OneNine
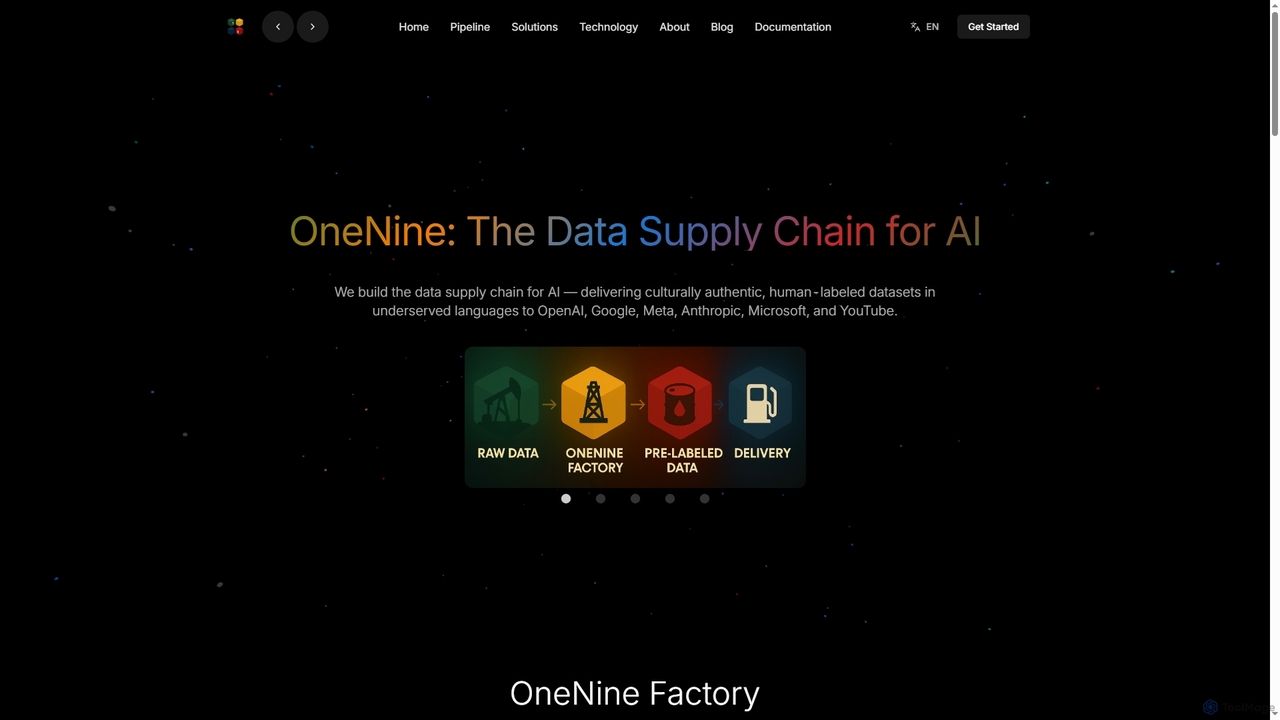
OneNine is the data supply chain for AI, specializing in delivering high-quality, culturally authentic, human-labeled datasets in underserved …
OneNine is the data supply chain for AI, specializing in delivering high-quality, culturally authentic, human-labeled datasets in underserved languages to leading AI companies. It bridges the linguistic gap, enabling more inclusive and accurate AI models globally.
About Audio Annotation
Audio Annotation tools are AI-powered solutions designed to label and categorize specific segments or features within audio data. These tools leverage advanced algorithms and human expertise to identify, transcribe, and tag various elements like speech, non-speech sounds, speaker identities, emotions, and acoustic events. Their primary value lies in preparing high-quality, structured audio datasets essential for training and evaluating machine learning models in fields such as speech recognition, natural language processing, and sound event detection.
Core Features
- Precise Time-stamping: Accurately marks the start and end times of specific audio events or speech segments.
- Speech Transcription: Converts spoken language into written text, often with speaker identification and timestamps.
- Speaker Diarization: Identifies and labels different speakers within an audio recording, indicating who spoke when.
- Sound Event Detection: Categorizes and tags specific non-speech sounds, such as environmental noises, music, or alerts.
- Emotion and Sentiment Tagging: Labels the emotional tone or sentiment expressed in spoken content, crucial for sentiment analysis.
Applicable Scenarios
Audio annotation is indispensable for AI researchers, data scientists, and product developers working with audio data. It's used in developing robust voice assistants, enhancing call center analytics by tagging customer interactions, and creating datasets for autonomous systems to understand environmental sounds. Content moderation platforms also rely on it to identify and flag inappropriate audio content efficiently.
How to Choose
When selecting an Audio Annotation tool, consider its annotation accuracy and support for various audio formats. Evaluate its collaboration features for team projects and scalability for large datasets. Look for robust API integrations with existing AI pipelines and assess its pricing model, whether per-hour or per-project, to match your budget and project scope.
Audio AnnotationUse Cases
Training Advanced Speech Recognition Models
Data scientists use audio annotation tools to precisely label speech segments, transcribe spoken words, and identify speaker turns in vast audio datasets. This meticulously annotated data is then fed into machine learning algorithms to train highly accurate Automatic Speech Recognition (ASR) systems, improving their ability to understand diverse accents and speaking styles.
Enhancing Voice Assistant Understanding
Developers leverage audio annotation to tag user commands, questions, and system responses within conversational audio. By accurately labeling intent, entities, and emotional cues, they can refine the Natural Language Understanding (NLU) capabilities of voice assistants, making them more responsive and context-aware in real-world interactions.
Automating Call Center Quality Assurance
Call center managers employ audio annotation to categorize specific events in customer service calls, such as customer complaints, agent empathy, or product inquiries. This allows for automated analysis of call trends, identification of training needs for agents, and monitoring of service quality without extensive manual review.
Developing Environmental Sound Awareness for Autonomous Vehicles
Engineers in autonomous driving projects use audio annotation to label critical environmental sounds like emergency vehicle sirens, car horns, or pedestrian warnings. This annotated data trains AI models to recognize and react appropriately to acoustic cues, enhancing the safety and situational awareness of self-driving cars.
Facilitating Medical Audio Diagnosis
Medical researchers and AI developers utilize audio annotation to precisely tag specific biological sounds, such as heart murmurs, lung crackles, or cough patterns, from patient recordings. This creates specialized datasets for training diagnostic AI tools, aiding in early detection and analysis of various medical conditions.
Streamlining Content Moderation for User-Generated Audio
Social media platforms and content providers use audio annotation to identify and label instances of hate speech, harassment, or other policy-violating content within user-uploaded audio or video streams. This enables AI-powered moderation systems to automatically flag and remove inappropriate content at scale, ensuring a safer online environment.