model's effectiveness and reliability on a holdout dataset.
Auditing an AI Hiring Tool for Fairness
An HR technology company uses a model evaluation platform to audit its resume-screening AI. The tool analyzes the model's predictions across different demographic groups (e.g., gender, ethnicity) protected by law. It quantifies fairness metrics like 'demographic parity' and 'equal opportunity'. If a bias is detected where the model favors one group over another, the team receives detailed insights to help them mitigate the bias, ensuring their product is equitable and compliant with anti-discrimination laws.
Comparing Customer Churn Prediction Models
A telecom company's data science team has trained three different models (e.g., Logistic Regression, Gradient Boosting, Neural Network) to predict customer churn. They use an evaluation tool to upload the predictions from all three models on the same test dataset. The platform generates side-by-side comparisons of AUC-ROC curves, F1-scores, and lift charts. This allows the team to objectively identify the best-performing model and present a data-driven recommendation to business leaders for deployment.
Monitoring for Model Drift in Production
An e-commerce company uses a model evaluation tool integrated into its MLOps pipeline to continuously monitor its product recommendation engine. The tool automatically compares the statistical distribution of incoming live data with the training data. If significant 'data drift' is detected (e.g., customer buying habits change seasonally), or if the model's accuracy drops below a set threshold ('concept drift'), the system triggers an alert for the ML team to investigate and potentially retrain the model, ensuring recommendations remain relevant.
Explaining Medical Image Classification Results
A healthcare AI startup develops a model to classify skin lesions from images as benign or malignant. To gain trust from clinicians, they use an evaluation tool with explainability features. For a given prediction, the tool generates a heatmap (like Grad-CAM) overlaying the original image, highlighting the pixels the model focused on to make its decision. This visual evidence helps doctors understand the model's reasoning, verify that it's looking at relevant features, and build confidence in using the AI as a diagnostic aid.
Stress-Testing a Self-Driving Car's Perception Model
An automotive company uses a specialized evaluation suite to test its perception models against edge cases and adversarial examples. This involves creating simulated scenarios with unusual weather conditions (e.g., heavy fog, snow), altered road signs, or unexpected obstacles. The tool measures the model's performance and robustness in these challenging situations, identifying potential failure points before the model is deployed in a physical vehicle. This rigorous testing is critical for ensuring the safety and reliability of autonomous driving systems.