Tersa
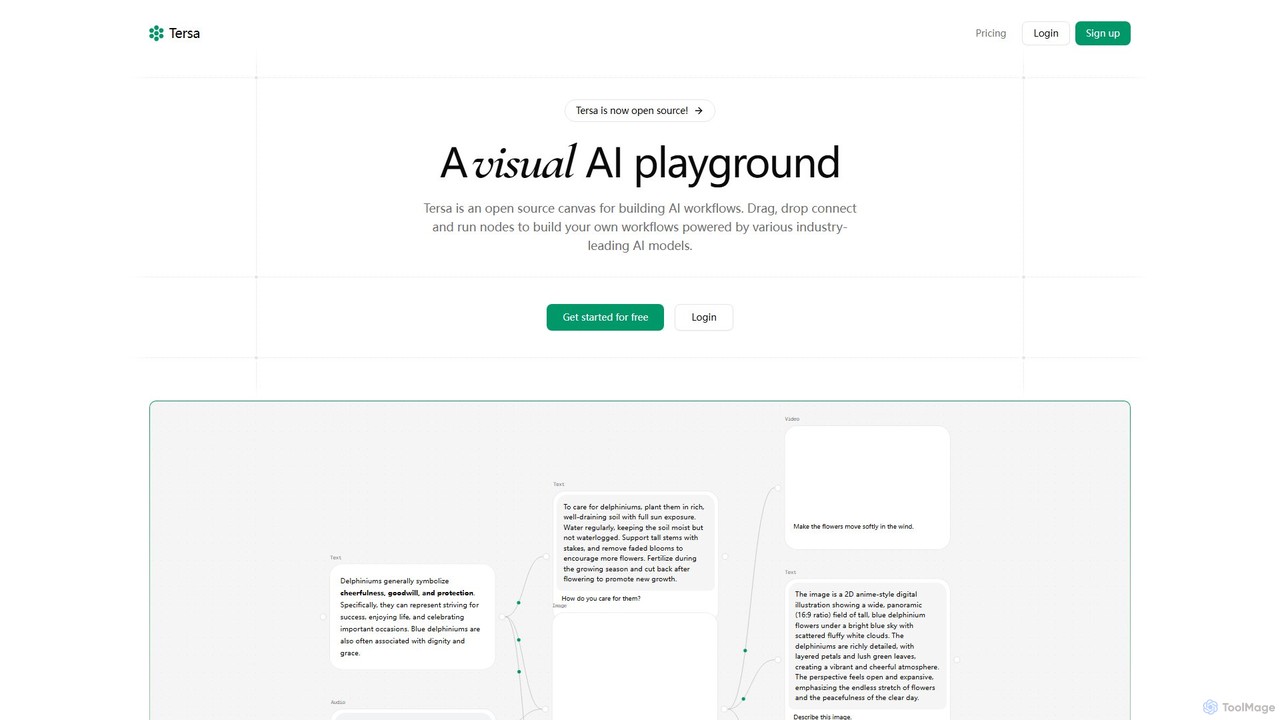
Tersa is an open-source visual AI playground for building complex AI workflows. It features a drag-and-drop canvas where …
Tersa is an open-source visual AI playground for building complex AI workflows. It features a drag-and-drop canvas where users can connect nodes to integrate over 100 AI models from leading providers like OpenAI and Anthropic. It supports multi-modal operations, including text generation, image creation, video synthesis, audio transcription, and code transformation, making it a versatile tool for developers and creators.
About Multi Modal
Multi Modal AI tools are advanced artificial intelligence systems capable of processing, understanding, and generating information across multiple data types simultaneously, such as text, images, audio, and video. These tools leverage sophisticated algorithms to integrate insights from diverse modalities, enabling a more comprehensive and nuanced understanding of complex inputs. By breaking down the barriers between different data formats, Multi Modal AI empowers users to create richer content, gain deeper insights, and build more intuitive interactive experiences.
Core Features
- Cross-Modal Understanding: Ability to interpret and correlate information from different data types (e.g., understanding an image based on its textual description).
- Multi-Modal Generation: Generating new content that combines various modalities, such as creating a video from text prompts and audio, or an image with embedded text.
- Unified Representation Learning: Developing a single, coherent internal representation that captures the essence of information from all processed modalities.
- Contextual Integration: Enhancing understanding and output quality by using one modality to provide context for another.
Applicable Scenarios
Multi Modal AI tools are invaluable in fields requiring integrated data analysis and diverse content creation. They are widely used in marketing for generating dynamic campaigns, in education for creating interactive learning materials, and in healthcare for combining medical images with patient notes for diagnosis. Content creators, researchers, and developers benefit significantly from their ability to bridge different data formats.
How to Choose
When selecting Multi Modal AI tools, consider the specific modalities you need to process and generate (e.g., text-to-image, image-to-text, video analysis). Evaluate the tool's integration capabilities with existing workflows and platforms, its performance accuracy across different data types, and the level of customization offered. Also, assess the ease of use and the availability of pre-trained models for your specific domain, alongside pricing structures.
Multi ModalUse Cases
Enhanced Content Creation
Content creators can input text descriptions and audio cues to generate corresponding images or short video clips, streamlining the production of engaging multimedia content for social media, blogs, or marketing campaigns. This saves significant time and resources compared to manual creation, allowing for rapid iteration and diverse content output.
Interactive Educational Materials
Educators can use multi-modal tools to transform textbook content into interactive lessons by automatically generating relevant images, explanatory audio narrations, and even short video demonstrations from text. This makes learning more engaging and accessible for students with different learning styles, improving comprehension and retention.
Advanced Customer Service Bots
Businesses can deploy multi-modal AI chatbots that not only understand text queries but also analyze customer sentiment from voice input or interpret images shared by users (e.g., product issues). This enables more accurate and empathetic support, leading to higher customer satisfaction and more efficient issue resolution.
Automated Media Analysis
Researchers and media analysts can process large volumes of news articles, videos, and audio recordings simultaneously to identify trends, sentiment, and key events across different media types. This offers a holistic view of public discourse or market dynamics, enabling more informed decision-making and strategic planning.
Personalized Accessibility Solutions
Developers can create tools that convert visual information into descriptive text for visually impaired users, or translate spoken language into sign language animations, offering personalized and comprehensive accessibility features. This significantly enhances digital inclusivity, making content and services available to a wider audience.
Product Design and Prototyping
Designers can input textual descriptions of product features and desired aesthetics, along with rough sketches, to generate detailed 3D models or realistic renderings. This accelerates the conceptualization and prototyping phases of product development, allowing for quicker iterations and more efficient visualization of ideas before physical production.