Datacurve
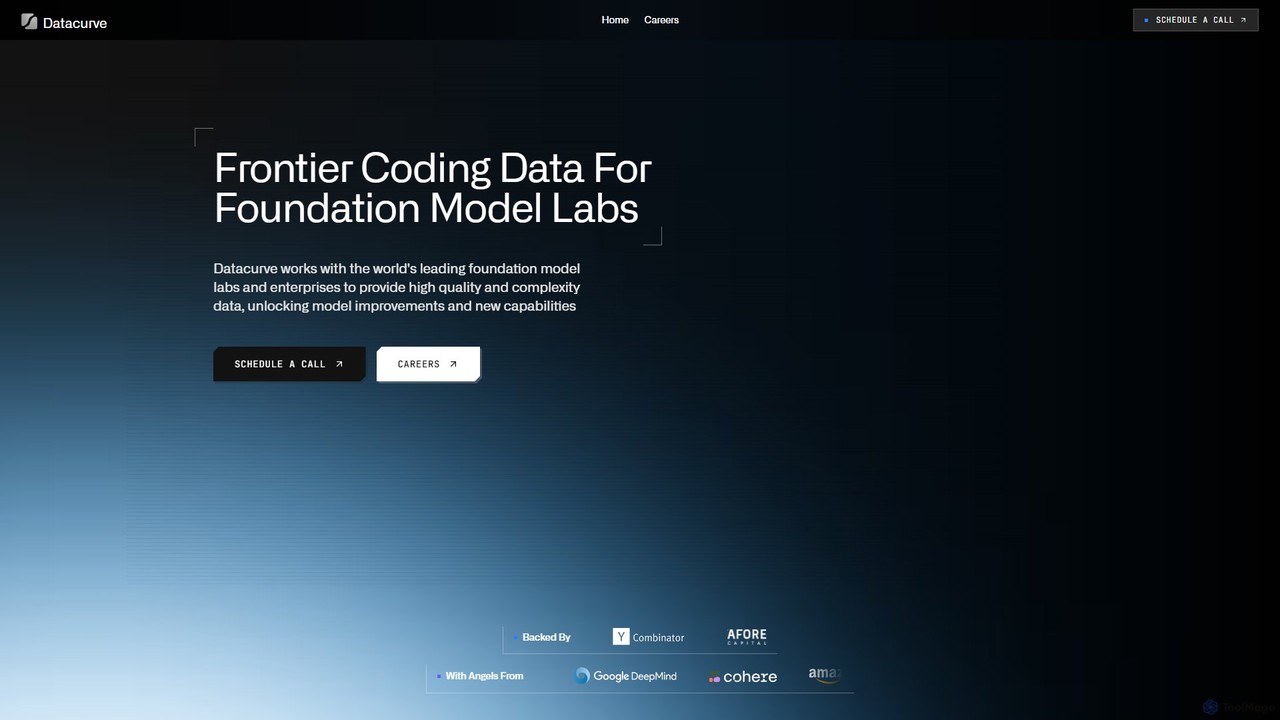
Datacurve provides high-quality, complex coding data for training and evaluating advanced AI foundation models. Specializing in formats like …
Datacurve provides high-quality, complex coding data for training and evaluating advanced AI foundation models. Specializing in formats like SFT, RLHF, and agentic workflow traces, they leverage a gamified platform with over 14,000 engineers to generate frontier data. Their service is designed for leading AI labs and enterprises seeking to unlock new model capabilities and improve performance through superior data quality, scale, and speed.
Forefront
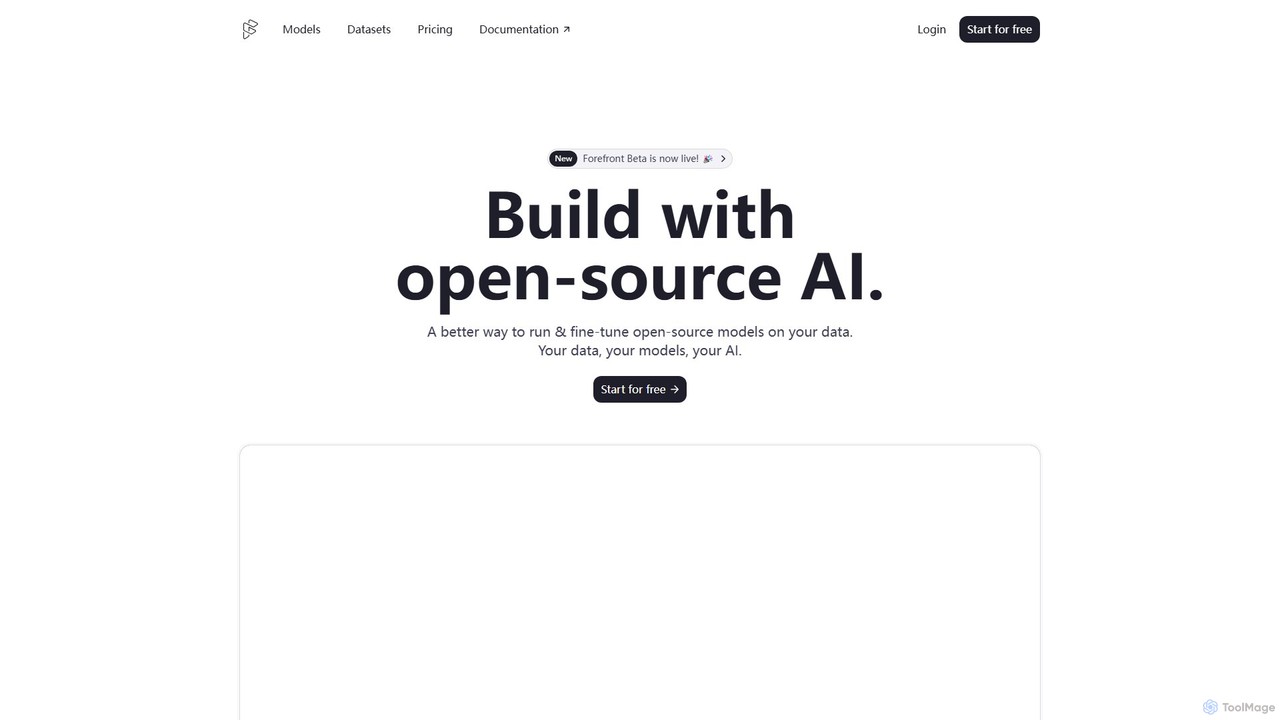
Forefront is a developer platform for building with open-source AI. It simplifies running, fine-tuning, and deploying large language …
Forefront is a developer platform for building with open-source AI. It simplifies running, fine-tuning, and deploying large language models (LLMs) on your private data, providing a scalable, secure, and cost-effective alternative to closed-source platforms. Own your data, your models, and your AI.
FinetuneDB
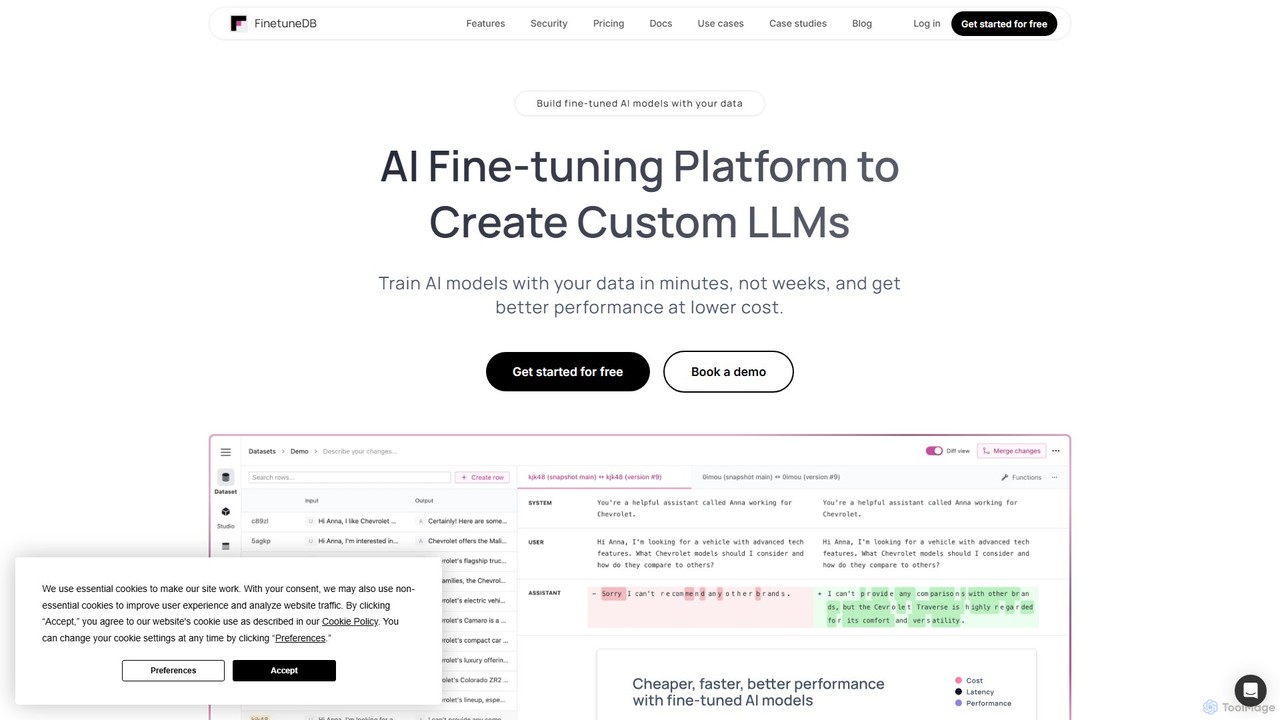
FinetuneDB is an all-in-one AI fine-tuning platform for developers. It simplifies the entire workflow of creating custom Large …
FinetuneDB is an all-in-one AI fine-tuning platform for developers. It simplifies the entire workflow of creating custom Large Language Models (LLMs), from building high-quality datasets and fine-tuning models like Llama 3 and GPT-4o mini, to deployment and continuous evaluation on a single, secure platform.
Ocular AI
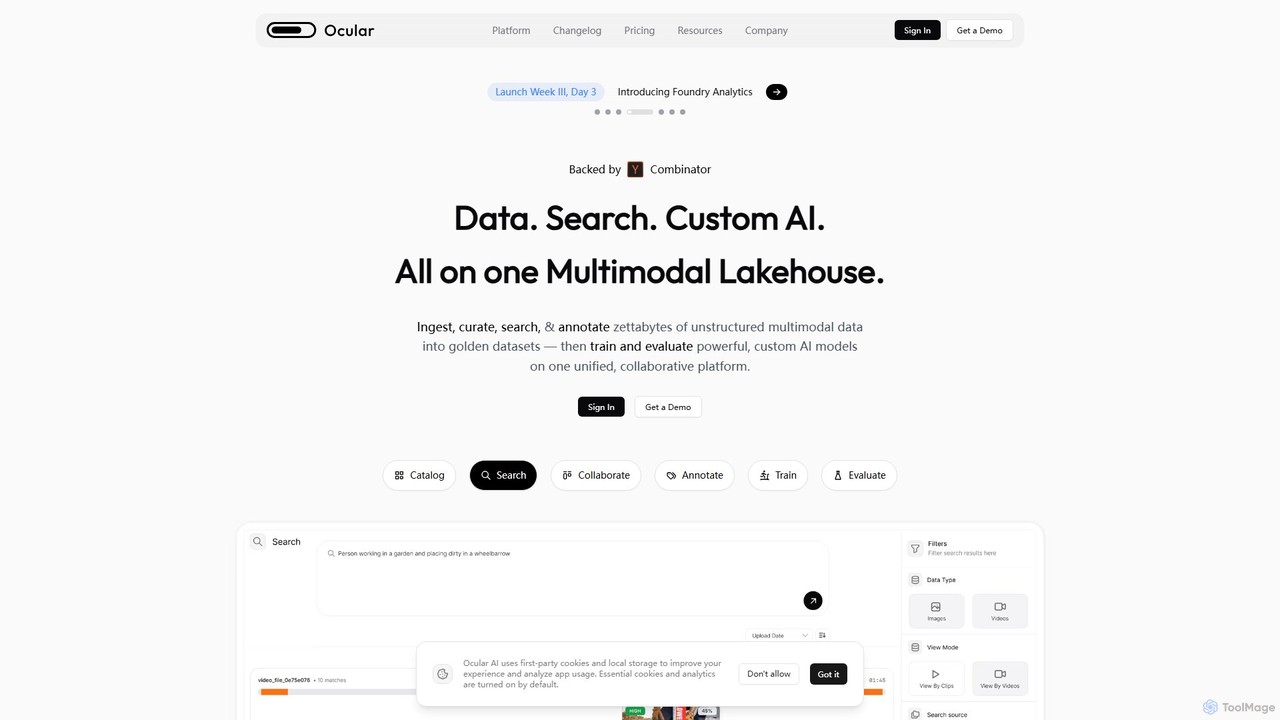
Ocular AI is an end-to-end platform for the multimodal AI era, enabling teams to ingest, curate, search, and …
Ocular AI is an end-to-end platform for the multimodal AI era, enabling teams to ingest, curate, search, and annotate zettabytes of unstructured data. It provides a unified multimodal lakehouse, advanced search, and tools for training and evaluating custom AI models, accelerating the entire AI development lifecycle.
Surge AI
Surge AI is a premier data labeling platform that provides elite human intelligence to power the development of …
Surge AI is a premier data labeling platform that provides elite human intelligence to power the development of advanced AI and AGI. Specializing in high-quality data for RLHF, model evaluation, and custom dataset creation, Surge AI partners with leading AI labs like OpenAI and Anthropic to train, align, and test next-generation models. They focus on the nuance and complexity required to build truly intelligent systems.
MonsterAPI
MonsterAPI is a developer-centric platform that simplifies the fine-tuning and deployment of open-source generative AI models. It offers …
MonsterAPI is a developer-centric platform that simplifies the fine-tuning and deployment of open-source generative AI models. It offers a no-code chat interface, MonsterGPT, to manage complex tasks, supporting models like Llama, SDXL, and Whisper. The platform provides scalable API endpoints and enterprise-grade GPU infrastructure at a fraction of the typical cost and time, making advanced AI accessible to all developers.
prompteasy.ai
prompteasy.ai is a no-code platform that simplifies the fine-tuning of GPT models. By chatting with an AI assistant, …
prompteasy.ai is a no-code platform that simplifies the fine-tuning of GPT models. By chatting with an AI assistant, users can generate custom datasets tailored to their specific needs, such as copywriting or sentiment analysis, without any technical skills. This makes advanced AI customization accessible to everyone.
About Model Training
Model Training tools are specialized developer platforms for building, training, and optimizing machine learning models. They provide a structured environment for managing datasets, running experiments, and tracking performance metrics to improve model accuracy. These tools are essential for creating custom AI solutions, from fine-tuning language models to developing predictive analytics systems. They streamline the iterative process of machine learning development, enabling data scientists and engineers to build more robust and effective models faster.
Core Features
- Experiment Tracking: Log, compare, and visualize metrics like loss and accuracy across multiple training runs.
- Data & Model Versioning: Manage different versions of datasets and trained models to ensure reproducibility.
- Hyperparameter Optimization: Automate the search for the best model configurations to maximize performance.
- Distributed Training Support: Scale training across multiple GPUs or cloud instances to handle large datasets.
- Framework Integration: Seamlessly connect with popular ML frameworks like TensorFlow, PyTorch, and JAX.
Use Cases
These tools are widely used by ML engineers, data scientists, and researchers in fields like computer vision, natural language processing (NLP), and finance. They are crucial for tasks such as creating custom object detection models, fine-tuning large language models for specific domains, or building fraud detection systems.
How to Choose
When selecting a Model Training tool, consider its support for your preferred ML frameworks, its scalability for large-scale training, and its collaboration features for team-based projects. Also, evaluate the ease of use (code-first vs. low-code), integration with your existing data infrastructure, and the pricing model based on compute usage.
Model TrainingUse Cases
Fine-tuning a Language Model for Customer Service
An ML team at a SaaS company uses a model training platform to fine-tune a pre-trained language model on their internal knowledge base and past support tickets. The platform allows them to track experiments with different learning rates and datasets. The final model is integrated into their helpdesk to provide instant, context-aware answers to customer queries, reducing response times by 70% and freeing up human agents for more complex issues.
Training a Custom Computer Vision Model
A retail company wants to automate inventory checks using security camera footage. A data scientist uses a model training tool to manage a dataset of product images and train a custom object detection model. The platform's experiment tracking helps them compare the performance of different model architectures and data augmentation techniques. The resulting model can accurately identify and count products on shelves, automating a previously manual process.
Developing a Predictive Analytics Model for Churn
A financial services firm aims to predict customer churn. Analysts use a model training platform to train a gradient boosting model on historical customer data. The tool's versioning capabilities ensure that both the data and the model are reproducible for auditing purposes. The trained model identifies at-risk customers with high accuracy, allowing the marketing team to launch targeted retention campaigns and reduce overall churn rate.
Building a Personalized Recommendation Engine
An e-commerce platform developer trains a collaborative filtering model to provide personalized product recommendations. They use a model training tool to manage user interaction data and run distributed training jobs on a cloud GPU cluster. The platform simplifies the process of scaling the training, enabling them to retrain the model daily with fresh data to keep recommendations relevant and increase user engagement.
Tracking and Comparing ML Research Experiments
A university research group is exploring new neural network architectures for medical image analysis. They use a model training platform as a centralized hub to log every experiment, including code versions, hyperparameters, and output metrics. This allows researchers to easily compare results, share findings with collaborators, and reproduce successful experiments, significantly accelerating the pace of their research and ensuring scientific rigor.
Automating Hyperparameter Tuning for Optimal Performance
An ML engineer is tasked with optimizing a fraud detection model. Instead of manually testing hundreds of parameter combinations, they use a model training tool's automated hyperparameter tuning feature. They define the search space for parameters like learning rate and tree depth, and the platform automatically runs experiments to find the optimal configuration. This saves days of manual work and results in a model with significantly higher accuracy and lower false positives.