Citronetic
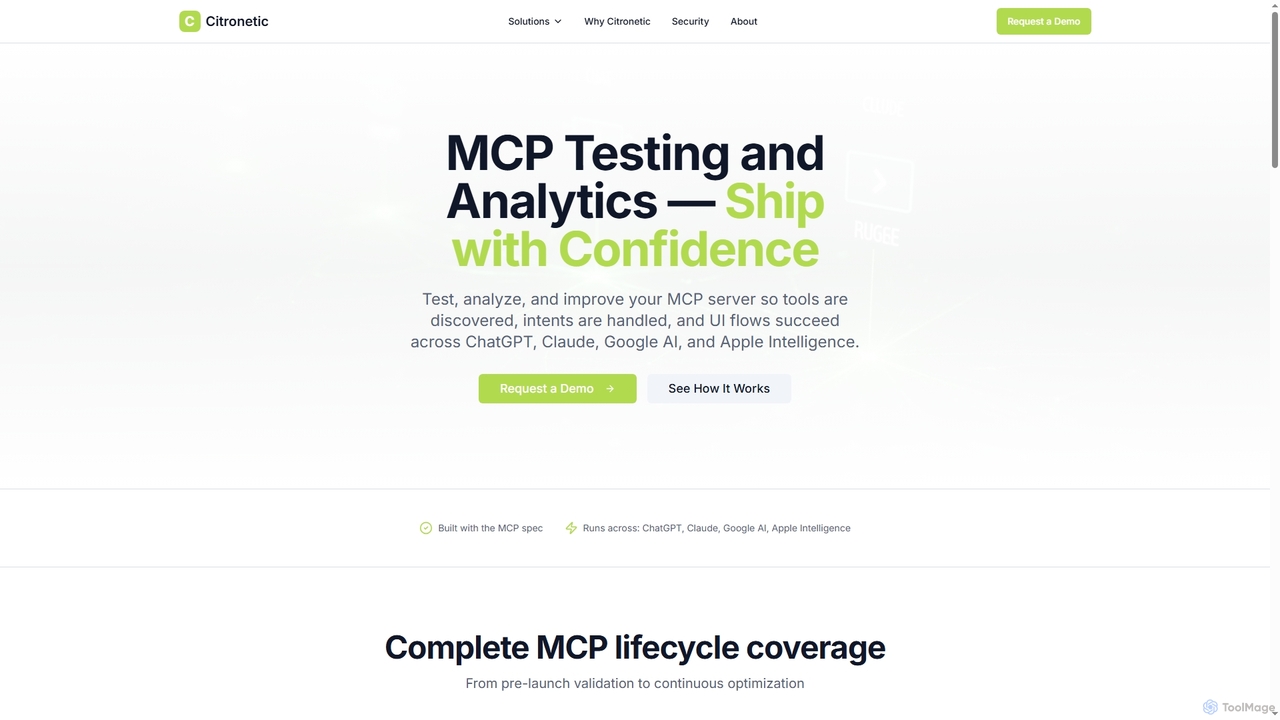
Citronetic là một nền tảng SaaS chuyên biệt để kiểm thử và phân tích MCP (Nền tảng Đàm …
Citronetic là một nền tảng SaaS chuyên biệt để kiểm thử và phân tích MCP (Nền tảng Đàm thoại Đa phương thức), đảm bảo việc khám phá công cụ mạnh mẽ, xử lý ý định và thành công luồng UI trên các nền tảng LLM hàng đầu như ChatGPT, Claude, Google AI và Apple Intelligence.
Scorecard
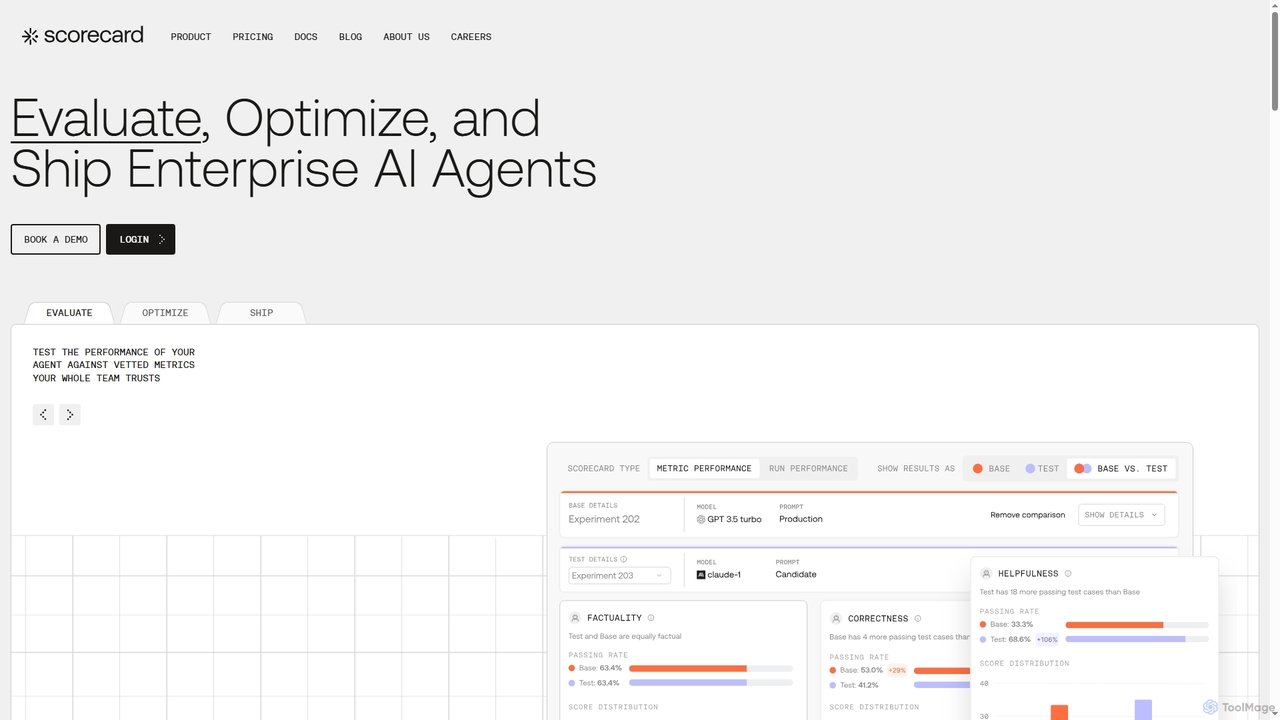
Scorecard là một nền tảng toàn diện để đánh giá, tối ưu hóa và triển khai các tác …
Scorecard là một nền tảng toàn diện để đánh giá, tối ưu hóa và triển khai các tác nhân AI doanh nghiệp. Nó giúp các nhóm thay thế thử nghiệm chủ quan bằng các đánh giá có cấu trúc, cung cấp các công cụ để giám sát liên tục, quản lý lời nhắc và các chỉ số hiệu suất để tự tin xây dựng các ứng dụng AI đáng tin cậy và ổn định.
PromptsLabs
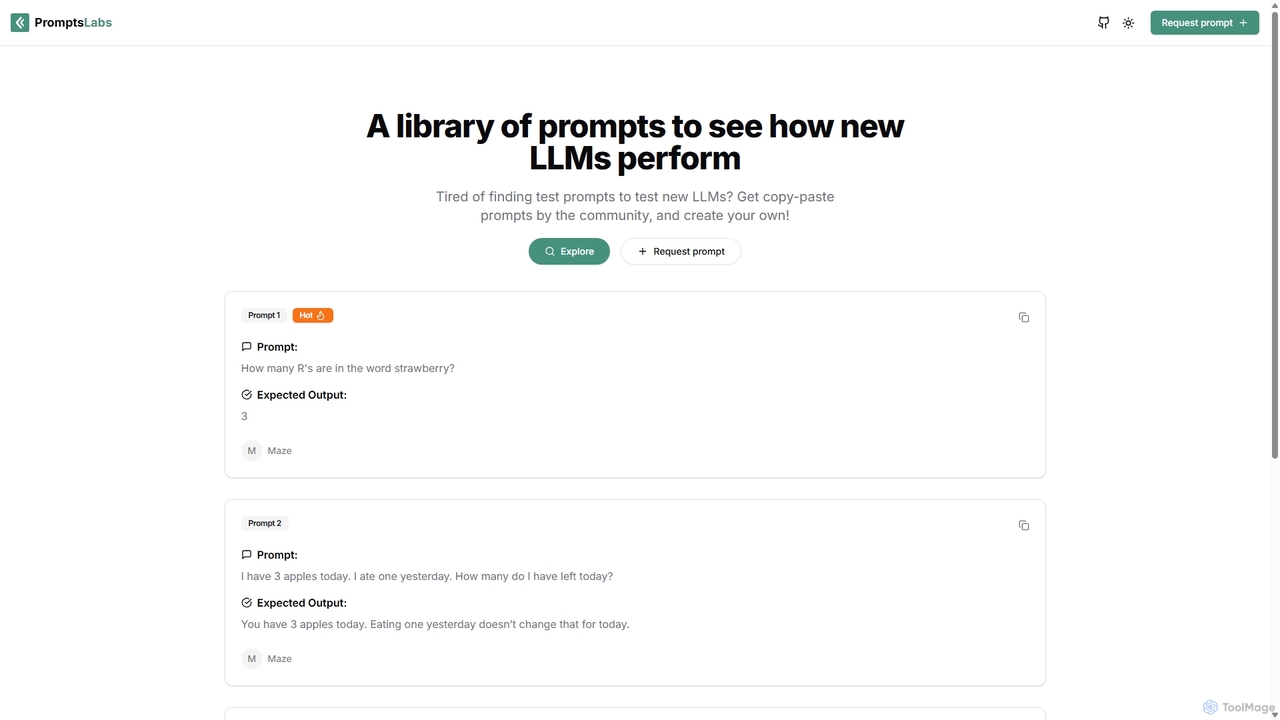
PromptsLabs là một thư viện prompt do cộng đồng điều khiển, được thiết kế để kiểm tra và …
PromptsLabs là một thư viện prompt do cộng đồng điều khiển, được thiết kế để kiểm tra và đánh giá hiệu suất của các Mô hình Ngôn ngữ Lớn (LLM) mới. Nó cung cấp một bộ sưu tập chuẩn hóa các prompt có thể sao chép-dán kèm theo kết quả mong đợi, giúp các nhà phát triển và nhà nghiên cứu đánh giá hiệu năng của các mô hình trên các tác vụ như logic, suy luận và toán học.
Prompteams
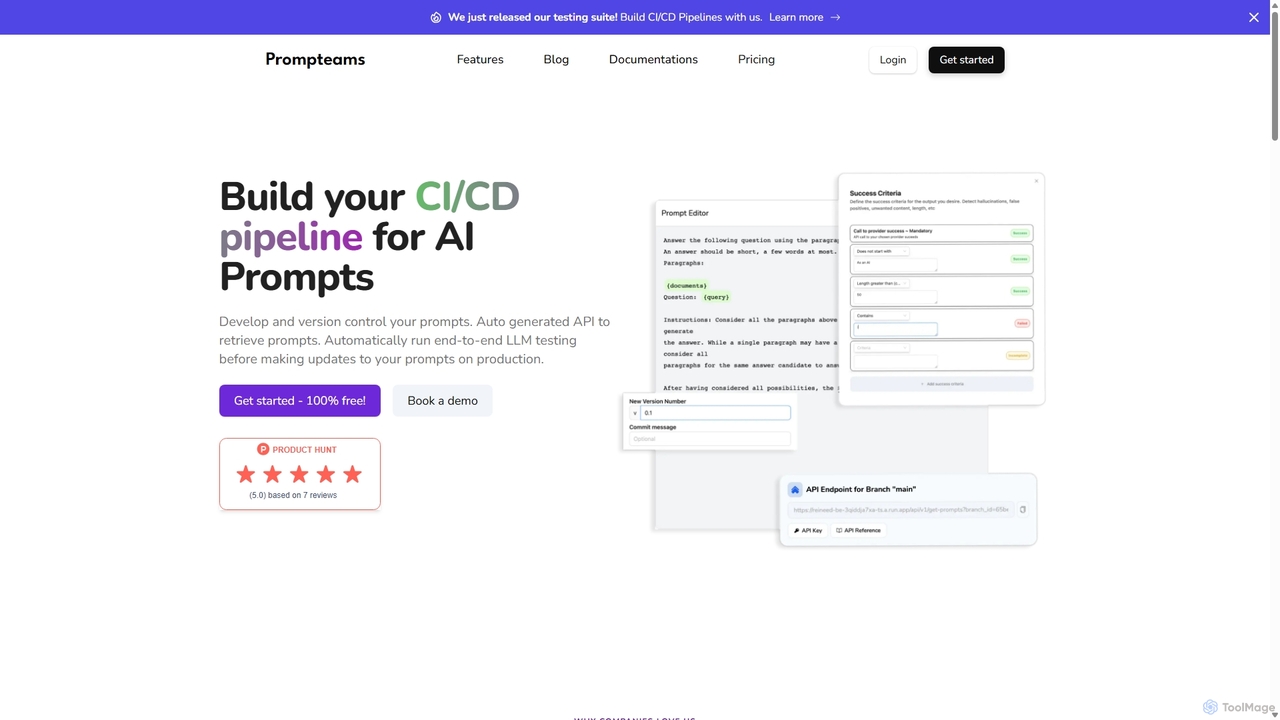
Prompteams là một hệ thống quản lý prompt AI toàn diện được thiết kế cho các nhóm. Nó …
Prompteams là một hệ thống quản lý prompt AI toàn diện được thiết kế cho các nhóm. Nó cung cấp một quy trình làm việc giống như Git với việc quản lý phiên bản, phân nhánh và commit để quản lý và lặp lại các prompt LLM. Nền tảng này có một bộ kiểm thử mạnh mẽ để đảm bảo chất lượng, API thời gian thực để triển khai tức thì và các công cụ cộng tác giúp thu hẹp khoảng cách giữa kỹ sư và chuyên gia ngành. Đây là giải pháp toàn diện để xây dựng một đường ống CI/CD cho các prompt AI, đảm bảo chất lượng, tính nhất quán và phát triển nhanh chóng.
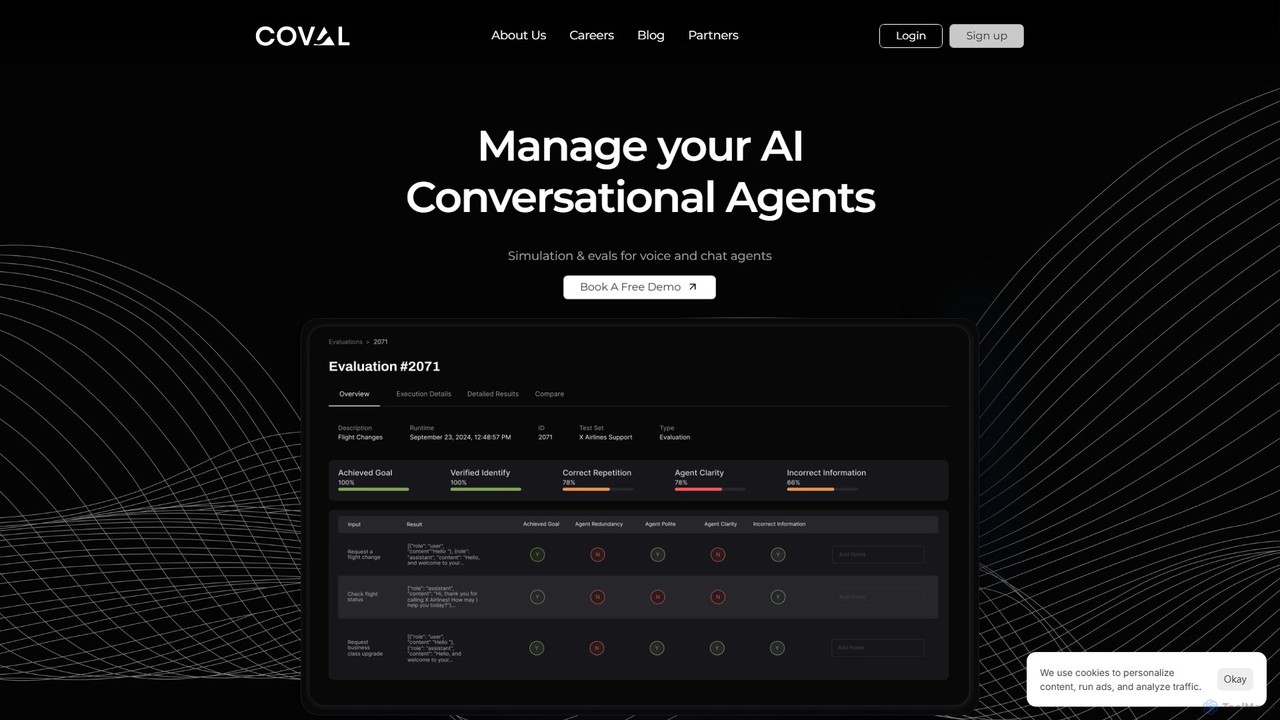
Coval
Coval là một nền tảng tiên tiến để mô phỏng và đánh giá các tác nhân đối thoại …
Coval là một nền tảng tiên tiến để mô phỏng và đánh giá các tác nhân đối thoại AI. Được xây dựng bởi các chuyên gia từ Waymo, nó giúp các nhà phát triển kiểm thử các tác nhân giọng nói và trò chuyện ở quy mô lớn, đảm bảo độ tin cậy và hiệu suất. Nền tảng tự động hóa việc kiểm thử bằng cách mô phỏng hàng nghìn kịch bản, cung cấp các chỉ số hiệu suất sâu sắc và giám sát sản xuất để phát hiện các lỗi hồi quy và tối ưu hóa hành vi của tác nhân.
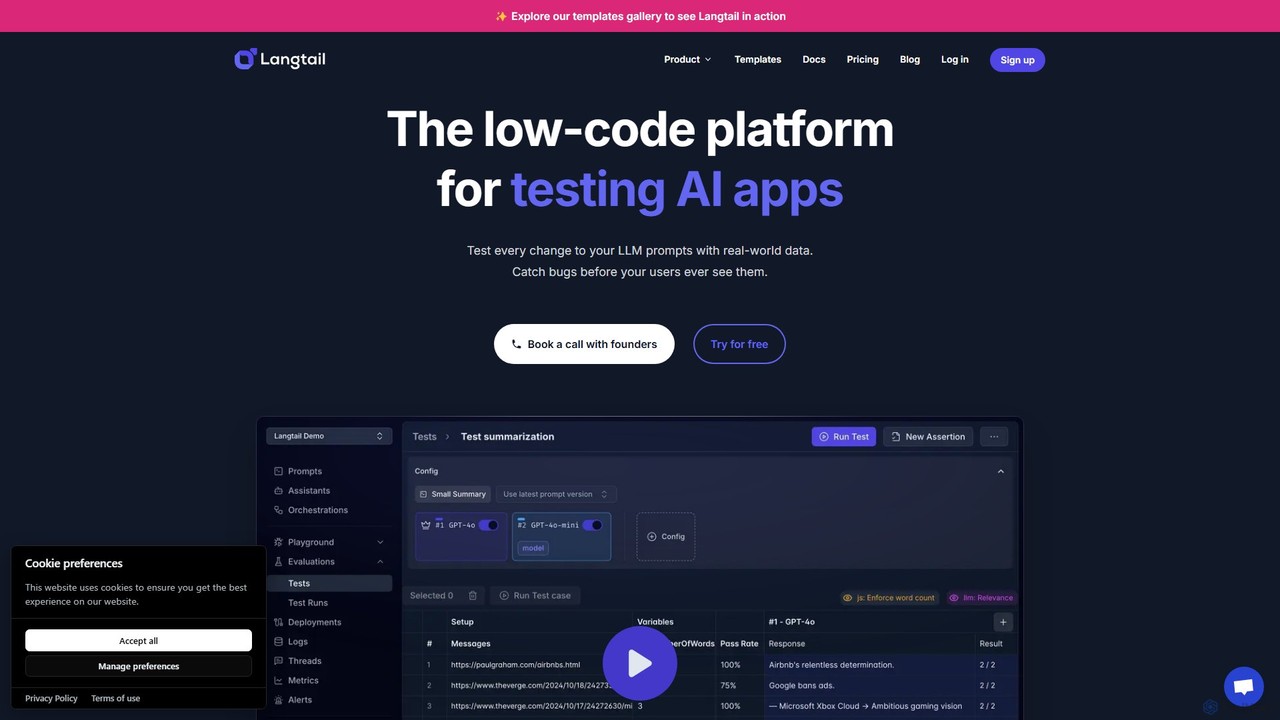
Langtail
Langtail là một nền tảng low-code để kiểm thử và gỡ lỗi các ứng dụng AI được cung …
Langtail là một nền tảng low-code để kiểm thử và gỡ lỗi các ứng dụng AI được cung cấp bởi các Mô hình Ngôn ngữ Lớn (LLM). Nó giúp các nhóm đảm bảo khả năng dự đoán và an toàn với giao diện kiểm thử giống bảng tính, Tường lửa AI để chặn các đầu vào độc hại và các công cụ cộng tác để quản lý prompt. Phát hiện lỗi và tối ưu hóa đầu ra LLM của bạn trước khi chúng đến tay người dùng.
Hamming AI
Hamming AI là một nền tảng tiên tiến để kiểm thử tự động, giám sát sản xuất và …
Hamming AI là một nền tảng tiên tiến để kiểm thử tự động, giám sát sản xuất và phân tích cho các tác nhân giọng nói AI. Nó cho phép các nhà phát triển mô phỏng hàng nghìn cuộc gọi, kiểm tra các cuộc hội thoại trực tiếp và phát hiện ngay lập tức các lỗi hồi quy để đảm bảo độ tin cậy và hiệu suất của AI giọng nói trên nhiều ngôn ngữ.
Cekura
Cekura là một nền tảng được hỗ trợ bởi AI để kiểm thử và quan sát các tác …
Cekura là một nền tảng được hỗ trợ bởi AI để kiểm thử và quan sát các tác nhân AI đàm thoại. Nó cho phép các nhà phát triển tự động hóa việc kiểm thử các tác nhân giọng nói và trò chuyện qua hàng nghìn kịch bản, sử dụng các nhân vật và điều kiện thực tế khác nhau để đảm bảo độ tin cậy, ngăn ngừa lỗi và tăng tốc triển khai.