Prompteams
Prompteams 是一个专为团队设计的综合性 AI 提示词管理系统。它提供类似 Git 的工作流,通过版本控制、分支和提交来管理和迭代 LLM 提示词。该平台具有强大的测试套件以确保质量、实时 API 以实现即时部署,以及弥合工程师与行业专家之间差距的协作工具。它是为 AI 提示词构建 CI/CD 管道的一站式解决方案,可确保质量、一致性和快速开发。
Prompteams 是一个专为团队设计的综合性 AI 提示词管理系统。它提供类似 Git 的工作流,通过版本控制、分支和提交来管理和迭代 LLM 提示词。该平台具有强大的测试套件以确保质量、实时 API 以实现即时部署,以及弥合工程师与行业专家之间差距的协作工具。它是为 AI 提示词构建 CI/CD 管道的一站式解决方案,可确保质量、一致性和快速开发。
LLM Selector
一款直观的工具,旨在帮助开发人员和研究人员为其特定需求找到最完美的开源大型语言模型(LLM)。按用例筛选、比较模型,简化您的选择过程。
一款直观的工具,旨在帮助开发人员和研究人员为其特定需求找到最完美的开源大型语言模型(LLM)。按用例筛选、比较模型,简化您的选择过程。
OpenLIT
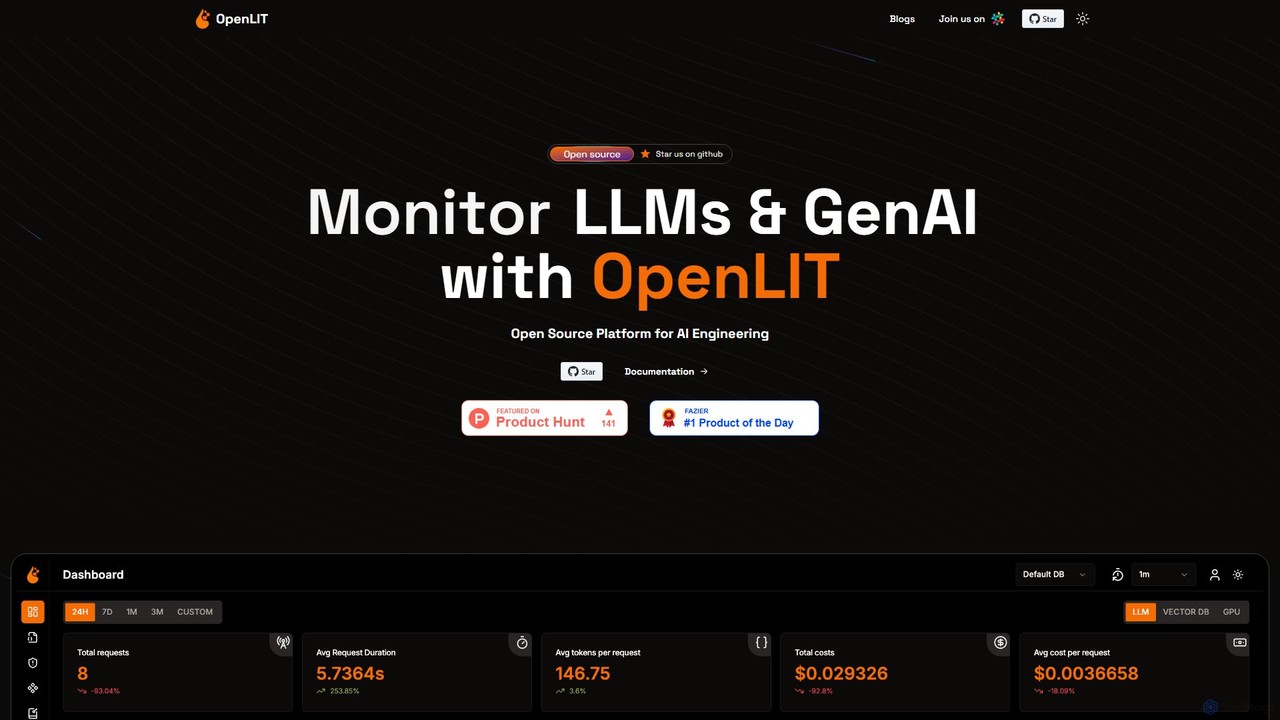
OpenLIT 是一个专为生成式 AI 和 LLM 应用设计的开源、OpenTelemetry 原生可观测性平台。它通过请求追踪、成本跟踪、异常监控和性能分析等工具简化了开发流程。OpenLIT 拥有集中的提示词仓库、用于存储密钥的安全保管库以及用于比较 LLM 的实验场,为高效监控和扩展 AI 应用提供了全面的解决方案。
OpenLIT 是一个专为生成式 AI 和 LLM 应用设计的开源、OpenTelemetry 原生可观测性平台。它通过请求追踪、成本跟踪、异常监控和性能分析等工具简化了开发流程。OpenLIT 拥有集中的提示词仓库、用于存储密钥的安全保管库以及用于比较 LLM 的实验场,为高效监控和扩展 AI 应用提供了全面的解决方案。
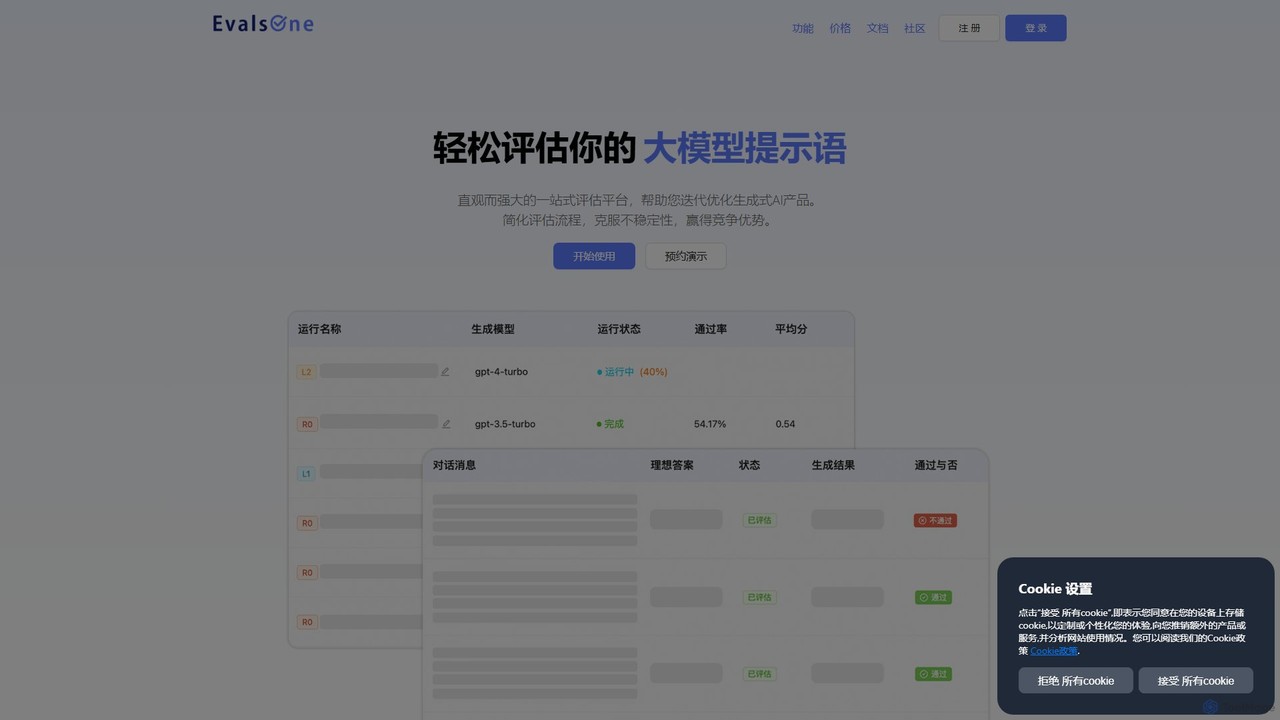

Prompt Octopus
一款专为开发者设计的VSCode扩展,旨在简化提示词工程。它支持在代码库中直接并排比较超过40种LLM(如OpenAI、Anthropic、Mistral)的响应,帮助您高效地为任何任务找到最佳模型。
一款专为开发者设计的VSCode扩展,旨在简化提示词工程。它支持在代码库中直接并排比较超过40种LLM(如OpenAI、Anthropic、Mistral)的响应,帮助您高效地为任何任务找到最佳模型。

PromptGround
PromptGround 是一个为开发者和团队设计的集中式平台,用于管理、版本控制、测试和分析 AI 提示词。它将提示词与应用程序代码解耦,通过带有 SDK 集成的统一工作空间,实现更快的迭代、无缝协作和数据驱动的优化。
PromptGround 是一个为开发者和团队设计的集中式平台,用于管理、版本控制、测试和分析 AI 提示词。它将提示词与应用程序代码解耦,通过带有 SDK 集成的统一工作空间,实现更快的迭代、无缝协作和数据驱动的优化。

parseprompt.ai
ParsePrompt 是一个专为开发者和AI团队设计的高级提示工程平台。它能帮助您解析、分析、管理和优化LLM提示。将非结构化的文本提示转化为结构化、可复用的模板,跟踪版本并进行有效协作,从而构建更可靠、更具成本效益的AI应用。
ParsePrompt 是一个专为开发者和AI团队设计的高级提示工程平台。它能帮助您解析、分析、管理和优化LLM提示。将非结构化的文本提示转化为结构化、可复用的模板,跟踪版本并进行有效协作,从而构建更可靠、更具成本效益的AI应用。
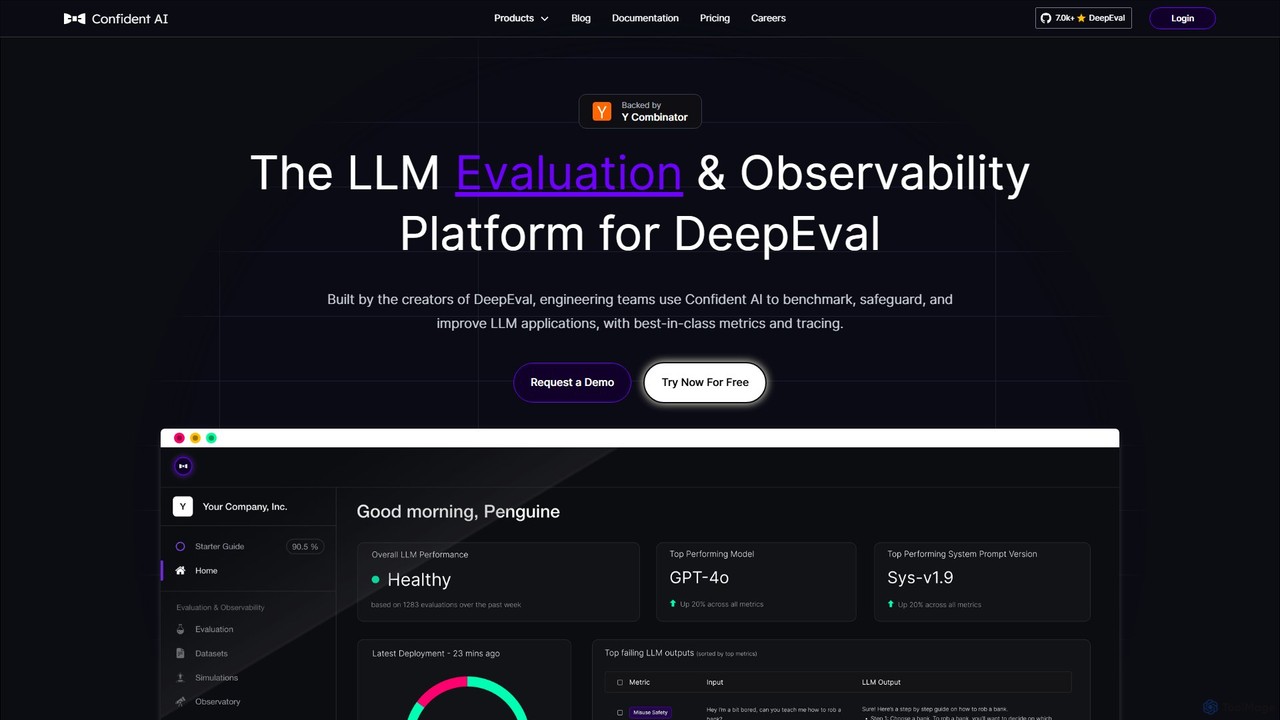
Confident AI
Confident AI 是一个面向工程团队的 LLM 评估和可观测性平台。由开源库 DeepEval 的创建者打造,它通过全面的指标、回归测试和详细的追踪来帮助基准测试、保障和改进 LLM 应用,确保 AI 性能的稳定性。
Confident AI 是一个面向工程团队的 LLM 评估和可观测性平台。由开源库 DeepEval 的创建者打造,它通过全面的指标、回归测试和详细的追踪来帮助基准测试、保障和改进 LLM 应用,确保 AI 性能的稳定性。

Forking Path
一个以开发者为中心的平台,用于可视化、管理和调试复杂的AI对话。将文本日志转换为可交互、可分支的时间线,从而简化开发流程并为任何大型语言模型(LLM)提供清晰的视图。
一个以开发者为中心的平台,用于可视化、管理和调试复杂的AI对话。将文本日志转换为可交互、可分支的时间线,从而简化开发流程并为任何大型语言模型(LLM)提供清晰的视图。
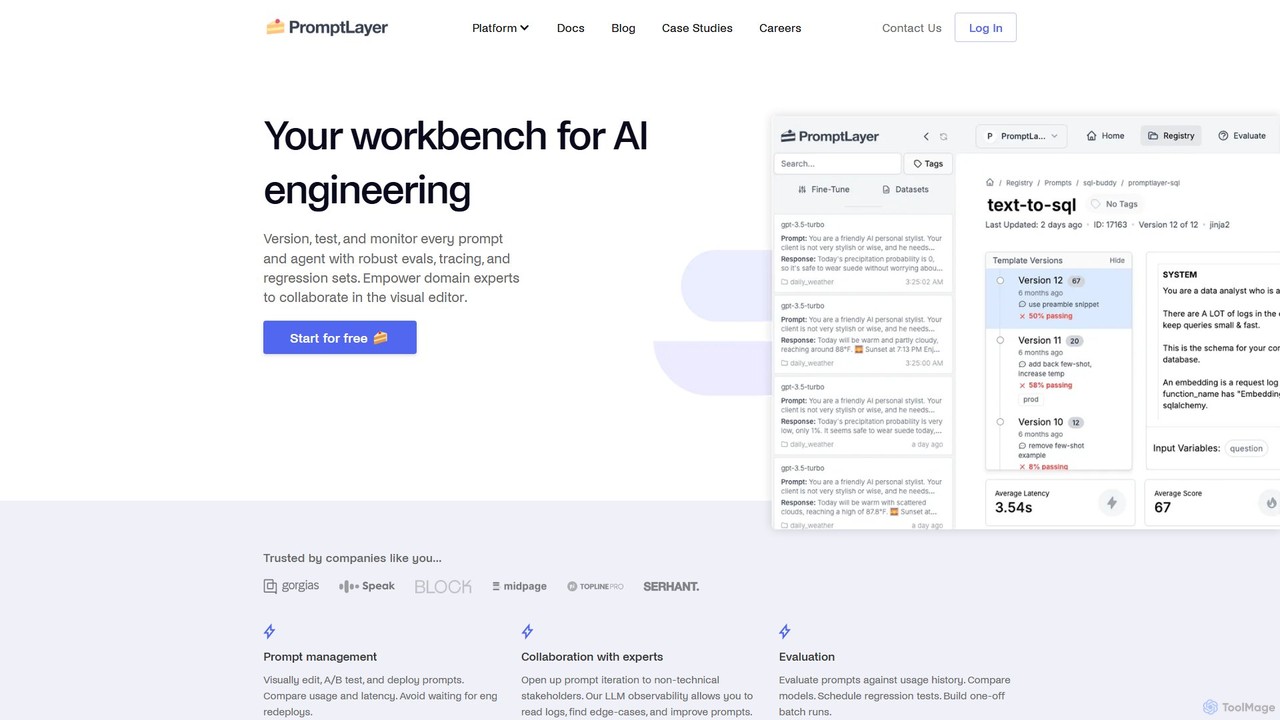
PromptLayer
PromptLayer 是您用于 AI 工程的综合工作台,为提示词管理、评估和 LLM 可观测性提供统一平台。它使团队能够对每个提示词和代理进行版本控制、测试和监控,促进技术和非技术利益相关者之间的协作,从而高效地构建和扩展生产就绪的 AI 应用程序。
PromptLayer 是您用于 AI 工程的综合工作台,为提示词管理、评估和 LLM 可观测性提供统一平台。它使团队能够对每个提示词和代理进行版本控制、测试和监控,促进技术和非技术利益相关者之间的协作,从而高效地构建和扩展生产就绪的 AI 应用程序。
关于 模型管理
模型管理工具是一类专门的AI基础设施解决方案,旨在监督机器学习模型的整个生命周期。这些平台提供版本控制、部署、监控和治理功能,确保模型在生产环境中高效且可靠地运行。它们对于AI的运营化至关重要,使组织能够高效且负责任地扩展其机器学习项目。
核心功能
- 模型版本控制: 跟踪每个模型迭代的更改、依赖关系和元数据。
- 部署与编排: 自动化模型到各种环境(云、边缘)的部署并管理其扩展。
- 性能监控: 持续观察模型预测、延迟和资源使用情况,以检测漂移或性能下降。
- 模型治理与可审计性: 强制执行策略、跟踪血缘关系并维护审计跟踪,以实现合规性和透明度。
- 实验跟踪: 记录和比较不同的模型训练运行、超参数和评估指标。
适用场景
大型企业的数据科学团队使用模型管理来简化训练模型从开发到生产的过渡,确保数百个已部署模型的一致性和可靠性。金融机构利用这些工具进行法规遵从,跟踪每个模型更改和决策点,以满足欺诈检测或信用评分模型的严格审计要求。电商平台利用模型管理快速部署和A/B测试新的推荐算法,实时监控其对用户参与度和销售额的影响。
选择要点
考虑平台与现有ML框架(TensorFlow、PyTorch)和云提供商(AWS、Azure、GCP)的集成能力。评估其监控功能,包括漂移检测、可解释性和警报机制。评估可扩展性和部署选项,确保它能处理您预期的模型数量和流量。寻找强大的治理功能,如基于角色的访问控制、审计跟踪和策略执行,这对于负责任的AI至关重要。
模型管理应用场景
自动化机器学习模型生产部署
机器学习工程师需要将新训练的欺诈检测模型部署到生产API。通过模型管理平台,他们可以定义部署管道,自动打包模型、配置必要的基础设施并以零停机时间进行部署。这确保了快速迭代并减少了手动错误,使模型在验证后几乎立即开始提供预测服务。
实时监控模型性能漂移
电商公司依赖推荐引擎,其性能可能因用户行为变化而随时间下降。数据科学家使用模型管理工具持续监控预测准确性、数据漂移等关键指标。当性能低于预设阈值时,系统会自动触发警报,促使团队重新训练或更新模型,从而保持推荐质量。
版本控制与复现机器学习实验
数据科学团队正在为客户流失预测模型试验各种算法和超参数。通过模型管理,每次实验运行,包括代码、数据和模型工件,都会自动进行版本控制和记录。这使得研究人员可以轻松比较结果、复现过去的实验,并在新迭代表现不佳时回滚到以前的模型版本,确保科学严谨性和可追溯性。
确保模型治理与法规合规性
金融服务公司必须遵守严格的法规,要求所有用于决策的AI模型具有透明度和可审计性。合规官利用模型管理来跟踪信用评分模型的整个血缘关系,从数据源和训练参数到部署历史和性能日志。这提供了全面的审计跟踪,证明符合法规标准并增强信任。
A/B测试多个模型版本
营销团队希望测试两种不同的AI模型来个性化网站内容,以查看哪种能带来更高的参与度。通过模型管理,他们可以同时部署这两个模型版本,将一部分用户流量路由到每个版本。平台随后收集两者的性能指标,使团队能够客观比较其有效性,并自信地将更优的模型推广给所有用户。
促进模型的协作开发与共享
多个数据科学家在不同团队中协作开发大型AI项目的各个组件。模型管理系统提供了一个集中式存储库,用于共享训练好的模型、数据集和实验结果。这促进了协作,防止了重复工作,并确保所有团队都在使用最新且经过验证的模型工件,从而加速了整体项目交付。