Oneinfer
Oneinferは、開発者向けの高性能AI推論プラットフォームです。GPT-4やClaudeなど15以上のLLMにアクセスするための統一APIを提供し、AIの統合を簡素化します。このプラットフォームは、サーバーレス展開、自動スケーリング、エンタープライズレベルのセキュリティ、従量課金制を特徴としています。また、カスタムAIワークロード用のGPUインスタンスをレンタルするマーケットプレイスも提供しています。
Oneinferは、開発者向けの高性能AI推論プラットフォームです。GPT-4やClaudeなど15以上のLLMにアクセスするための統一APIを提供し、AIの統合を簡素化します。このプラットフォームは、サーバーレス展開、自動スケーリング、エンタープライズレベルのセキュリティ、従量課金制を特徴としています。また、カスタムAIワークロード用のGPUインスタンスをレンタルするマーケットプレイスも提供しています。
Gmi Cloud
Gmi Cloudは、スケーラブルなAIトレーニングと推論のために設計された高性能GPUクラウドプラットフォームです。トップティアのNVIDIA GPUへのオンデマンドアクセス、低遅延のための最適化された推論エンジン、合理化されたMLOpsのためのクラスターエンジンを提供し、開発者や企業が効率的かつコスト効果的にAIアプリケーションを構築、展開、拡張できるようにします。
Gmi Cloudは、スケーラブルなAIトレーニングと推論のために設計された高性能GPUクラウドプラットフォームです。トップティアのNVIDIA GPUへのオンデマンドアクセス、低遅延のための最適化された推論エンジン、合理化されたMLOpsのためのクラスターエンジンを提供し、開発者や企業が効率的かつコスト効果的にAIアプリケーションを構築、展開、拡張できるようにします。

Baseten
Basetenは、AIモデルのデプロイ、スケーリング、管理を行うための本番環境グレードの推論プラットフォームです。高性能なランタイム、シームレスな開発者ワークフロー、柔軟なデプロイオプション(クラウド、セルフホスト、ハイブリッド)を提供します。ミッションクリティカルなAIアプリケーションを構築するエンジニアリングおよびMLチームに最適です。
Basetenは、AIモデルのデプロイ、スケーリング、管理を行うための本番環境グレードの推論プラットフォームです。高性能なランタイム、シームレスな開発者ワークフロー、柔軟なデプロイオプション(クラウド、セルフホスト、ハイブリッド)を提供します。ミッションクリティカルなAIアプリケーションを構築するエンジニアリングおよびMLチームに最適です。

BrainHost
BrainHostは、速度と信頼性のために設計された高性能KVM VPSホスティングをNVMeストレージと共に提供します。30秒のプロビジョニング、香港と米国西部のグローバルデータセンター、直感的なVirtFusionコントロールパネルを備え、ウェブサイト、eコマース、AI推論、ゲームアプリケーション向けの堅牢なインフラを提供します。柔軟なスケーリングと高度なネットワークルーティングにより、世界中で安定した高速アクセスを保証します。
BrainHostは、速度と信頼性のために設計された高性能KVM VPSホスティングをNVMeストレージと共に提供します。30秒のプロビジョニング、香港と米国西部のグローバルデータセンター、直感的なVirtFusionコントロールパネルを備え、ウェブサイト、eコマース、AI推論、ゲームアプリケーション向けの堅牢なインフラを提供します。柔軟なスケーリングと高度なネットワークルーティングにより、世界中で安定した高速アクセスを保証します。
UltiHash
UltiHashは、AIおよびビッグデータワークロード向けに特別に構築された、高性能なKubernetesネイティブのオブジェクトストレージプラットフォームです。高度なバイトレベルの重複排除により、超高速のデータアクセスと大幅なコスト削減を実現し、クラウド、オンプレミス、ハイブリッド環境での柔軟なデプロイをサポートします。S3互換APIにより、既存のデータスタックやAIワークフローとのシームレスな統合が保証されます。
UltiHashは、AIおよびビッグデータワークロード向けに特別に構築された、高性能なKubernetesネイティブのオブジェクトストレージプラットフォームです。高度なバイトレベルの重複排除により、超高速のデータアクセスと大幅なコスト削減を実現し、クラウド、オンプレミス、ハイブリッド環境での柔軟なデプロイをサポートします。S3互換APIにより、既存のデータスタックやAIワークフローとのシームレスな統合が保証されます。
Irisradgroup
irisradgroupは、道路および道路資産のメンテナンスを自動化するAI搭載のインフラテックソリューションです。特殊なカメラとインテリジェントなダッシュボードを使用し、自治体やインフラ管理者が道路状況の監視、資産の棚卸し、コンプライアンスの確保、公共の安全を効率的に向上させるのを支援します。
irisradgroupは、道路および道路資産のメンテナンスを自動化するAI搭載のインフラテックソリューションです。特殊なカメラとインテリジェントなダッシュボードを使用し、自治体やインフラ管理者が道路状況の監視、資産の棚卸し、コンプライアンスの確保、公共の安全を効率的に向上させるのを支援します。
Hewlett Packard Enterprise (HPE)
Hewlett Packard Enterprise (HPE)は、企業向けに包括的なAI、ハイブリッドクラウド、ネットワーキング、データソリューションを提供するグローバルなエッジからクラウドまでの企業です。HPE GreenLakeプラットフォーム、NVIDIAなどのリーダーとの戦略的パートナーシップ、堅牢なハードウェアとサービスのポートフォリオを通じて、HPEは組織がイノベーションを加速し、運用を最適化し、データを実用的な洞察に変えることを支援します。
Hewlett Packard Enterprise (HPE)は、企業向けに包括的なAI、ハイブリッドクラウド、ネットワーキング、データソリューションを提供するグローバルなエッジからクラウドまでの企業です。HPE GreenLakeプラットフォーム、NVIDIAなどのリーダーとの戦略的パートナーシップ、堅牢なハードウェアとサービスのポートフォリオを通じて、HPEは組織がイノベーションを加速し、運用を最適化し、データを実用的な洞察に変えることを支援します。

Ollama
Ollamaは、Llama 3、Mistral、Gemmaなどの大規模言語モデル(LLM)を自身のハードウェア上でローカルに実行するための強力なオープンソースフレームワークです。macOS、Windows、Linuxで利用可能で、オープンソースモデルのセットアップと管理を簡素化し、プライベートでオフライン、かつコスト効率の高いAI開発と利用を実現します。
Ollamaは、Llama 3、Mistral、Gemmaなどの大規模言語モデル(LLM)を自身のハードウェア上でローカルに実行するための強力なオープンソースフレームワークです。macOS、Windows、Linuxで利用可能で、オープンソースモデルのセットアップと管理を簡素化し、プライベートでオフライン、かつコスト効率の高いAI開発と利用を実現します。
HIVE Digital Technologies
HIVE Digital Technologiesは、持続可能なデータセンターインフラのグローバルリーダーであり、大規模なビットコインマイニングとAIアプリケーション向けのハイパフォーマンスコンピューティング(HPC)の提供を専門としています。HIVEはNVIDIA GPUのフリートを活用し、カナダ、スウェーデン、パラグアイにある地理的に多様なデータセンターからの効率的なグリーンエネルギーで革新的な技術を支えています。
HIVE Digital Technologiesは、持続可能なデータセンターインフラのグローバルリーダーであり、大規模なビットコインマイニングとAIアプリケーション向けのハイパフォーマンスコンピューティング(HPC)の提供を専門としています。HIVEはNVIDIA GPUのフリートを活用し、カナダ、スウェーデン、パラグアイにある地理的に多様なデータセンターからの効率的なグリーンエネルギーで革新的な技術を支えています。
Exa Laboratories
Exa Laboratories(現Zettascale)は、YCが出資するシリコンバレーのスタートアップで、AI向けの最先端でエネルギー効率の高い再構成可能チップ(XPU)を開発しています。そのポリモーフィック・コンピューティング・アーキテクチャは、従来のGPUやTPUよりも優れた性能、汎用性、効率性を提供し、AIのトレーニングと推論におけるエネルギー危機を解決することを目指しています。
Exa Laboratories(現Zettascale)は、YCが出資するシリコンバレーのスタートアップで、AI向けの最先端でエネルギー効率の高い再構成可能チップ(XPU)を開発しています。そのポリモーフィック・コンピューティング・アーキテクチャは、従来のGPUやTPUよりも優れた性能、汎用性、効率性を提供し、AIのトレーニングと推論におけるエネルギー危機を解決することを目指しています。
Arbius
Arbiusは、機械学習のための分散型ピアツーピアネットワークであり、AIコンピューティングのグローバルマーケットプレイスを創出します。モデル作成者が自身の作品を収益化し、ユーザーが検閲耐性のある環境でAIモデルにアクセスできるようにし、ネイティブトークンAIUSと「有用な仕事の証明」メカニズムによって支えられています。
Arbiusは、機械学習のための分散型ピアツーピアネットワークであり、AIコンピューティングのグローバルマーケットプレイスを創出します。モデル作成者が自身の作品を収益化し、ユーザーが検閲耐性のある環境でAIモデルにアクセスできるようにし、ネイティブトークンAIUSと「有用な仕事の証明」メカニズムによって支えられています。

Prediction Guard
Prediction Guardは、組織が自社のファイアウォール内で安全に大規模言語モデル(LLM)をデプロイ、管理、スケールさせるためのエンタープライズ向けAIプラットフォームです。オンプレミス、エアギャップ、プライベートクラウドなどの柔軟なデプロイオプションを提供し、完全なデータプライバシーと制御を保証します。OpenAI互換APIにより、LangChainやLlamaIndexなどの既存ツールやフレームワークとのシームレスな統合が可能で、医療、防衛、金融などの規制産業に最適です。
Prediction Guardは、組織が自社のファイアウォール内で安全に大規模言語モデル(LLM)をデプロイ、管理、スケールさせるためのエンタープライズ向けAIプラットフォームです。オンプレミス、エアギャップ、プライベートクラウドなどの柔軟なデプロイオプションを提供し、完全なデータプライバシーと制御を保証します。OpenAI互換APIにより、LangChainやLlamaIndexなどの既存ツールやフレームワークとのシームレスな統合が可能で、医療、防衛、金融などの規制産業に最適です。
Protocol Labs
Protocol Labsは、ネットワークプロトコルの研究、開発、展開を行うラボです。Web3、AI、分散型インフラに焦点を当て、コンピューティングのブレークスルーを推進しています。IPFSやFilecoinなどの基盤技術の創設者であり、600以上のスタートアップや組織からなるグローバルなイノベーションネットワークを育成し、より強靭でオープンなインターネットの構築を目指しています。
Protocol Labsは、ネットワークプロトコルの研究、開発、展開を行うラボです。Web3、AI、分散型インフラに焦点を当て、コンピューティングのブレークスルーを推進しています。IPFSやFilecoinなどの基盤技術の創設者であり、600以上のスタートアップや組織からなるグローバルなイノベーションネットワークを育成し、より強靭でオープンなインターネットの構築を目指しています。

Nebius
Nebiusは、要求の厳しいAIおよび機械学習ワークロード向けに特別に設計された高性能クラウドプラットフォームです。単一インスタンスから大規模クラスタまで、最新のNVIDIA GPUへのスケーラブルなアクセスを提供し、管理サービススイートと統合AI Studioによって、トレーニングから推論までのMLライフサイクル全体を合理化します。
Nebiusは、要求の厳しいAIおよび機械学習ワークロード向けに特別に設計された高性能クラウドプラットフォームです。単一インスタンスから大規模クラスタまで、最新のNVIDIA GPUへのスケーラブルなアクセスを提供し、管理サービススイートと統合AI Studioによって、トレーニングから推論までのMLライフサイクル全体を合理化します。
StackSpaces
StackSpacesは、開発者がフルスタックAIアプリケーションを簡単に構築、デプロイ、スケーリングできるように設計された統合開発プラットフォームです。バックエンド、フロントエンド、インフラストラクチャコンポーネントを含む統一された環境を提供し、アイデアから本番までの開発ライフサイクル全体を合理化します。
StackSpacesは、開発者がフルスタックAIアプリケーションを簡単に構築、デプロイ、スケーリングできるように設計された統合開発プラットフォームです。バックエンド、フロントエンド、インフラストラクチャコンポーネントを含む統一された環境を提供し、アイデアから本番までの開発ライフサイクル全体を合理化します。
Substrate
Substrateは、高性能なエージェント型AIアプリケーションを構築するための開発者プラットフォームです。洗練されたSDK、最適化されたモデルの包括的なライブラリ、そして複雑なマルチステップAIワークフローを調整して速度と効率を最大化する独自のコンピュートエンジンを提供します。
Substrateは、高性能なエージェント型AIアプリケーションを構築するための開発者プラットフォームです。洗練されたSDK、最適化されたモデルの包括的なライブラリ、そして複雑なマルチステップAIワークフローを調整して速度と効率を最大化する独自のコンピュートエンジンを提供します。
ClawCloud Run
ClawCloud Runは、アプリケーションのライフサイクルを簡素化するために設計されたクラウドネイティブな開発プラットフォームです。開発者は複雑なYAMLファイルを書くことなく、統一されたクラウド環境でアプリケーションを構築、デプロイ、管理、実行できます。ビジュアルキャンバス、ワンクリックテンプレート、統合されたデータベース管理を特徴とし、市場投入までの時間を短縮します。
ClawCloud Runは、アプリケーションのライフサイクルを簡素化するために設計されたクラウドネイティブな開発プラットフォームです。開発者は複雑なYAMLファイルを書くことなく、統一されたクラウド環境でアプリケーションを構築、デプロイ、管理、実行できます。ビジュアルキャンバス、ワンクリックテンプレート、統合されたデータベース管理を特徴とし、市場投入までの時間を短縮します。
DistributeAI
DistributeAIは、開発者にスケーラブルで低コストのオープンソースAIモデルの広範なライブラリへのアクセスを提供する分散型AIスーパーコンピュータプラットフォームです。開発者フレンドリーなAPIとSDKを通じてAIアプリケーションの構築と展開を可能にし、ユーザーがアイドル状態のコンピューティングパワーを提供して収益化することもできます。
DistributeAIは、開発者にスケーラブルで低コストのオープンソースAIモデルの広範なライブラリへのアクセスを提供する分散型AIスーパーコンピュータプラットフォームです。開発者フレンドリーなAPIとSDKを通じてAIアプリケーションの構築と展開を可能にし、ユーザーがアイドル状態のコンピューティングパワーを提供して収益化することもできます。
Fastly
Fastlyは、高速でスケーラブルなデジタル体験を構築、保護、配信するために設計された、最先端のエッジクラウドプラットフォームです。最新のCDN、次世代WAFなどの堅牢なセキュリティ機能、強力なサーバーレスコンピューティング環境を組み合わせています。Fastlyは、企業がパフォーマンスを向上させ、セキュリティを強化し、ユーザーに近い場所で革新を起こすのを支援し、eコマース、ストリーミング、AI搭載アプリケーション向けの特定のソリューションを提供します。
Fastlyは、高速でスケーラブルなデジタル体験を構築、保護、配信するために設計された、最先端のエッジクラウドプラットフォームです。最新のCDN、次世代WAFなどの堅牢なセキュリティ機能、強力なサーバーレスコンピューティング環境を組み合わせています。Fastlyは、企業がパフォーマンスを向上させ、セキュリティを強化し、ユーザーに近い場所で革新を起こすのを支援し、eコマース、ストリーミング、AI搭載アプリケーション向けの特定のソリューションを提供します。
Forefront
Forefrontは、開発者向けのオープンソースAI構築プラットフォームです。プライベートデータ上で大規模言語モデル(LLM)の実行、ファインチューニング、デプロイを簡素化し、クローズドソースプラットフォームに代わるスケーラブルで安全、かつコスト効率の高い選択肢を提供します。あなたのデータ、モデル、AIを所有しましょう。
Forefrontは、開発者向けのオープンソースAI構築プラットフォームです。プライベートデータ上で大規模言語モデル(LLM)の実行、ファインチューニング、デプロイを簡素化し、クローズドソースプラットフォームに代わるスケーラブルで安全、かつコスト効率の高い選択肢を提供します。あなたのデータ、モデル、AIを所有しましょう。

Currux Vision
Currux Visionは、スマートインフラ向けの自律型AIシステムを提供し、特に高度道路交通システム(ITS)を専門としています。既存のCCTVカメラを活用して、リアルタイムの交通監視、違反検出、データ分析を行います。このプラットフォームは、高度なコンピュータビジョンとエッジコンピューティングを通じて、都市や政府機関が交通フローを改善し、安全性を高め、インフラ管理を最適化するのを支援します。
Currux Visionは、スマートインフラ向けの自律型AIシステムを提供し、特に高度道路交通システム(ITS)を専門としています。既存のCCTVカメラを活用して、リアルタイムの交通監視、違反検出、データ分析を行います。このプラットフォームは、高度なコンピュータビジョンとエッジコンピューティングを通じて、都市や政府機関が交通フローを改善し、安全性を高め、インフラ管理を最適化するのを支援します。
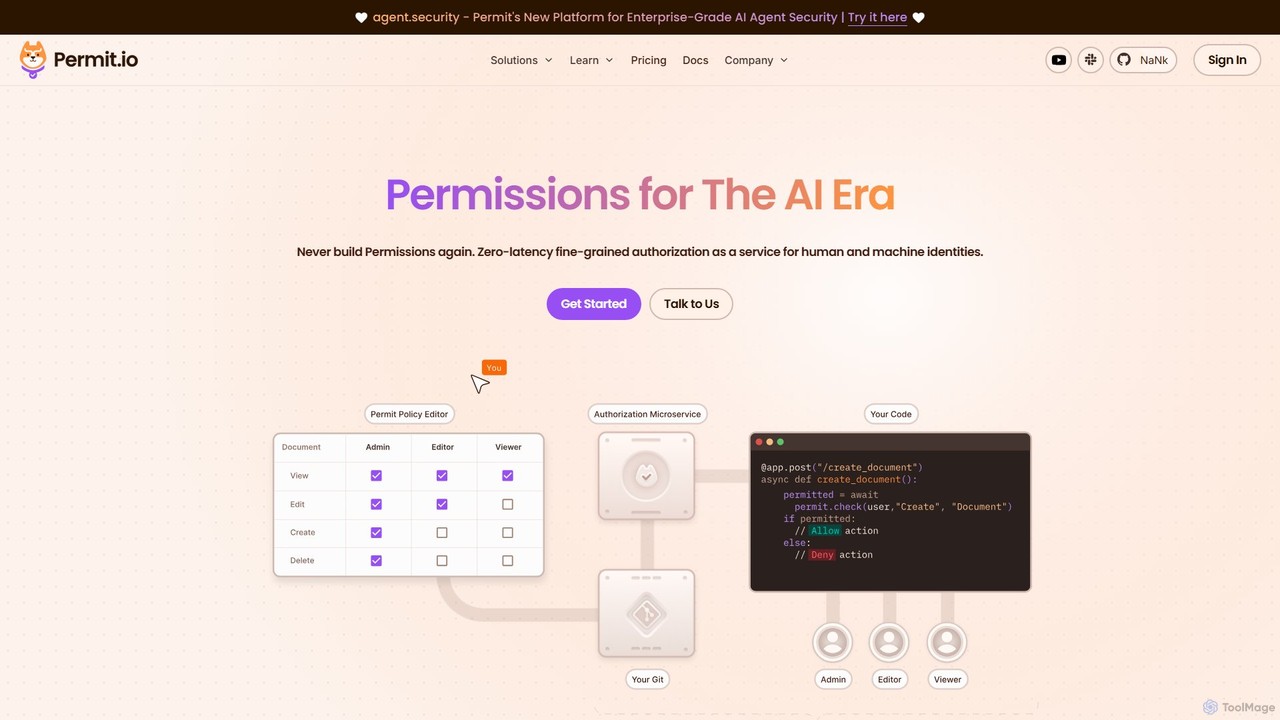
Permit.io
Permit.ioは、AI時代のために設計されたフルスタック認可プラットフォームです。開発者向けにRBAC、ABAC、ReBACといった複雑なアクセス制御の実装を簡素化します。ノーコードのポリシーエディタ、GitOps統合、埋め込み可能なUIコンポーネントにより、チーム全体で安全かつ効率的に権限を管理できます。このプラットフォームはハイブリッドモデルで動作し、低遅延の意思決定を保証し、機密データをネットワーク内に保持しながら、AIエージェントを搭載した最新のアプリケーションに堅牢なコンプライアンスとスケーラビリティを提供します。
Permit.ioは、AI時代のために設計されたフルスタック認可プラットフォームです。開発者向けにRBAC、ABAC、ReBACといった複雑なアクセス制御の実装を簡素化します。ノーコードのポリシーエディタ、GitOps統合、埋め込み可能なUIコンポーネントにより、チーム全体で安全かつ効率的に権限を管理できます。このプラットフォームはハイブリッドモデルで動作し、低遅延の意思決定を保証し、機密データをネットワーク内に保持しながら、AIエージェントを搭載した最新のアプリケーションに堅牢なコンプライアンスとスケーラビリティを提供します。
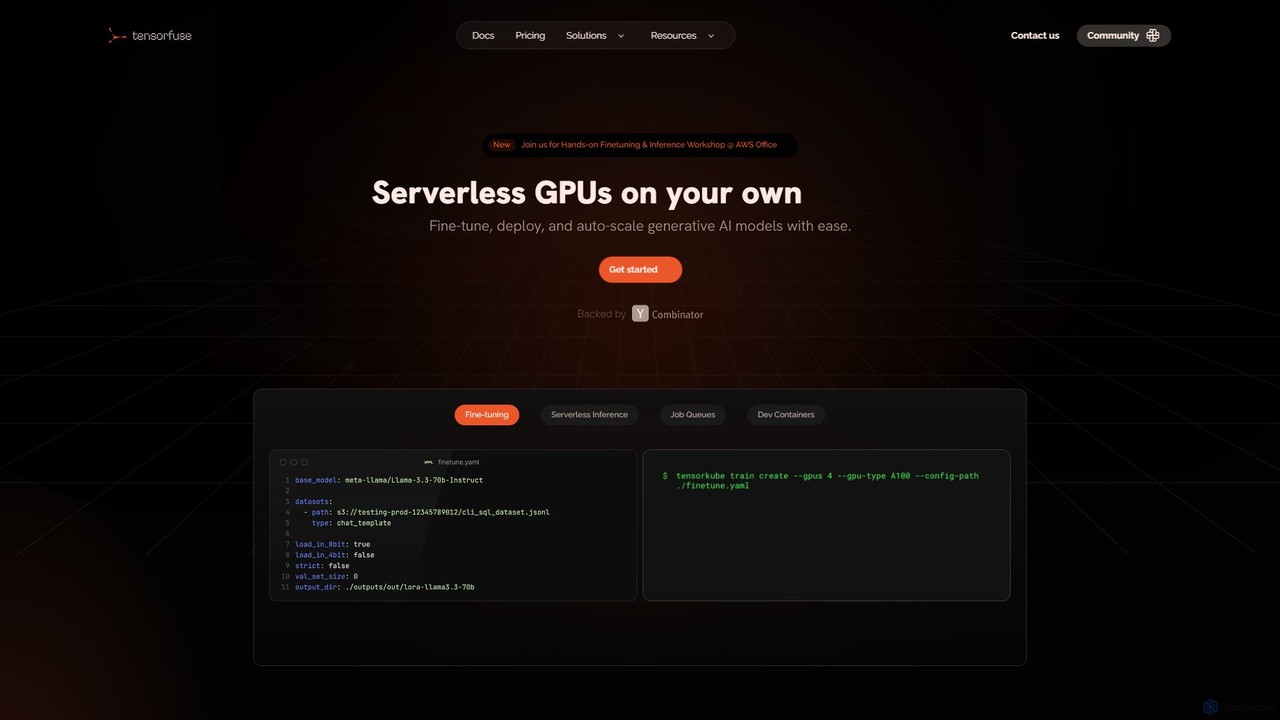
Tensorfuse
Tensorfuseは、開発者が自身のAWSクラウド上で生成AIモデルのファインチューニング、デプロイ、オートスケーリングを行えるようにするサーバーレスGPUプラットフォームです。インフラ管理を簡素化し、サーバーレス推論、ジョブキュー、開発コンテナなどの機能を提供して、開発を加速し、コストを削減し、DevOpsのオーバーヘッドをなくします。
Tensorfuseは、開発者が自身のAWSクラウド上で生成AIモデルのファインチューニング、デプロイ、オートスケーリングを行えるようにするサーバーレスGPUプラットフォームです。インフラ管理を簡素化し、サーバーレス推論、ジョブキュー、開発コンテナなどの機能を提供して、開発を加速し、コストを削減し、DevOpsのオーバーヘッドをなくします。

Cortex Labs
Cortex Labsは、AIモデルとAI搭載dAppをオンチェーンで直接実行するために設計された、分散型のオープンソース・パブリックブロックチェーンです。効率的なAI推論のためのCortex Virtual Machine(CVM)と、スケーラビリティのためのZkRollup Layer 2ソリューションであるZkMatrixを特徴としています。開発者がスマートコントラクト内でAIモデルを構築、共有、収益化できるエコシステムを創出し、AIの民主化を目指しています。
Cortex Labsは、AIモデルとAI搭載dAppをオンチェーンで直接実行するために設計された、分散型のオープンソース・パブリックブロックチェーンです。効率的なAI推論のためのCortex Virtual Machine(CVM)と、スケーラビリティのためのZkRollup Layer 2ソリューションであるZkMatrixを特徴としています。開発者がスマートコントラクト内でAIモデルを構築、共有、収益化できるエコシステムを創出し、AIの民主化を目指しています。


PowerSpect
PowerSpectは、インフラ点検を簡素化・自動化するAI搭載プラットフォームです。高度なコンピュータビジョン、3Dモデリング、予測分析を活用して画像やセンサーデータを分析します。エネルギーや公益事業などの業界向けに設計されており、潜在的な問題を検出し、メンテナンスの必要性を予測し、送電鉄塔などの重要資産の安全性と信頼性を確保します。
PowerSpectは、インフラ点検を簡素化・自動化するAI搭載プラットフォームです。高度なコンピュータビジョン、3Dモデリング、予測分析を活用して画像やセンサーデータを分析します。エネルギーや公益事業などの業界向けに設計されており、潜在的な問題を検出し、メンテナンスの必要性を予測し、送電鉄塔などの重要資産の安全性と信頼性を確保します。
DigitalOcean
DigitalOceanは、開発者向けのクラウドインフラプラットフォームで、アプリケーションの構築、デプロイ、スケーリングを簡素化します。仮想マシン(Droplets)、マネージドKubernetes、GradientAIプラットフォームなど、包括的な製品スイートを提供し、サイドプロジェクトから大規模ビジネスまで、世界を変えるAIアプリケーションの作成とホスティングのための強力なGPUリソースとツールを提供します。
DigitalOceanは、開発者向けのクラウドインフラプラットフォームで、アプリケーションの構築、デプロイ、スケーリングを簡素化します。仮想マシン(Droplets)、マネージドKubernetes、GradientAIプラットフォームなど、包括的な製品スイートを提供し、サイドプロジェクトから大規模ビジネスまで、世界を変えるAIアプリケーションの作成とホスティングのための強力なGPUリソースとツールを提供します。
NVIDIA Build
NVIDIA Buildは、開発者や企業が本番環境対応の生成AIモデルを発見、カスタマイズ、デプロイするための包括的なプラットフォームです。最適化されたモデルの広範なカタログ、高性能推論のためのNVIDIA NIMマイクロサービス、開発を加速するアプリケーションブループリントを特徴としています。
NVIDIA Buildは、開発者や企業が本番環境対応の生成AIモデルを発見、カスタマイズ、デプロイするための包括的なプラットフォームです。最適化されたモデルの広範なカタログ、高性能推論のためのNVIDIA NIMマイクロサービス、開発を加速するアプリケーションブループリントを特徴としています。

Vast.ai
Vast.aiは、AIおよび機械学習ワークロード向けに広大なGPUネットワークへのオンデマンドアクセスを提供する、主要なGPUクラウドプラットフォームです。透明性の高い従量課金制のマーケットプレイスを通じて、従来のクラウドプロバイダーよりも最大80%安いコストで、開発者や企業に高性能コンピューティングを提供します。
Vast.aiは、AIおよび機械学習ワークロード向けに広大なGPUネットワークへのオンデマンドアクセスを提供する、主要なGPUクラウドプラットフォームです。透明性の高い従量課金制のマーケットプレイスを通じて、従来のクラウドプロバイダーよりも最大80%安いコストで、開発者や企業に高性能コンピューティングを提供します。

thundercompute
Thunder Computeは、AIおよび機械学習開発者向けに設計された超低コストのGPUクラウドプラットフォームです。NVIDIA A100やT4などのオンデマンドGPUインスタンスを、主要なクラウドプロバイダーより最大80%安い価格で提供します。ワンクリック設定、VS Code統合、シームレスなスケーラビリティといった機能により、プロトタイピングから本番環境までの開発ワークフローを劇的に簡素化し、開発者がインフラ管理ではなくモデル構築に集中できるようにします。
Thunder Computeは、AIおよび機械学習開発者向けに設計された超低コストのGPUクラウドプラットフォームです。NVIDIA A100やT4などのオンデマンドGPUインスタンスを、主要なクラウドプロバイダーより最大80%安い価格で提供します。ワンクリック設定、VS Code統合、シームレスなスケーラビリティといった機能により、プロトタイピングから本番環境までの開発ワークフローを劇的に簡素化し、開発者がインフラ管理ではなくモデル構築に集中できるようにします。

Inferless
Inferlessは、開発者が数分で機械学習モデルをデプロイできるように設計されたサーバーレスGPUプラットフォームです。インフラ管理を不要にし、急増するワークロードに対応するためにゼロからの自動スケーリングを提供します。このプラットフォームは、超高速のコールドスタートとコスト効率に最適化されており、ユーザーは使用した分だけを支払い、GPU費用を最大90%節約できます。
Inferlessは、開発者が数分で機械学習モデルをデプロイできるように設計されたサーバーレスGPUプラットフォームです。インフラ管理を不要にし、急増するワークロードに対応するためにゼロからの自動スケーリングを提供します。このプラットフォームは、超高速のコールドスタートとコスト効率に最適化されており、ユーザーは使用した分だけを支払い、GPU費用を最大90%節約できます。

massedcompute
Massed Computeは、オンデマンドで高性能なNVIDIA GPUとCPUを提供するクラウドプラットフォームです。AI開発、機械学習、ビッグデータ分析向けに、長期契約なしで柔軟かつスケーラブルで手頃なコンピューティングパワーを提供し、イノベーターや開発者を対象としています。
Massed Computeは、オンデマンドで高性能なNVIDIA GPUとCPUを提供するクラウドプラットフォームです。AI開発、機械学習、ビッグデータ分析向けに、長期契約なしで柔軟かつスケーラブルで手頃なコンピューティングパワーを提供し、イノベーターや開発者を対象としています。

Predibase
Predibaseは、オープンソースの大規模言語モデル(LLM)を効率的にファインチューニングし、サービングするためのエンドツーエンドの開発者プラットフォームです。ユーザーが特定のタスクでGPT-4のような大規模なプロプライエタリモデルを上回るカスタムAIモデルを構築し、コストと推論レイテンシを大幅に削減することを可能にします。このプラットフォームは、強化学習ファインチューニング(RFT)やLoRAXなどの高度な技術を特徴とし、高速なマルチモデルサービングを実現します。
Predibaseは、オープンソースの大規模言語モデル(LLM)を効率的にファインチューニングし、サービングするためのエンドツーエンドの開発者プラットフォームです。ユーザーが特定のタスクでGPT-4のような大規模なプロプライエタリモデルを上回るカスタムAIモデルを構築し、コストと推論レイテンシを大幅に削減することを可能にします。このプラットフォームは、強化学習ファインチューニング(RFT)やLoRAXなどの高度な技術を特徴とし、高速なマルチモデルサービングを実現します。
Zeabur
Zeaburは開発者向けに設計されたAI搭載のデプロイメントプラットフォーム(PaaS)です。フロントエンド、バックエンド、データベース、AIエージェントを含むあらゆるプロジェクトを、コードから直接、または対話型AIを通じてワンクリックでデプロイできます。従量課金制、自動構成、オートスケーリングを特徴とし、Zeaburはクラウドインフラを簡素化し、開発者がコーディングに専念できるようにします。
Zeaburは開発者向けに設計されたAI搭載のデプロイメントプラットフォーム(PaaS)です。フロントエンド、バックエンド、データベース、AIエージェントを含むあらゆるプロジェクトを、コードから直接、または対話型AIを通じてワンクリックでデプロイできます。従量課金制、自動構成、オートスケーリングを特徴とし、Zeaburはクラウドインフラを簡素化し、開発者がコーディングに専念できるようにします。

Heurist AI
Heurist AIは、オンチェーン経済向けに設計されたフルスタックの分散型AIインフラストラクチャです。開発者に多数のAIモデルにアクセスするための統一APIと、コンポーザブルなAIエージェントを構築するためのフレームワークを提供します。分散型物理インフラネットワーク(DePIN)を活用し、HeuristはGPUプロバイダーとAI開発者を結びつけ、AIコンピューティングへのアクセスを民主化し、Web3分野のイノベーションを促進することを目指しています。
Heurist AIは、オンチェーン経済向けに設計されたフルスタックの分散型AIインフラストラクチャです。開発者に多数のAIモデルにアクセスするための統一APIと、コンポーザブルなAIエージェントを構築するためのフレームワークを提供します。分散型物理インフラネットワーク(DePIN)を活用し、HeuristはGPUプロバイダーとAI開発者を結びつけ、AIコンピューティングへのアクセスを民主化し、Web3分野のイノベーションを促進することを目指しています。

PPIO
PPIOは、コスト効率が高く高性能なAIコンピューティングパワー、モデルAPI、エッジコンピューティングサービスを提供する、主要な分散型クラウドコンピューティングプラットフォームです。開発者や企業向けに、AI、ビデオ、メタバースアプリケーションのためのワンストップソリューションを提供し、サーバーレスGPU、コンテナ化インスタンス、人気のLLMやマルチモーダルモデルへのアクセスを特徴としています。
PPIOは、コスト効率が高く高性能なAIコンピューティングパワー、モデルAPI、エッジコンピューティングサービスを提供する、主要な分散型クラウドコンピューティングプラットフォームです。開発者や企業向けに、AI、ビデオ、メタバースアプリケーションのためのワンストップソリューションを提供し、サーバーレスGPU、コンテナ化インスタンス、人気のLLMやマルチモーダルモデルへのアクセスを特徴としています。
Fireworks AI
開発者が生成AIアプリケーションを構築、カスタマイズ、スケールさせるための高性能プラットフォームです。業界をリードする高速推論エンジン、高度なファインチューニング機能、幅広いオープンソースモデルへのアクセスを提供し、リアルタイムでコスト効率の高いAIソリューションを実現します。
開発者が生成AIアプリケーションを構築、カスタマイズ、スケールさせるための高性能プラットフォームです。業界をリードする高速推論エンジン、高度なファインチューニング機能、幅広いオープンソースモデルへのアクセスを提供し、リアルタイムでコスト効率の高いAIソリューションを実現します。
Spheron
Spheronは、AI/MLワークロード向けにスケーラブルでコスト効率の高い計算能力を提供する分散型GPUネットワーク(DePIN)です。ゲーミングPC、データセンター、マイニングファームからのアイドルリソースを集約し、従来のクラウドプロバイダーよりも最大80%安価で、耐障害性と検閲耐性を備えた代替手段を提供します。
Spheronは、AI/MLワークロード向けにスケーラブルでコスト効率の高い計算能力を提供する分散型GPUネットワーク(DePIN)です。ゲーミングPC、データセンター、マイニングファームからのアイドルリソースを集約し、従来のクラウドプロバイダーよりも最大80%安価で、耐障害性と検閲耐性を備えた代替手段を提供します。
HyperAI
HyperAIは、エンタープライズグレードのAIコンピューティングを誰もが利用できるように設計された、ヨーロッパを拠点とするハイパーローカルGPUクラウドプラットフォームです。スポットインスタンスや専用サーバーなどの柔軟なプランを通じて、高性能なNVIDIA A100およびH100 GPUを提供します。低遅延、データコンプライアンス、そしてプリインストールされたNvidia AI SDKを備えた開発者フレンドリーな環境に重点を置き、開発者や企業が複雑なAIモデルを効率的かつ安全に構築、トレーニング、デプロイできるよう支援します。
HyperAIは、エンタープライズグレードのAIコンピューティングを誰もが利用できるように設計された、ヨーロッパを拠点とするハイパーローカルGPUクラウドプラットフォームです。スポットインスタンスや専用サーバーなどの柔軟なプランを通じて、高性能なNVIDIA A100およびH100 GPUを提供します。低遅延、データコンプライアンス、そしてプリインストールされたNvidia AI SDKを備えた開発者フレンドリーな環境に重点を置き、開発者や企業が複雑なAIモデルを効率的かつ安全に構築、トレーニング、デプロイできるよう支援します。
ClearML GenAI App Engine
生成AIアプリケーションを迅速にデプロイ、管理、スケーリングするためのエンタープライズ向けプラットフォームです。統一されたインフラ制御プレーンを提供し、LLMのデプロイを合理化し、パフォーマンスを監視し、コンピューティングコストを最適化することで、生成AIの導入を安全かつ効率的に加速します。
生成AIアプリケーションを迅速にデプロイ、管理、スケーリングするためのエンタープライズ向けプラットフォームです。統一されたインフラ制御プレーンを提供し、LLMのデプロイを合理化し、パフォーマンスを監視し、コンピューティングコストを最適化することで、生成AIの導入を安全かつ効率的に加速します。
Google Cloud
Google Cloudは、インフラストラクチャ、プラットフォーム、サーバーレス環境を提供する包括的なクラウドコンピューティングサービスのスイートです。Vertex AIとGeminiによるAI/ML、BigQueryによるデータ分析に優れ、スタートアップからグローバル企業まで、あらゆる規模のビジネス向けにスケーラブルで安全なインフラストラクチャを提供します。
Google Cloudは、インフラストラクチャ、プラットフォーム、サーバーレス環境を提供する包括的なクラウドコンピューティングサービスのスイートです。Vertex AIとGeminiによるAI/ML、BigQueryによるデータ分析に優れ、スタートアップからグローバル企業まで、あらゆる規模のビジネス向けにスケーラブルで安全なインフラストラクチャを提供します。
Cirrascale Cloud Services
Cirrascaleは、大規模AI、ディープラーニング、およびハイパフォーマンスコンピューティング(HPC)向けに特化した高性能な専用GPUクラウドサービスを提供します。最新のNVIDIA GPUハードウェアとスケーラブルなインフラストラクチャへのアクセスを提供し、組織が巨大なモデルを効率的にトレーニングし、複雑な計算ワークロードを実行できるようにします。
Cirrascaleは、大規模AI、ディープラーニング、およびハイパフォーマンスコンピューティング(HPC)向けに特化した高性能な専用GPUクラウドサービスを提供します。最新のNVIDIA GPUハードウェアとスケーラブルなインフラストラクチャへのアクセスを提供し、組織が巨大なモデルを効率的にトレーニングし、複雑な計算ワークロードを実行できるようにします。
Clore.ai
Clore.aiは、高性能コンピューティングリソースのグローバルネットワークへのオンデマンドアクセスを提供する分散型GPUマーケットプレイスです。AIトレーニング、3Dレンダリング、科学シミュレーションなどのタスクにGPUパワーを必要とするユーザーと、アイドル状態のサーバーを収益化したいハードウェア所有者を結びつけます。このプラットフォームは、柔軟なレンタル市場、取引用の独自の暗号通貨(CLORE)、報酬と割引を強化する独自のProof-of-Holding(POH)システムを特徴とし、高性能コンピューティングのための包括的なエコシステムを構築しています。
Clore.aiは、高性能コンピューティングリソースのグローバルネットワークへのオンデマンドアクセスを提供する分散型GPUマーケットプレイスです。AIトレーニング、3Dレンダリング、科学シミュレーションなどのタスクにGPUパワーを必要とするユーザーと、アイドル状態のサーバーを収益化したいハードウェア所有者を結びつけます。このプラットフォームは、柔軟なレンタル市場、取引用の独自の暗号通貨(CLORE)、報酬と割引を強化する独自のProof-of-Holding(POH)システムを特徴とし、高性能コンピューティングのための包括的なエコシステムを構築しています。

aistudio
aistudioは、BaiduのPaddlePaddleディープラーニングプラットフォームを搭載した、オールインワンのAI学習・開発コミュニティです。開発者に無料のオンラインプログラミング環境、GPUコンピューティングパワー、豊富なオープンソースモデル、データセットを提供し、AIアプリケーションのシームレスな構築、トレーニング、デプロイを支援します。
aistudioは、BaiduのPaddlePaddleディープラーニングプラットフォームを搭載した、オールインワンのAI学習・開発コミュニティです。開発者に無料のオンラインプログラミング環境、GPUコンピューティングパワー、豊富なオープンソースモデル、データセットを提供し、AIアプリケーションのシームレスな構築、トレーニング、デプロイを支援します。
Salad
Saladは、世界中のコンシューマーPCネットワークの未使用の計算能力を活用する分散型GPUクラウドプラットフォームです。AI/MLワークロード、モデルトレーニング、推論のために、非常に手頃でスケーラブルなオンデマンドGPUリソースを企業に提供し、従来のクラウドプロバイダーと比較して計算コストを最大90%削減します。
Saladは、世界中のコンシューマーPCネットワークの未使用の計算能力を活用する分散型GPUクラウドプラットフォームです。AI/MLワークロード、モデルトレーニング、推論のために、非常に手頃でスケーラブルなオンデマンドGPUリソースを企業に提供し、従来のクラウドプロバイダーと比較して計算コストを最大90%削減します。
Juice
Juiceは、GPU-over-IPを実現するソフトウェアのみのプラットフォームで、あらゆる標準ネットワークを介してGPUリソースにアクセス、共有、プールすることができます。GPUを物理マシンから切り離し、任意のCPUノードをオンデマンドでGPUアクセラレーションシステムに変えることで、コード変更なしで利用率を最適化し、AIやグラフィックスのワークロードコストを大幅に削減します。
Juiceは、GPU-over-IPを実現するソフトウェアのみのプラットフォームで、あらゆる標準ネットワークを介してGPUリソースにアクセス、共有、プールすることができます。GPUを物理マシンから切り離し、任意のCPUノードをオンデマンドでGPUアクセラレーションシステムに変えることで、コード変更なしで利用率を最適化し、AIやグラフィックスのワークロードコストを大幅に削減します。
Not Diamond
Not Diamondは、開発者向けのインテリジェントなマルチモデル・インフラストラクチャです。予測モデルルーティングと自動プロンプト適応機能を使用し、特定のタスクに最適な大規模言語モデル(LLM)を動的に選択することで、チームの開発を加速し、AIの精度を向上させ、コストを最適化します。
Not Diamondは、開発者向けのインテリジェントなマルチモデル・インフラストラクチャです。予測モデルルーティングと自動プロンプト適応機能を使用し、特定のタスクに最適な大規模言語モデル(LLM)を動的に選択することで、チームの開発を加速し、AIの精度を向上させ、コストを最適化します。
Supabase
Supabaseは、Postgres上に構築された完全なバックエンドソリューションを提供する、オープンソースのFirebase代替品です。データベース、認証、インスタントAPI、エッジ関数、リアルタイムサブスクリプション、ストレージ、ベクトル埋め込みなどのツール群を提供し、プロトタイプから本番までのアプリケーション開発を加速させます。
Supabaseは、Postgres上に構築された完全なバックエンドソリューションを提供する、オープンソースのFirebase代替品です。データベース、認証、インスタントAPI、エッジ関数、リアルタイムサブスクリプション、ストレージ、ベクトル埋め込みなどのツール群を提供し、プロトタイプから本番までのアプリケーション開発を加速させます。
インフラについて
AIインフラは、人工知能モデルの構築、トレーニング、デプロイに必要な基盤となるプラットフォーム、サービス、ハードウェアを提供します。これらのツールは、GPUやTPUなどのスケーラブルな計算リソースと、機械学習のライフサイクル全体を管理するための専用ソフトウェアを提供します。大規模なデータセットや複雑な計算を扱う開発者や組織にとって不可欠であり、カスタムAIソリューションの大規模な作成を可能にします。このインフラはハードウェア管理の複雑さを抽象化し、チームがモデル開発とイノベーションに集中できるようにします。
主な機能
- スケーラブルな計算リソース:モデルのトレーニングと推論を高速化するための強力なGPUおよびTPUへのオンデマンドアクセス。
- モデルのデプロイとホスティング:自動スケーリングと監視機能を備えた本番環境にモデルをデプロイするためのマネージドサービスとAPI。
- MLOpsプラットフォーム:データ準備からデプロイまで、エンドツーエンドの機械学習ライフサイクルを自動化および管理するための統合ツールチェーン。
- 最適化されたデータストレージ:AIトレーニングで使用される大規模データセット向けに設計された高性能ストレージソリューション。
- 開発環境:AI開発に必要なフレームワークやライブラリが事前設定された開発環境。
利用シーン
AIインフラは、独自のAI能力を構築するテクノロジー企業、研究機関、および企業にとって非常に重要です。大規模言語モデル(LLM)のトレーニング、産業オートメーション向けのコンピュータビジョンシステムの開発、Eコマースプラットフォーム向けのリアルタイム推薦エンジンのデプロイなどに使用されます。データサイエンスチームは、複雑な実験追跡やモデルのバージョン管理にこれを活用します。
選択のポイント
AIインフラを選択する際は、必要なGPUの種類や数など、特定の計算ニーズを考慮してください。プラットフォームのスケーラビリティと、変動するワークロードを処理する能力を評価します。ワークフローを合理化するために、MLOpsツールの包括性を評価します。最後に、予算と利用パターンに合わせて、従量課金制、リザーブドインスタンス、またはサーバーレスといった価格モデルを分析します。
厳選ツールランキング
最も人気
月間最高トラフィック順
最もインタラクティブ
最低離脱率順
ユーザーエンゲージメントが最も高い
平均滞在時間順
インフラ利用シーン
カスタム大規模言語モデルのトレーニング
研究室やAIスタートアップが、独自のデータセットで大規模言語モデル(LLM)をトレーニングする必要があります。彼らはAIインフラプロバイダーを利用して、数百の高性能GPUからなるクラスターにアクセスします。これにより、分散トレーニングを効率的に実行でき、トレーニング時間を数ヶ月から数週間に短縮します。プラットフォームの事前構成済み環境とデータストレージソリューションがセットアッププロセスを簡素化し、研究者はハードウェア管理ではなく、モデルアーキテクチャと実験に集中できます。
リアルタイム推論APIのデプロイ
Eコマース企業が、リアルタイムの商品推薦のための機械学習モデルをデプロイしたいと考えています。彼らはAIインフラプロバイダーのマネージドモデルホスティングサービスを利用します。このサービスは、セールイベント中のトラフィック急増を自動的に処理するスケーラブルなAPIエンドポイントを提供します。組み込みの監視ツールにより、運用チームはレイテンシやエラー率を追跡し、スムーズなユーザーエクスペリエンスを確保できます。マネージドサービスを利用することで、同社は独自のサービングインフラをセットアップし維持する複雑さを回避できます。
エンドツーエンドのMLOpsワークフローの管理
企業のデータサイエンスチームが、本番環境で数十のモデルを管理しています。彼らはMLOpsプラットフォームを導入して、ワークフロー全体を合理化します。このプラットフォームは、データバージョニング、実験追跡、モデルレジストリのためのツールを提供します。これにより、すべてのモデルに対して再現可能で監査可能な追跡が作成されます。彼らのCI/CDパイプラインはプラットフォームと統合されており、新しいモデルバージョンのテスト、検証、デプロイのプロセスを自動化し、手動エラーを大幅に削減し、新しいAI機能の市場投入までの時間を短縮します。
APIを介した基盤モデルのファインチューニング
ある開発者が、法律業界向けの専門的なチャットボットを構築しています。モデルをゼロからトレーニングする代わりに、インフラプロバイダーのサーバーレスAPIを使用して、大規模な基盤モデルをファインチューニングします。彼らは、厳選された小規模な法律関連のQ&Aデータセットをサービスにアップロードします。プラットフォームは、そのマネージドインフラ上でファインチューニングプロセス全体を処理します。完了すると、開発者はカスタマイズされたモデル用のプライベートAPIエンドポイントへのアクセスを取得し、サーバーを管理することなくアプリケーションに簡単に統合できます。
スケーラブルなデータ処理パイプラインの構築
コンピュータビジョン企業が、モデルトレーニングのために数百万の画像を処理する必要があります。彼らはAIインフラプロバイダーのクラウドストレージとデータ処理サービスを利用します。新しい画像がアップロードされるたびに、リサイズや正規化などの処理ジョブをトリガーする自動化パイプラインを構築します。このサーバーレスアプローチにより、サーバーのプロビジョニングや管理を行うことなく、大量のデータを並行して処理でき、データセットが常に次のトレーニング実行に備えられていることを保証します。
セキュアな環境での協調的なAI開発
金融サービス企業が、機密性の高い顧客データを使用して不正検出モデルを開発しています。彼らは安全で協調的な環境を必要としています。厳格なアクセス制御を備えた隔離された開発環境(ノートブック)を提供する専門のAIプラットフォームを使用します。データサイエンティストは、生データを公開することなくモデル開発で協力できます。プラットフォームに組み込まれたセキュリティ機能とコンプライアンス認証により、すべての開発活動が業界の規制に準拠していることが保証され、データプライバシーを維持しながらイノベーションを可能にします。