Portkey AI
Portkey AI is an advanced AI gateway and LLM Ops platform designed for developers. It simplifies the development …
Portkey AI is an advanced AI gateway and LLM Ops platform designed for developers. It simplifies the development of reliable, scalable, and cost-effective AI applications by providing a unified API for various LLMs, real-time observability, semantic caching, and intelligent load balancing.
Parea AI
Parea AI is an end-to-end platform for developing, testing, and monitoring LLM applications. It provides tools for experiment …
Parea AI is an end-to-end platform for developing, testing, and monitoring LLM applications. It provides tools for experiment tracking, observability, evaluation, and human annotation to help teams confidently ship AI systems to production.
Vellum AI
Vellum AI is an end-to-end enterprise platform for building, evaluating, and deploying mission-critical AI agents and applications. It …
Vellum AI is an end-to-end enterprise platform for building, evaluating, and deploying mission-critical AI agents and applications. It provides a unified environment for orchestration, prompt engineering, RAG, evaluation, and monitoring, enabling teams to build reliable AI solutions 10x faster.
Tropir
Tropir is the first autonomous LLM-Ops engineer, designed to help developers build, debug, and optimize complex AI and …
Tropir is the first autonomous LLM-Ops engineer, designed to help developers build, debug, and optimize complex AI and LLM applications. It provides full pipeline tracing, failure forensics, and a self-improving agent to enhance AI performance and reliability.
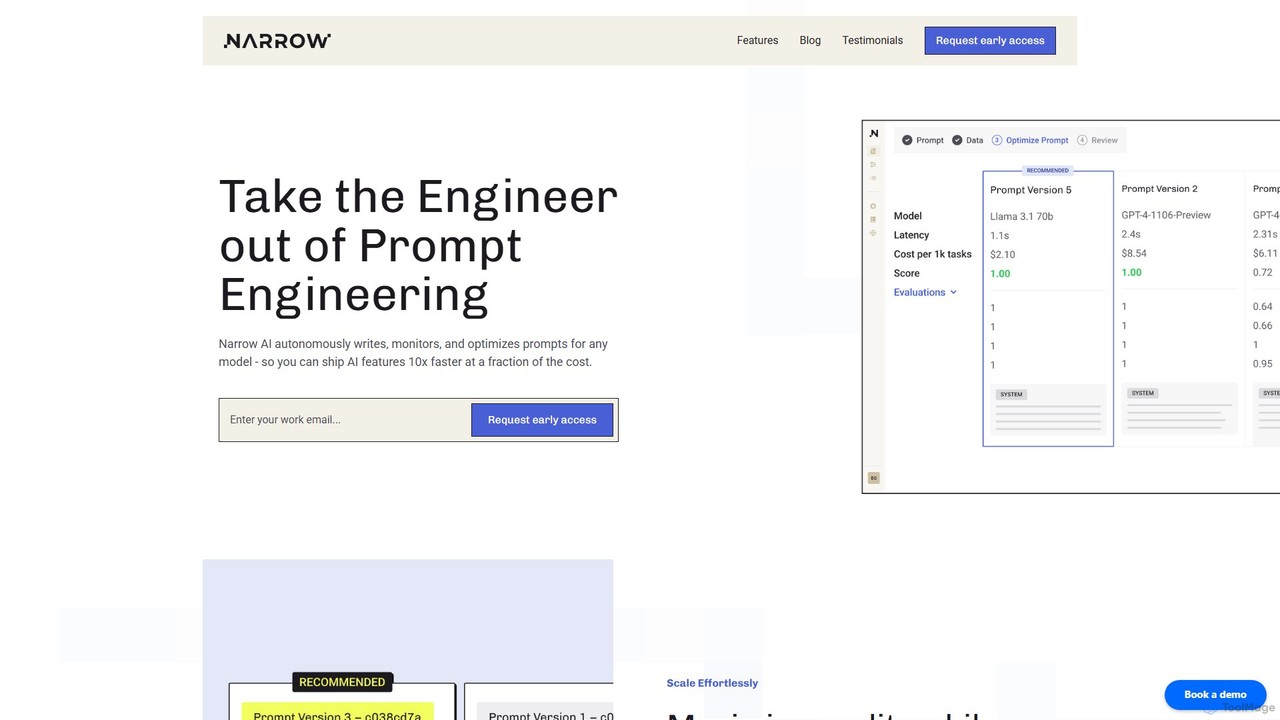
Narrow AI
Narrow AI is an LLM optimization platform for developers that automates prompt engineering and model selection to drastically …
Narrow AI is an LLM optimization platform for developers that automates prompt engineering and model selection to drastically reduce AI operational costs by up to 95%. It streamlines workflows, improves accuracy, and accelerates the deployment of high-quality, low-latency AI features.
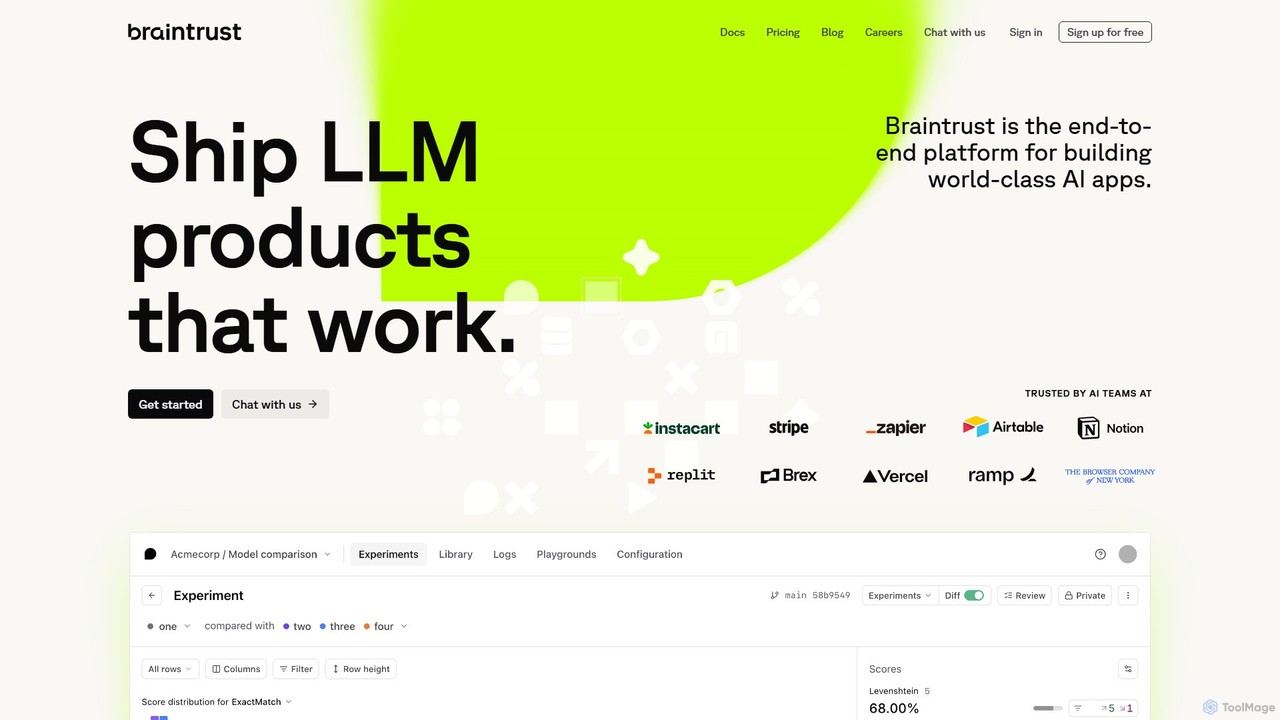
Braintrust
Braintrust is an end-to-end platform for developing, evaluating, and deploying robust LLM applications. It provides a comprehensive suite …
Braintrust is an end-to-end platform for developing, evaluating, and deploying robust LLM applications. It provides a comprehensive suite of tools for prompt engineering, model evaluation, real-time tracing, and production monitoring. Designed for both technical and non-technical team members, Braintrust helps streamline the AI development lifecycle, ensuring that AI products are reliable, effective, and ready for production.
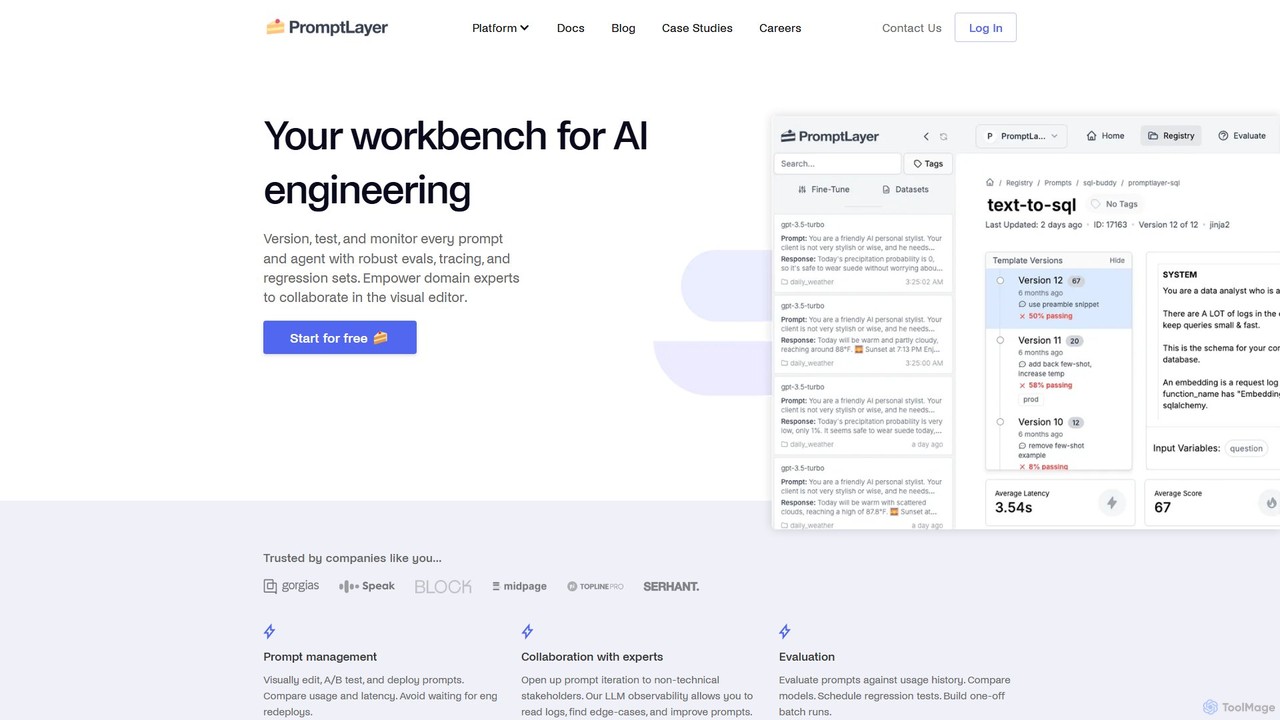
PromptLayer
PromptLayer is your comprehensive workbench for AI engineering, providing a unified platform for prompt management, evaluation, and LLM …
PromptLayer is your comprehensive workbench for AI engineering, providing a unified platform for prompt management, evaluation, and LLM observability. It empowers teams to version, test, and monitor every prompt and agent, fostering collaboration between technical and non-technical stakeholders to build and scale production-ready AI applications efficiently.
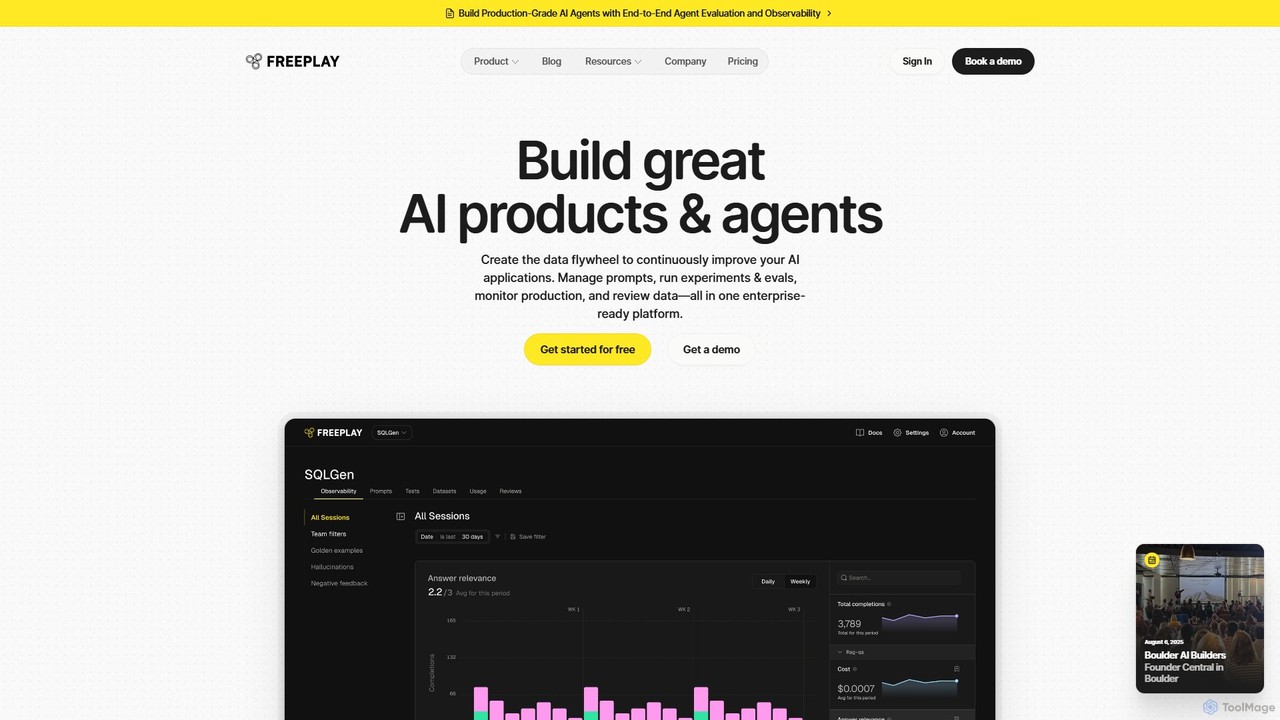
Freeplay
Freeplay is an enterprise-ready platform designed for AI teams to build, test, and continuously improve AI products and …
Freeplay is an enterprise-ready platform designed for AI teams to build, test, and continuously improve AI products and agents. It unifies prompt management, experimentation, LLM observability, and data review into a single workflow, creating a powerful data flywheel for accelerating product quality and development speed.
Langfuse
Langfuse is an open-source LLM engineering platform that provides comprehensive tools for debugging, evaluating, and improving LLM applications. …
Langfuse is an open-source LLM engineering platform that provides comprehensive tools for debugging, evaluating, and improving LLM applications. It offers features like tracing, prompt management, evaluation frameworks, and metrics to streamline the entire development lifecycle for teams building with large language models.
About Llm Ops
LLM Ops (Large Language Model Operations) are specialized developer tools designed to manage the entire lifecycle of large language models, from development and deployment to monitoring and optimization. These tools provide frameworks and platforms for prompt engineering, model versioning, performance tracking, and ensuring the safety and alignment of LLM-powered applications. They enable developers and MLOps teams to efficiently build, scale, and maintain robust AI products by streamlining complex operational challenges inherent in working with generative AI.
Core Features
- Prompt Management: Centralized storage, versioning, and testing of prompts to ensure consistent and optimal LLM responses.
- Model Deployment & Versioning: Tools for deploying different LLM versions, managing rollouts, and tracking changes across environments.
- Performance Monitoring: Real-time dashboards to track LLM latency, throughput, token usage, and error rates for proactive issue resolution.
- Cost Optimization: Features to analyze and manage API costs, token consumption, and resource allocation for efficient LLM usage.
- Safety & Alignment: Mechanisms to detect and mitigate harmful outputs, ensure ethical AI use, and align LLM behavior with desired guidelines.
Applicable Scenarios
LLM Ops tools are crucial for AI product teams, MLOps engineers, and data scientists who are building and scaling applications powered by large language models. They are used in scenarios where consistent LLM performance, cost efficiency, and responsible AI deployment are paramount. This includes developing AI assistants, content generation platforms, and intelligent search engines that rely heavily on LLM outputs.
How to Choose
When selecting an LLM Ops platform, consider its integration capabilities with your existing MLOps stack and cloud providers. Evaluate its prompt engineering features, including version control and A/B testing. Look for robust monitoring and observability tools that provide insights into model performance and cost. Finally, assess its support for safety, alignment, and compliance features to ensure responsible AI deployment.
Llm OpsUse Cases
Managing Prompt Versions for AI Chatbots
An AI product team developing a customer service chatbot needs to iterate on prompts to improve response accuracy and tone. Using LLM Ops tools, they can version control different prompt templates, A/B test their performance with real user queries, and roll back to previous versions if a new prompt degrades performance. This ensures continuous improvement of the chatbot's conversational quality while maintaining stability.
Monitoring LLM Performance in Production
An MLOps engineer is responsible for a live content generation platform powered by an LLM. They use LLM Ops dashboards to monitor key metrics like API latency, token usage, and error rates in real-time. If a sudden spike in latency or cost occurs, the engineer receives alerts, allowing them to quickly identify the root cause, such as an overloaded API endpoint or an inefficient prompt, and take corrective action to maintain service quality.
Optimizing LLM API Costs for Scalable Applications
A startup building a personalized learning application relies heavily on LLM APIs for generating educational content. Their finance team, in collaboration with developers, utilizes LLM Ops platforms to track token consumption per user and feature. By analyzing these metrics, they can identify costly prompts or inefficient LLM calls, implement caching strategies, or switch to more cost-effective models, significantly reducing operational expenses as the user base grows.
Ensuring LLM Safety and Alignment in Public-Facing Tools
A social media company deploying an AI-powered content moderation tool must ensure its LLM adheres to strict safety guidelines and avoids generating harmful or biased content. LLM Ops tools provide guardrails and alignment checks, allowing the team to define safety policies, filter undesirable outputs, and continuously evaluate the model's responses against ethical standards. This proactive approach helps prevent reputational damage and ensures responsible AI deployment.
A/B Testing Different LLM Models for Feature Rollouts
A development team is integrating a new summarization feature into their document management system and wants to compare the performance of two different LLMs. With LLM Ops, they can easily set up A/B tests, routing a percentage of users to each model. They then collect feedback on summary quality, speed, and user satisfaction, using data-driven insights to select the best-performing model for a full rollout, minimizing risks and maximizing impact.
Streamlining LLM Application Deployment Workflows
A data scientist has developed a prototype LLM-driven data analysis tool and needs to deploy it to production. LLM Ops platforms integrate with CI/CD pipelines, automating the deployment process. This includes packaging the model, configuring API endpoints, setting up monitoring, and managing environment variables. This automation reduces manual errors, accelerates time-to-market, and allows data scientists to focus more on model development rather than operational overhead.