Models
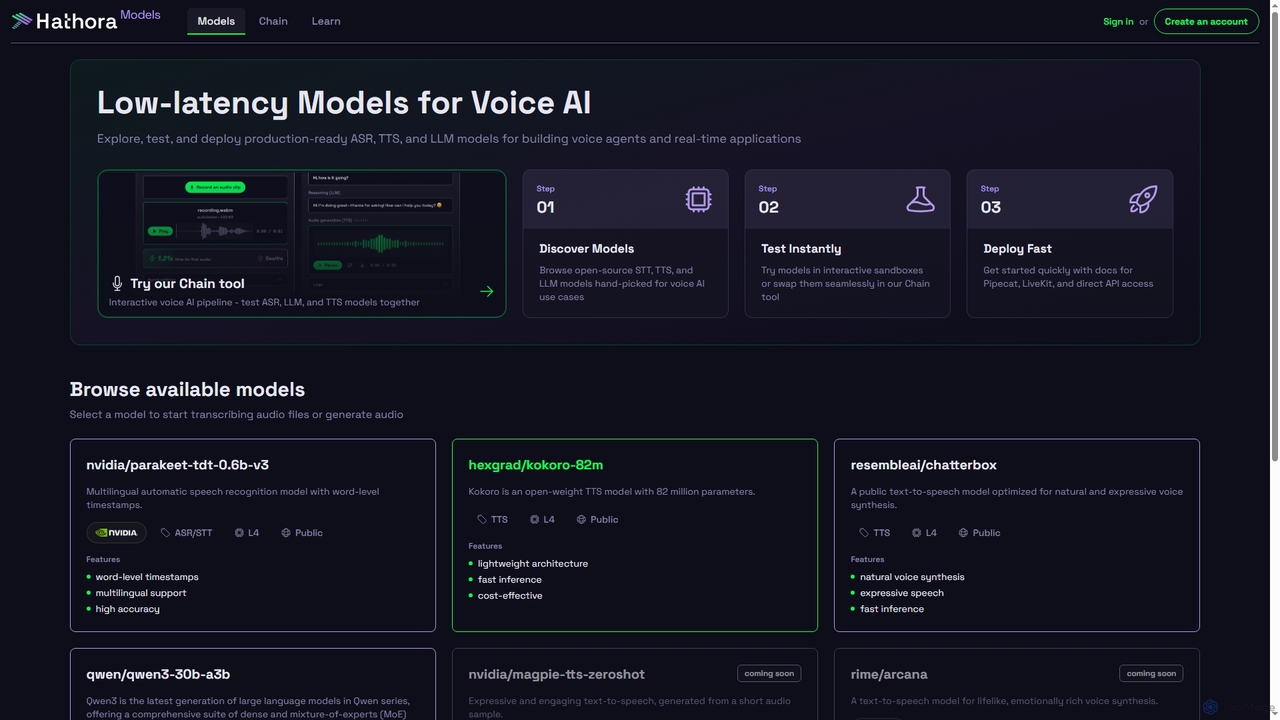
Models by Hathora offers a curated catalog of low-latency ASR, TTS, and LLM models optimized for voice AI …
Models by Hathora offers a curated catalog of low-latency ASR, TTS, and LLM models optimized for voice AI and real-time applications. Developers can explore, test, and deploy production-ready models quickly, featuring interactive sandboxes and direct API access for seamless integration into voice agents and other applications.
Zetic.ai
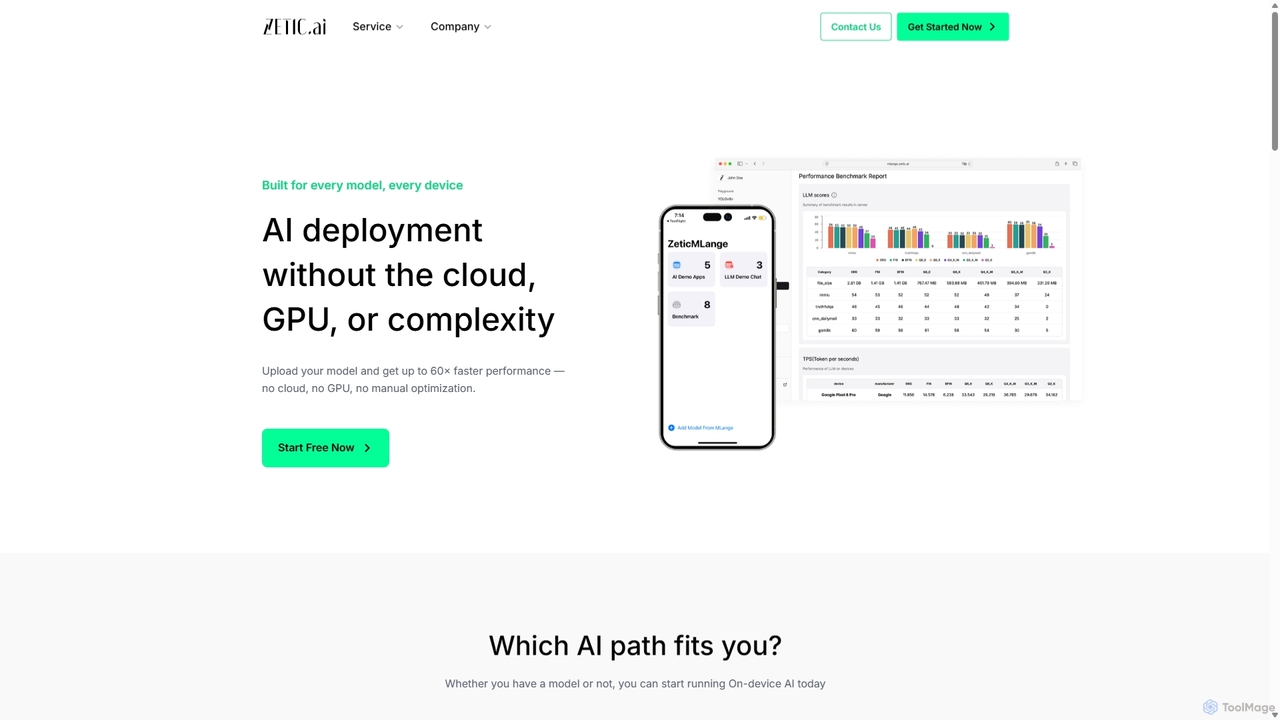
Zetic.ai is a platform that enables developers to deploy AI models directly on edge devices, eliminating the need …
Zetic.ai is a platform that enables developers to deploy AI models directly on edge devices, eliminating the need for expensive GPU servers. Its automated pipeline, ZETIC.MLange, optimizes and converts models for on-device execution, achieving up to 60x faster performance with NPU acceleration while ensuring data privacy and reducing latency.
ComfyDeploy
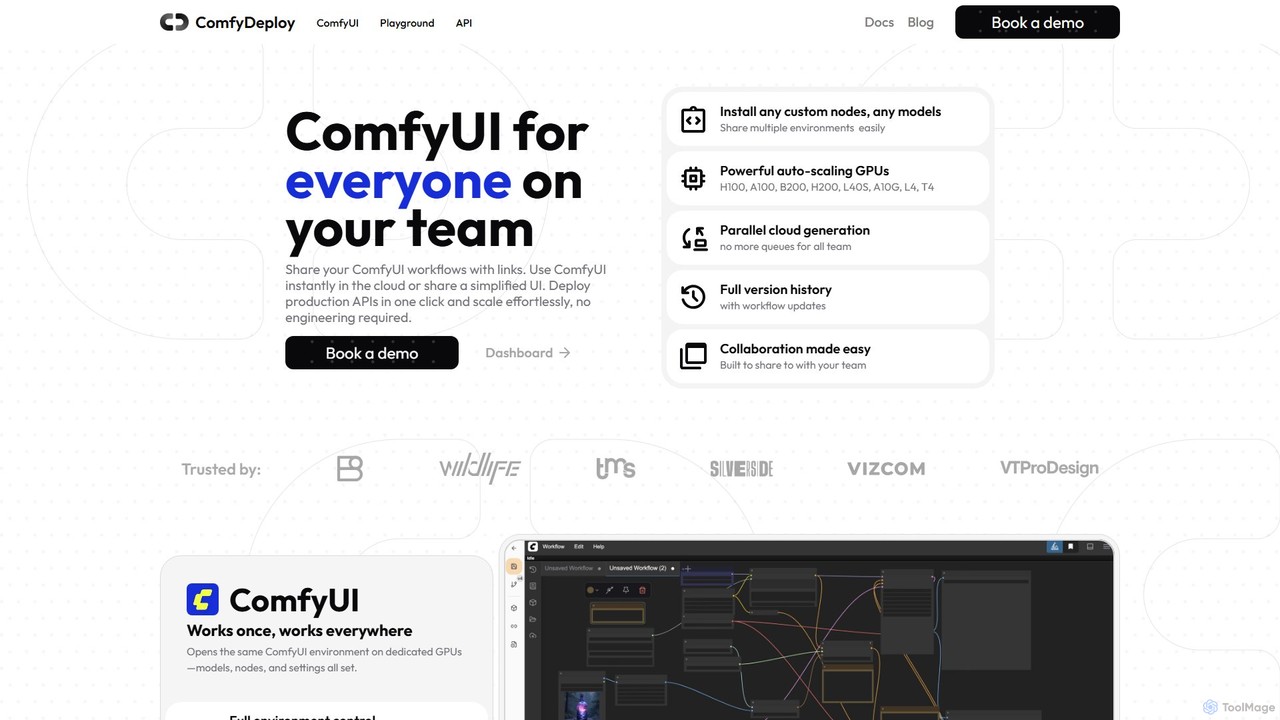
ComfyDeploy is a cloud platform for teams to build, share, and scale ComfyUI workflows. It enables one-click deployment …
ComfyDeploy is a cloud platform for teams to build, share, and scale ComfyUI workflows. It enables one-click deployment of production-ready APIs, provides auto-scaling GPU infrastructure, and offers simplified interfaces for non-technical users. Collaborate seamlessly, manage custom nodes and models, and turn complex creative processes into scalable applications without engineering overhead.
NVIDIA Build
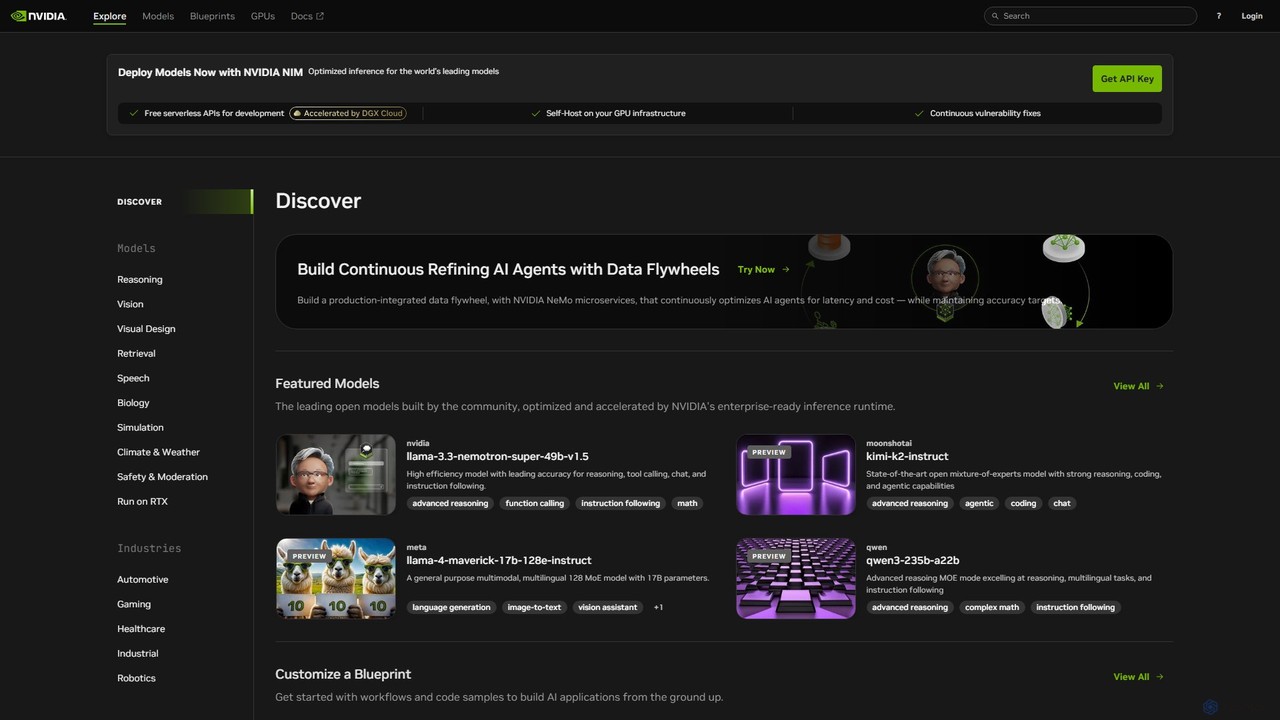
NVIDIA Build is a comprehensive platform for developers and enterprises to discover, customize, and deploy production-ready generative AI …
NVIDIA Build is a comprehensive platform for developers and enterprises to discover, customize, and deploy production-ready generative AI models. It features a vast catalog of optimized models, NVIDIA NIM microservices for high-performance inference, and application blueprints to accelerate development.
Fireworks AI
A high-performance platform for developers to build, customize, and scale generative AI applications. It offers an industry-leading fast …
A high-performance platform for developers to build, customize, and scale generative AI applications. It offers an industry-leading fast inference engine, advanced fine-tuning capabilities, and access to a wide range of open-source models, enabling real-time, cost-effective AI solutions.

hypermink
HyperMink provides Inferenceable, a free, open-source, and self-hostable AI inference server. Built on Node.js and llama.cpp, it allows …
HyperMink provides Inferenceable, a free, open-source, and self-hostable AI inference server. Built on Node.js and llama.cpp, it allows developers and businesses to run large language models locally, ensuring complete data privacy, control, and cost-effectiveness. Your AI, Your Rules.
About Model Deployment
Model Deployment tools are specialized platforms designed to take a trained machine learning model and make it operational in a live production environment. These tools automate the complex process of packaging the model, creating scalable API endpoints, and managing its lifecycle post-development. They provide the critical infrastructure for serving predictions to users or other applications reliably and efficiently. By handling tasks like server configuration, dependency management, and performance monitoring, they bridge the gap between data science research and real-world business value.
Core Features
- Automated API Generation: Instantly create secure and scalable REST API endpoints for any trained model, making it accessible to applications.
- Scalable Infrastructure Management: Automatically manage and scale computing resources (CPUs/GPUs) to handle fluctuating prediction request loads without manual intervention.
- Performance Monitoring & Logging: Track key metrics like latency, throughput, error rates, and resource utilization to ensure model health and reliability.
- Model Versioning & Rollbacks: Manage multiple versions of a model, perform A/B testing, and quickly roll back to a previous version if issues arise.
- Environment & Dependency Packaging: Package models and their specific software dependencies into reproducible containers (e.g., Docker) for consistent performance across environments.
Use Cases
These tools are essential for ML engineers, data scientists, and DevOps teams looking to productionize AI. They are widely used in industries like finance for real-time fraud detection, e-commerce for powering recommendation engines, healthcare for deploying diagnostic models, and SaaS for integrating AI features into products.
How to Choose
When selecting a Model Deployment tool, consider its support for your specific ML frameworks (like TensorFlow, PyTorch), its deployment targets (cloud, on-premise, or edge), and its auto-scaling capabilities. Also, evaluate the quality of its monitoring dashboards, integration with existing CI/CD pipelines (like Jenkins or GitHub Actions), and its security features for protecting models and data.
Model DeploymentUse Cases
Serving a Real-Time Fraud Detection Model
A financial technology company needs to deploy a machine learning model that scores transactions for fraud risk in milliseconds. Using a model deployment platform, their ML engineers package the trained model and create a low-latency API endpoint. This endpoint is integrated into their payment processing system. The platform automatically scales the infrastructure to handle peak transaction volumes, ensuring high availability and consistent response times, which is critical for preventing fraudulent transactions without impacting the user experience.
Powering an E-commerce Recommendation Engine
An online retailer wants to provide personalized product recommendations to shoppers. Their data science team builds a collaborative filtering model. They use a model deployment tool to host this model and expose it as an internal API. The e-commerce website calls this API for each user to fetch a list of recommended products. The tool's versioning feature allows them to safely roll out new versions of the recommendation model, A/B test their performance, and quickly revert if a new model decreases user engagement or sales.
Deploying a Computer Vision Model on Edge Devices
A manufacturing company uses computer vision for quality control on its assembly line. They need to deploy an object detection model on small, low-power devices directly on the factory floor for real-time analysis. A model deployment tool that supports edge deployments is used to optimize the model for the target hardware and package it with all necessary dependencies. This allows for low-latency defect detection directly at the source, reducing reliance on network connectivity to a central cloud server and enabling immediate action on the production line.
Integrating an NLP Model into a Customer Support Chatbot
A SaaS company wants to enhance its customer support with an AI-powered chatbot. After training a natural language processing (NLP) model to understand user queries, they use a deployment platform to host it. The platform provides a highly available API that the chatbot's front-end application communicates with. The tool's monitoring features are crucial for tracking the model's performance, identifying queries it fails to understand, and gathering data for future retraining cycles, creating a continuous improvement loop for the chatbot's accuracy.
A/B Testing Different Churn Prediction Models
A marketing analytics team develops two different models to predict customer churn. They are unsure which will perform better in a real-world scenario. Using a model deployment platform that supports traffic splitting, they deploy both models simultaneously. The platform routes 50% of the prediction requests to Model A and 50% to Model B. After a week of collecting live performance data, the team can confidently determine which model is more accurate and roll out the winning version to 100% of the traffic, optimizing their retention campaigns.
Offering a Proprietary AI Model as a Paid API Service
An AI startup has developed a unique generative model for creating music. To monetize their technology, they decide to offer it as a service via a paid API. They use a model deployment platform to host their model, generate a public API endpoint, and manage authentication and rate limiting for different subscription tiers. The platform's robust infrastructure ensures their service is reliable and can scale as their customer base grows, allowing them to focus on improving their core model technology instead of managing complex server infrastructure.