llm_price
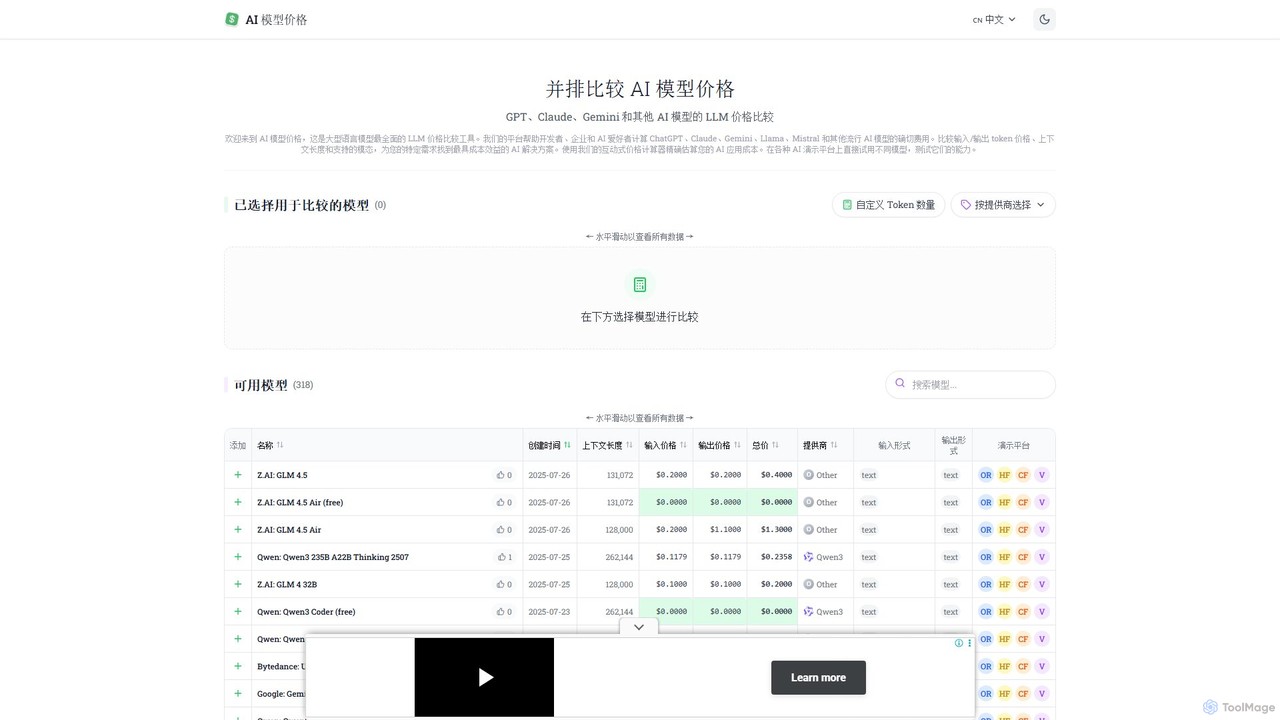
llm_price is a comprehensive comparison tool for Large Language Model (LLM) API pricing. It enables developers, businesses, and …
llm_price is a comprehensive comparison tool for Large Language Model (LLM) API pricing. It enables developers, businesses, and AI enthusiasts to easily compare the costs of hundreds of models from providers like OpenAI, Google, Anthropic, and Mistral. With an interactive cost calculator and side-by-side analysis of token prices, context lengths, and modalities, it simplifies the process of selecting the most cost-effective AI solution for any project.

abcdindex
abcdindex (Academic Business Current Data Index) is a free, comprehensive platform for the academic community. It provides a …
abcdindex (Academic Business Current Data Index) is a free, comprehensive platform for the academic community. It provides a verified and structured database of international journals, research papers, funding opportunities, scholarships, and other scholarly resources. The platform aims to help researchers, students, and publishers efficiently navigate the academic landscape and avoid predatory or inactive publications by offering reliable, centralized information.
About Database
AI Databases are curated collections of structured data that serve as the fundamental resource for training, testing, and deploying artificial intelligence models. These resources are specifically prepared for machine consumption, often containing vast amounts of labeled or unlabeled data like images, text, or numerical figures. They provide the essential raw material for machine learning, natural language processing, and computer vision tasks. The quality, scale, and relevance of these databases directly determine the performance and capabilities of an AI system.
Core Features
- Structured & Labeled Data: Data is organized and often annotated with labels, making it suitable for supervised learning algorithms.
- Large Scale: Typically contain millions or even billions of data points to ensure models can learn generalizable patterns.
- Domain Specificity: Focused on particular fields such as medicine, finance, or autonomous driving to build specialized AI.
- Data Quality & Consistency: Cleaned and validated to minimize noise and biases, which is crucial for building reliable models.
Use Cases
AI Databases are essential for data scientists, machine learning engineers, and researchers. They are used to train facial recognition systems with image datasets, develop language models using massive text corpora, and build fraud detection algorithms from historical transaction data. Academic institutions also use standardized datasets to benchmark the performance of new AI algorithms.
How to Choose
When selecting an AI Database, consider its relevance to your specific problem domain. Evaluate the data quality, the accuracy of its labels, and the presence of potential biases. Check the licensing terms to ensure it can be used for your intended purpose (e.g., academic vs. commercial). Finally, assess the data format and size to confirm compatibility with your computational resources and toolchain.
DatabaseUse Cases
Training a Medical Image Analysis Model
An AI researcher in the healthcare sector needs to develop a model that can detect early signs of diseases from medical scans like X-rays or MRIs. They use a specialized, high-quality database of thousands of anonymized medical images, each meticulously annotated by radiologists. By training a computer vision model on this dataset, the system learns to identify subtle patterns associated with specific conditions. The resulting AI tool can assist radiologists by highlighting potential areas of concern, leading to faster and more accurate diagnoses.
Developing a Natural Language Processing (NLP) Model
A data science team is tasked with building a sentiment analysis tool for customer reviews. To achieve this, they leverage a large-scale text database containing millions of product reviews, each labeled as positive, negative, or neutral. This corpus serves as the ground truth for training their NLP model. The model processes the text, learns the nuances of language, and identifies patterns that correlate with different sentiments. After training, the tool can automatically classify new, unseen reviews, providing the business with valuable insights into customer satisfaction at scale.
Building a Financial Fraud Detection System
A fintech company aims to reduce fraudulent transactions for its users. Their machine learning engineers use a massive, historical database of transaction data. This database includes features like transaction amount, time, location, and merchant type, with each transaction labeled as either legitimate or fraudulent. By training an anomaly detection model on this data, the system learns the characteristics of normal transactional behavior. When a new transaction occurs, the model can predict the probability of it being fraudulent in real-time, allowing the company to block suspicious activities and protect its customers.
Benchmarking New AI Algorithms
An academic research lab develops a novel algorithm for object recognition. To prove its effectiveness, they must compare its performance against existing state-of-the-art methods. They use a standardized, public database like ImageNet or COCO, which are widely accepted in the research community for benchmarking. By running their new algorithm and established ones on the same dataset, they can obtain objective metrics like accuracy and processing speed. This allows them to publish their findings with verifiable results, contributing to the advancement of the AI field.
Powering a Knowledge-Based Q&A System
A legal tech firm wants to create an AI assistant that can answer complex legal questions. Instead of a general text corpus, they use a specialized knowledge base—a structured database containing legal statutes, case law, and scholarly articles, all interconnected through a knowledge graph. When a lawyer poses a question, the AI doesn't just search for keywords; it navigates this graph to understand relationships and context. This allows the system to provide highly accurate, context-aware answers supported by specific legal citations, acting as a powerful research tool for legal professionals.
Creating Synthetic Data for AI Model Testing
An AI development team is building a self-driving car system but lacks sufficient real-world data for rare edge cases, like animals suddenly crossing the road. They use a foundational database of driving scenarios to generate vast amounts of realistic, synthetic data. This process allows them to create thousands of variations of a single scenario, altering weather conditions, lighting, and object speeds. By testing their model against this comprehensive synthetic database, they can ensure the AI is robust and reliable in situations that are too dangerous or infrequent to capture in reality, all without compromising user privacy.