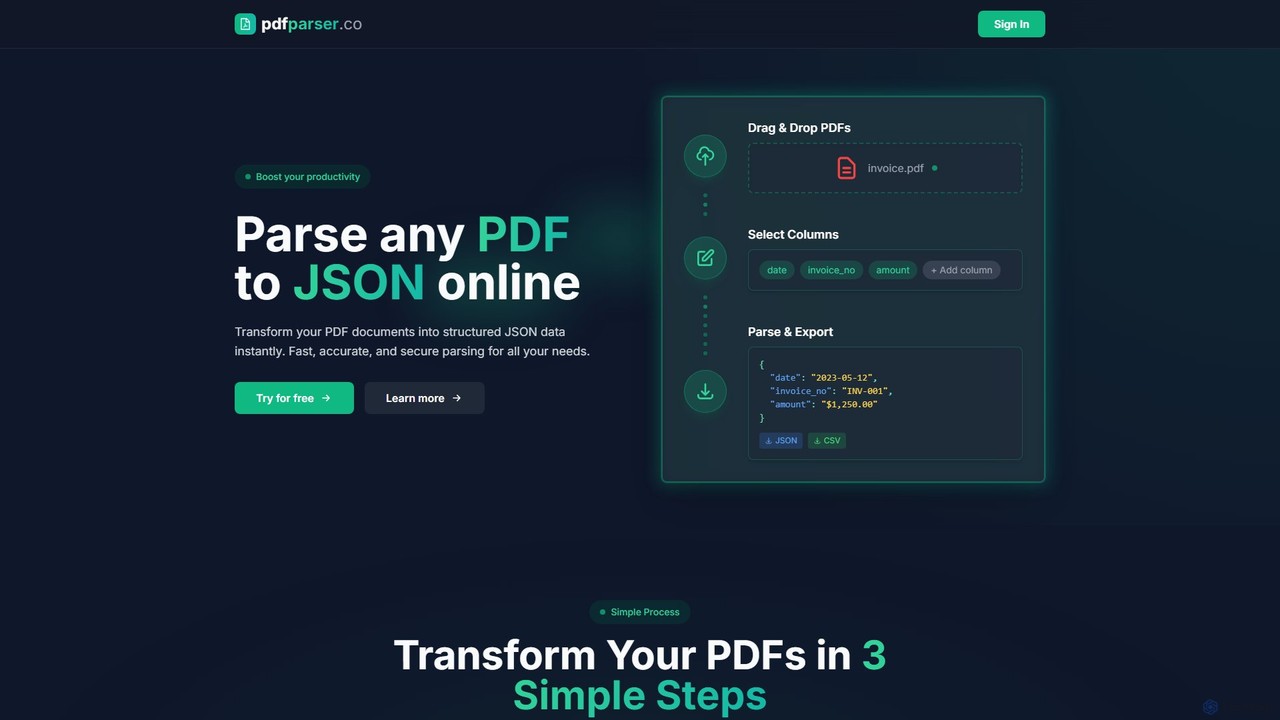
最佳综合替代
Finigami AI
Finigami AI 与 pdfparser 都覆盖 文档处理、自动化,并共同匹配 自动化、API、数据提取 等需求,适合优先比较相近使用场景的用户。
Finigami AI 不同于 pdfparser 的地方在于:主场景更偏向文档处理。
Match score: 32
月访问: 2.5K