Braintrust
Visit Website
Braintrust Overview
Braintrust is a comprehensive, end-to-end platform designed to help teams build, evaluate, and ship world-class AI and LLM-powered applications with confidence. In an era where AI models can be non-deterministic and unpredictable, Braintrust provides the essential infrastructure to introduce rigorous testing, monitoring, and iterative improvement into the AI development lifecycle. It is trusted by leading AI teams to bridge the critical gap between development and reliable production deployment, transforming AI development into a more structured and predictable engineering discipline.
The platform is built around the core concept of 'Evals' (Evaluations), which allows teams to systematically test changes to prompts, models, or any other part of their AI system. By creating datasets of examples and defining scorers, developers can get objective metrics on performance, preventing regressions and ensuring that every change is an improvement. This makes it easy to answer critical questions like “which examples regressed when we changed the prompt?” or “what happens if I try this new model?”.
How to use Braintrust
Using Braintrust involves integrating it into your existing AI development workflow. The process is designed to be intuitive for the entire team:
- Instrument Your Code: Start by integrating the Braintrust SDK (available for Python and TypeScript) into your application. This allows you to log all LLM interactions, inputs, and outputs to the Braintrust platform.
- Create & Manage Prompts: Use the Braintrust UI or define prompts directly in your code. The platform provides a centralized, version-controlled repository for all your prompts, which can be easily tested and updated.
- Build Test Datasets: Capture interesting or problematic examples from your production logs to create 'golden' datasets. These datasets serve as the ground truth for evaluating future changes.
- Define and Run Evaluations (Evals): Combine your prompts, models, and datasets to create an 'Eval'. Run experiments to compare different model providers (like GPT-4o, Claude 3.5 Sonnet, Llama 3), prompt versions, or other parameters side-by-side.
- Debug with Tracing: When an application misbehaves, use Braintrust's tracing feature to visualize the entire execution path of an LLM call. This helps pinpoint the exact cause of errors or unexpected outputs.
- Monitor in Production: Once deployed, use the monitoring dashboards to track the real-world performance, cost, and quality of your AI application. Set up alerts for anomalies or degradations.
- Iterate and Improve: Use insights from evaluations, human reviews, and production monitoring to continuously refine your prompts and datasets, creating a powerful feedback loop for improvement.
Core Features of Braintrust
- LLM Evaluation (Evals): Systematically test and compare prompts, models, and configurations using a wide range of pre-built or custom-coded scorers (e.g., Levenshtein distance, Similarity, Hallucination checks).
- Prompt Management: A centralized and version-controlled system for creating, testing, and deploying prompts, which are seamlessly synced between the UI and your codebase.
- Real-time Tracing & Debugging: Visualize the complete, end-to-end execution flow of your AI applications to quickly identify bottlenecks, errors, and optimization opportunities.
- Production Monitoring: Gain deep insights into real-world performance, cost, latency, and user interactions to ensure your models perform optimally in a live environment.
- Collaborative Playground: An IDE-like environment where technical and non-technical team members can experiment with prompts, models, and data in real-time.
- Golden Datasets: Create, manage, and version curated datasets from real-world data for robust regression testing and evaluation.
- Self-Hosting Option: Deploy Braintrust on your own infrastructure for complete control over your data, meeting strict security and compliance requirements.
- AI Proxy: A unified interface to interact with various LLM providers, simplifying API calls, credential management, and model switching.
- Human Review Workflow: A built-in system to allow human experts to grade AI outputs, providing valuable feedback that can be integrated into your datasets and evaluations.
Use Cases for Braintrust
Braintrust is versatile and can be applied across various scenarios in AI development:
- A/B Testing LLM Prompts: A developer can create two versions of a prompt and run an evaluation on a golden dataset to objectively determine which one performs better on metrics like accuracy, relevance, or tone.
- Model Benchmarking and Migration: When a new model like Claude 3.5 Sonnet is released, a team can use Braintrust to evaluate its performance and cost against their current model (e.g., GPT-4o) on key business tasks before deciding to migrate.
- Debugging Complex AI Agents: For an agent that makes multiple sequential LLM calls, Braintrust's tracing visualizes the entire chain of thought, making it easy to spot where the logic failed or produced an incorrect result.
- Quality Assurance for RAG Systems: Teams can build datasets of questions and expected answers to continuously test their Retrieval-Augmented Generation (RAG) system, ensuring it doesn't regress in quality or start hallucinating.
- Cost and Latency Optimization: A product manager can use the monitoring dashboard to track the cost and response time of an AI feature in production, identifying expensive queries or performance bottlenecks that need engineering attention.
Advantages of Braintrust
Braintrust offers a significant competitive edge for teams building with AI:
- End-to-End Solution: It uniquely covers the entire AI application lifecycle, from initial experimentation and evaluation to production monitoring and continuous improvement.
- Manages AI's Non-Determinism: It brings structured testing and objective metrics to the unpredictable world of LLMs, helping teams build robust and reliable products.
- Fosters Team Collaboration: Its intuitive UI is designed for both engineers and non-technical stakeholders like product managers, enabling everyone to contribute to improving the AI product.
- Code and UI Synergy: It seamlessly syncs configurations like prompts between a user-friendly UI and the production codebase, bridging the gap between experimentation and deployment.
- Flexible and Extensible: With support for custom scorers, custom functions, and self-hosting, it can be adapted to fit the specific needs and infrastructure of any organization.
Pricing and Plans
Braintrust offers a tiered pricing structure designed to scale with your needs:
- Free Plan: $0/month. This plan is perfect for individuals and small teams getting started. It includes 1 million Trace spans, 1 GB of processed data, 10,000 scores, 14 days of data retention, and unlimited users.
- Pro Plan: $249/month. Aimed at growing teams and production applications, this plan offers unlimited Trace spans, 5 GB of processed data ($3/GB thereafter), 50,000 scores ($1.50/1,000 thereafter), 1 month of data retention, and unlimited users.
- Enterprise Plan: Custom pricing. This plan is for large organizations or those with high-volume or privacy-sensitive data. It includes premium support, dedicated infrastructure, and the option for on-premise or private cloud deployment.
Braintrust Comments (0)
Log in to post comments
Log in nowBraintrustWebsite Traffic Analysis
Latest Traffic
Status
Monthly Traffic Trend
Geography
Top 5 Countries/Regions
-
🇺🇸 United States70.13%
-
🇮🇳 India15.80%
-
🇨🇦 Canada5.06%
-
🇬🇧 United Kingdom4.68%
-
🇩🇪 Germany4.33%
Traffic source
| Source Type | Percentage |
|---|---|
|
Direct Access
|
91.18% |
|
Referral
|
6.95% |
|
Email
|
1.87% |
Popular Keywords
| Keyword | Cost Per Click |
|---|---|
|
$15.62
|
|
|
$3.33
|
|
|
$12.85
|
|
|
$3.32
|
|
|
$0.00
|
Braintrust Alternatives
View All
Langfuse
Langfuse is an open-source LLM engineering platform that provides comprehensive tools for debugging, evaluating, and improving LLM applications. …
Langfuse is an open-source LLM engineering platform that provides comprehensive tools for debugging, evaluating, and improving LLM applications. It offers features like tracing, prompt management, evaluation frameworks, and metrics to streamline the entire development lifecycle for teams building with large language models.
Parea AI
Parea AI is an end-to-end platform for developing, testing, and monitoring LLM applications. It provides tools for experiment …
Parea AI is an end-to-end platform for developing, testing, and monitoring LLM applications. It provides tools for experiment tracking, observability, evaluation, and human annotation to help teams confidently ship AI systems to production.
PromptLayer
PromptLayer is your comprehensive workbench for AI engineering, providing a unified platform for prompt management, evaluation, and LLM …
PromptLayer is your comprehensive workbench for AI engineering, providing a unified platform for prompt management, evaluation, and LLM observability. It empowers teams to version, test, and monitor every prompt and agent, fostering collaboration between technical and non-technical stakeholders to build and scale production-ready AI applications efficiently.
Freeplay
Freeplay is an enterprise-ready platform designed for AI teams to build, test, and continuously improve AI products and …
Freeplay is an enterprise-ready platform designed for AI teams to build, test, and continuously improve AI products and agents. It unifies prompt management, experimentation, LLM observability, and data review into a single workflow, creating a powerful data flywheel for accelerating product quality and development speed.
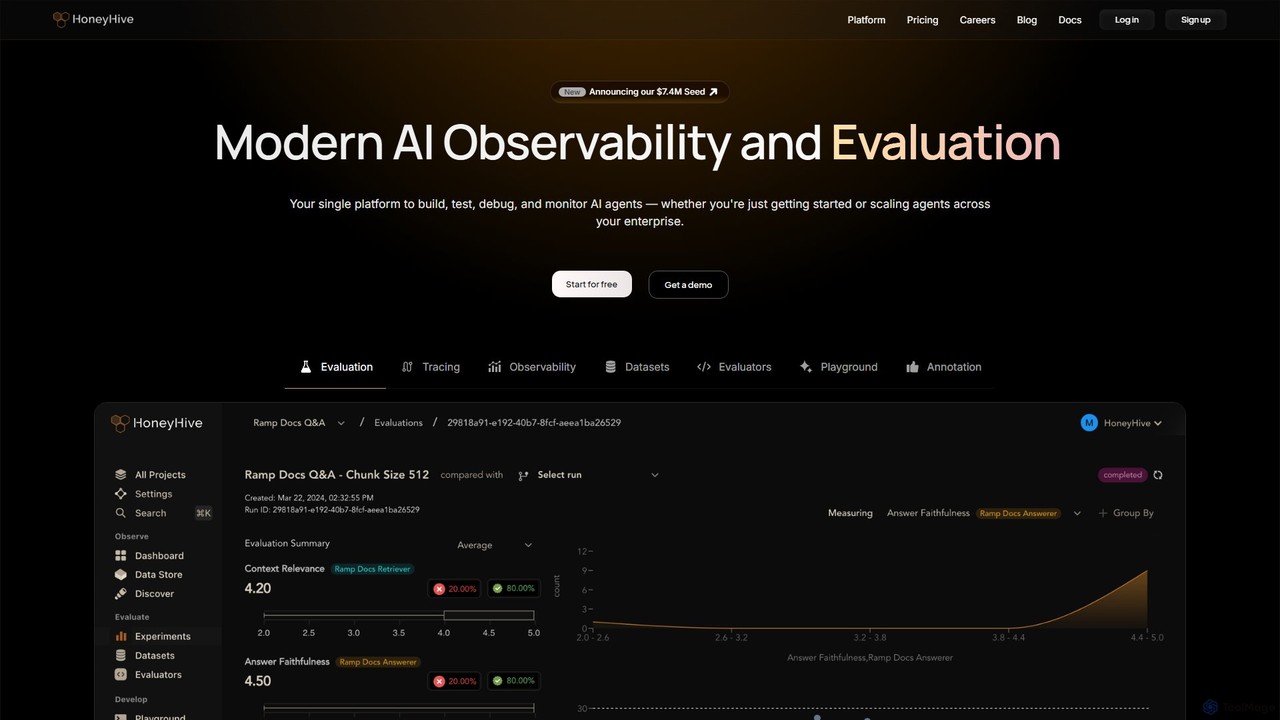
HoneyHive
HoneyHive is an all-in-one AI observability and evaluation platform for developers building with LLMs and AI agents. It …
HoneyHive is an all-in-one AI observability and evaluation platform for developers building with LLMs and AI agents. It provides a unified solution to build, test, debug, and monitor AI applications, from initial experiments to enterprise-scale deployment. The platform helps teams systematically measure AI quality, gain deep visibility into agent interactions, monitor performance metrics like cost and latency, and collaborate on essential assets like prompts and datasets, ensuring the confident shipment of reliable AI products.
Teammately
Teammately is an advanced AI agent platform for AI engineers. It automates and accelerates the entire AI development …
Teammately is an advanced AI agent platform for AI engineers. It automates and accelerates the entire AI development lifecycle, from prompt generation and RAG building to multi-dimensional evaluation and production observability. Build reliable, scalable, and secure AI applications that are hard to fail, in a fraction of the time.
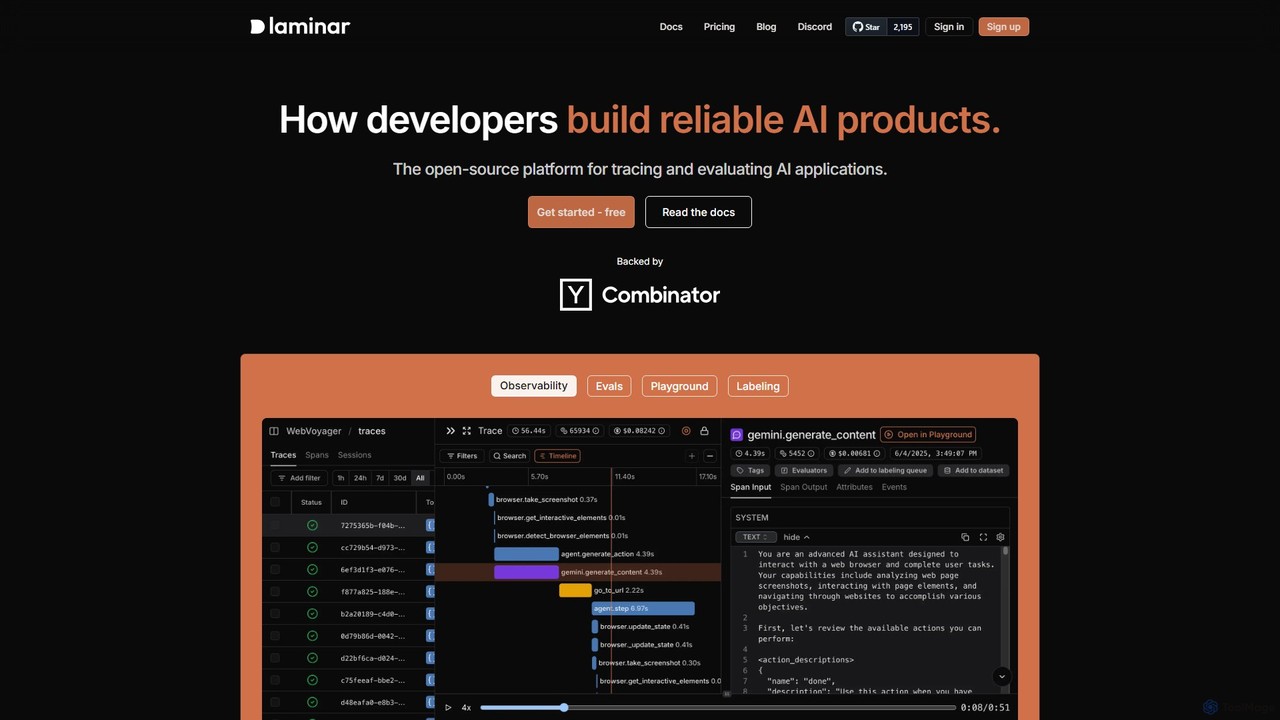
Laminar
Laminar is an open-source observability and evaluation platform designed for developers building reliable AI applications. It provides comprehensive …
Laminar is an open-source observability and evaluation platform designed for developers building reliable AI applications. It provides comprehensive tools for tracing, evaluating, and debugging LLM-powered systems. Key features include real-time tracing, browser agent observability, an interactive playground, and integrated dataset management, simplifying the entire MLOps lifecycle from development to production.

Pydantic
Pydantic is a comprehensive platform for developers, offering powerful data validation, AI development tools, and a full-stack observability …
Pydantic is a comprehensive platform for developers, offering powerful data validation, AI development tools, and a full-stack observability solution. It enables faster, more robust application development in Python and other languages by leveraging type hints for runtime data validation and providing deep insights from local development to production.
Tropir
Tropir is the first autonomous LLM-Ops engineer, designed to help developers build, debug, and optimize complex AI and …
Tropir is the first autonomous LLM-Ops engineer, designed to help developers build, debug, and optimize complex AI and LLM applications. It provides full pipeline tracing, failure forensics, and a self-improving agent to enhance AI performance and reliability.
Vellum AI
Vellum AI is an end-to-end enterprise platform for building, evaluating, and deploying mission-critical AI agents and applications. It …
Vellum AI is an end-to-end enterprise platform for building, evaluating, and deploying mission-critical AI agents and applications. It provides a unified environment for orchestration, prompt engineering, RAG, evaluation, and monitoring, enabling teams to build reliable AI solutions 10x faster.
Braintrust Category
Braintrust Tag
Braintrust AI Tool Comparison
Braintrust Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!