
deepchecks
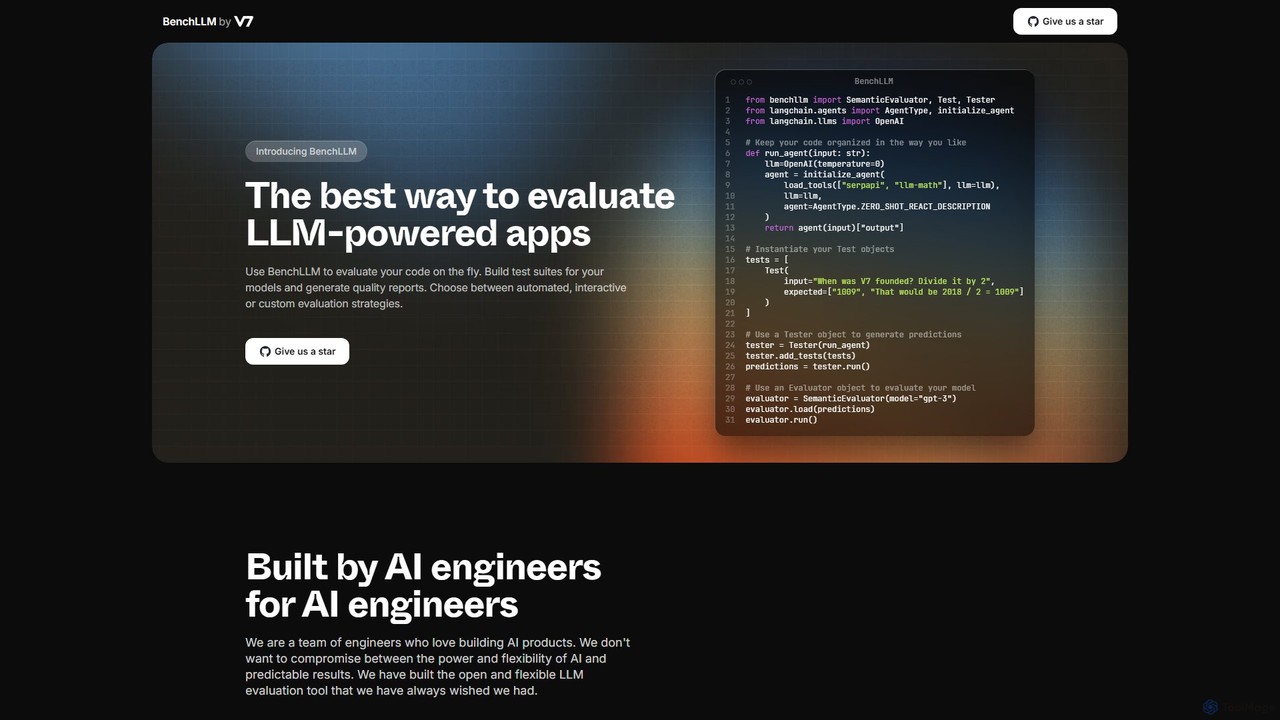
Deepchecks 是一個用於評估、驗證和監控基於 LLM 的應用程式的端到端平台。它幫助人工智慧團隊定義、衡量和驗證人工智慧的進展,透過簡化從開發、CI/CD 到生產的整個測試流程,確保發布高品質、可靠的應用程式。
Deepchecks 是一個用於評估、驗證和監控基於 LLM 的應用程式的端到端平台。它幫助人工智慧團隊定義、衡量和驗證人工智慧的進展,透過簡化從開發、CI/CD 到生產的整個測試流程,確保發布高品質、可靠的應用程式。

Prompt Octopus
一款專為開發者設計的VSCode擴充功能,旨在簡化提示詞工程。它支援在程式碼庫中直接並排比較超過40種LLM(如OpenAI、Anthropic、Mistral)的回應,幫助您高效地為任何任務找到最佳模型。
一款專為開發者設計的VSCode擴充功能,旨在簡化提示詞工程。它支援在程式碼庫中直接並排比較超過40種LLM(如OpenAI、Anthropic、Mistral)的回應,幫助您高效地為任何任務找到最佳模型。

Ragas
Ragas 是一個用於評估和測試檢索增強生成(RAG)流程的開源 Python 框架。它提供了一套度量標準來衡量 LLM 應用的性能,從上下文檢索到答案生成。Ragas 受到 LangChain 和 LlamaIndex 等行業領導者的信賴,透過識別和減輕幻覺、不相關響應等問題,幫助開發者建構更穩健、可靠和準確的 AI 系統。
Ragas 是一個用於評估和測試檢索增強生成(RAG)流程的開源 Python 框架。它提供了一套度量標準來衡量 LLM 應用的性能,從上下文檢索到答案生成。Ragas 受到 LangChain 和 LlamaIndex 等行業領導者的信賴,透過識別和減輕幻覺、不相關響應等問題,幫助開發者建構更穩健、可靠和準確的 AI 系統。
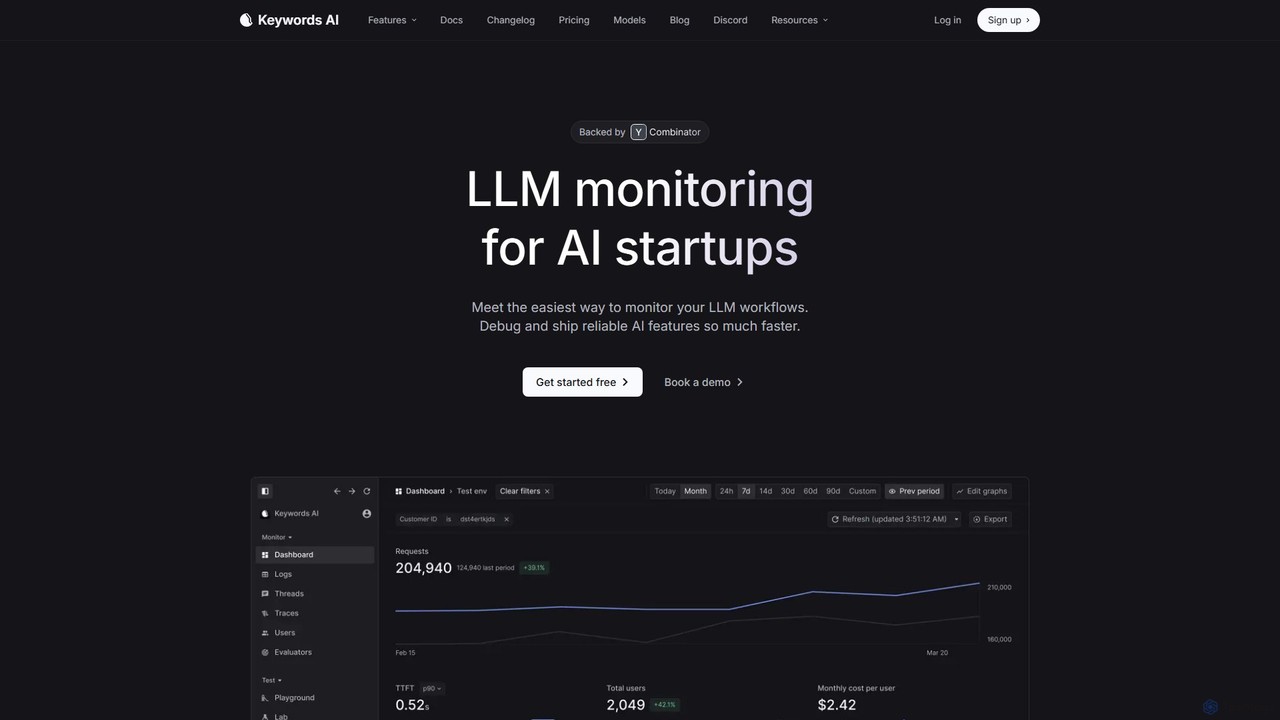
Keywords AI
Keywords AI 是一個專為AI新創公司和開發者設計的全面LLM可觀測性與監控平台。它提供統一的API來部署、測試、監控和優化LLM工作流程,支援超過200種模型,透過簡單的兩行程式碼整合,幫助團隊更快地建構和發布可靠的AI功能。
Keywords AI 是一個專為AI新創公司和開發者設計的全面LLM可觀測性與監控平台。它提供統一的API來部署、測試、監控和優化LLM工作流程,支援超過200種模型,透過簡單的兩行程式碼整合,幫助團隊更快地建構和發布可靠的AI功能。
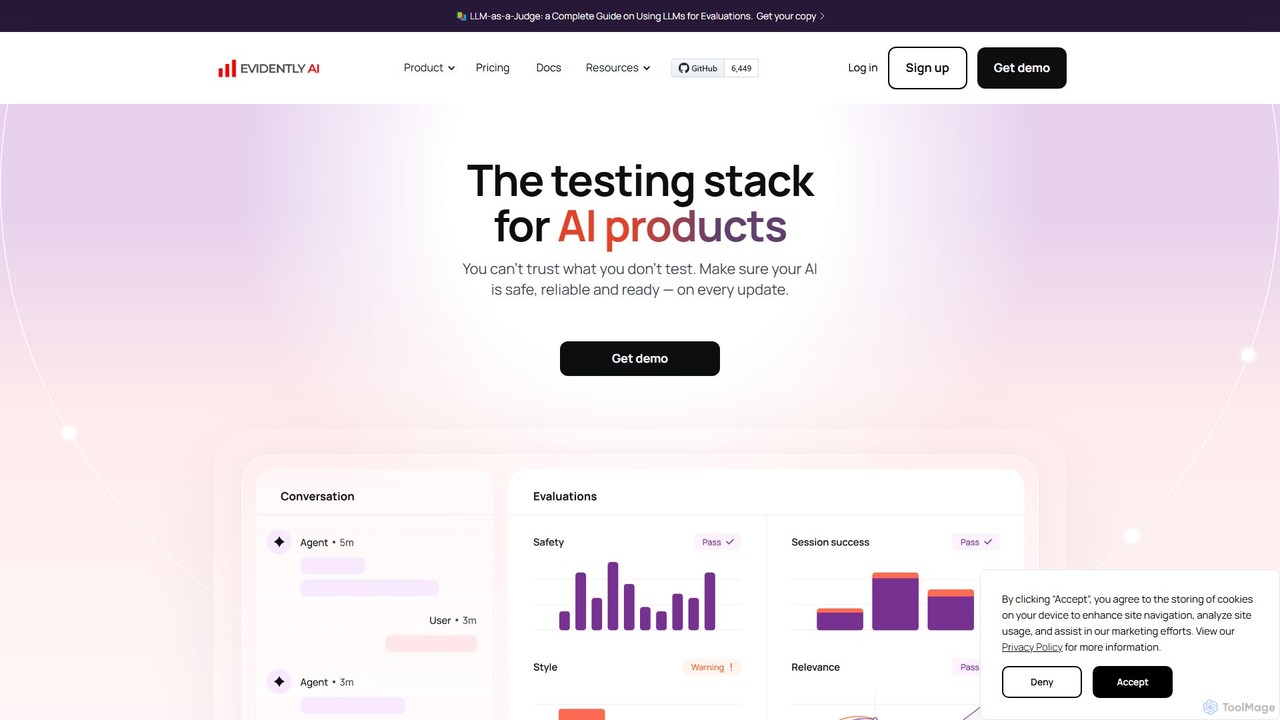
Evidently AI
Evidently AI 是一個面向AI產品的綜合性測試與評估平台,專注於LLM和ML模型的監控。它透過自動化評估、合成數據生成、持續測試和對抗性攻擊,幫助團隊確保AI的安全性、可靠性和性能。該平台基於一個強大的開源庫建構,專為數據科學家和MLOps工程師設計,用於在問題影響用戶前檢測幻覺、數據漂移和PII洩漏等問題。
Evidently AI 是一個面向AI產品的綜合性測試與評估平台,專注於LLM和ML模型的監控。它透過自動化評估、合成數據生成、持續測試和對抗性攻擊,幫助團隊確保AI的安全性、可靠性和性能。該平台基於一個強大的開源庫建構,專為數據科學家和MLOps工程師設計,用於在問題影響用戶前檢測幻覺、數據漂移和PII洩漏等問題。

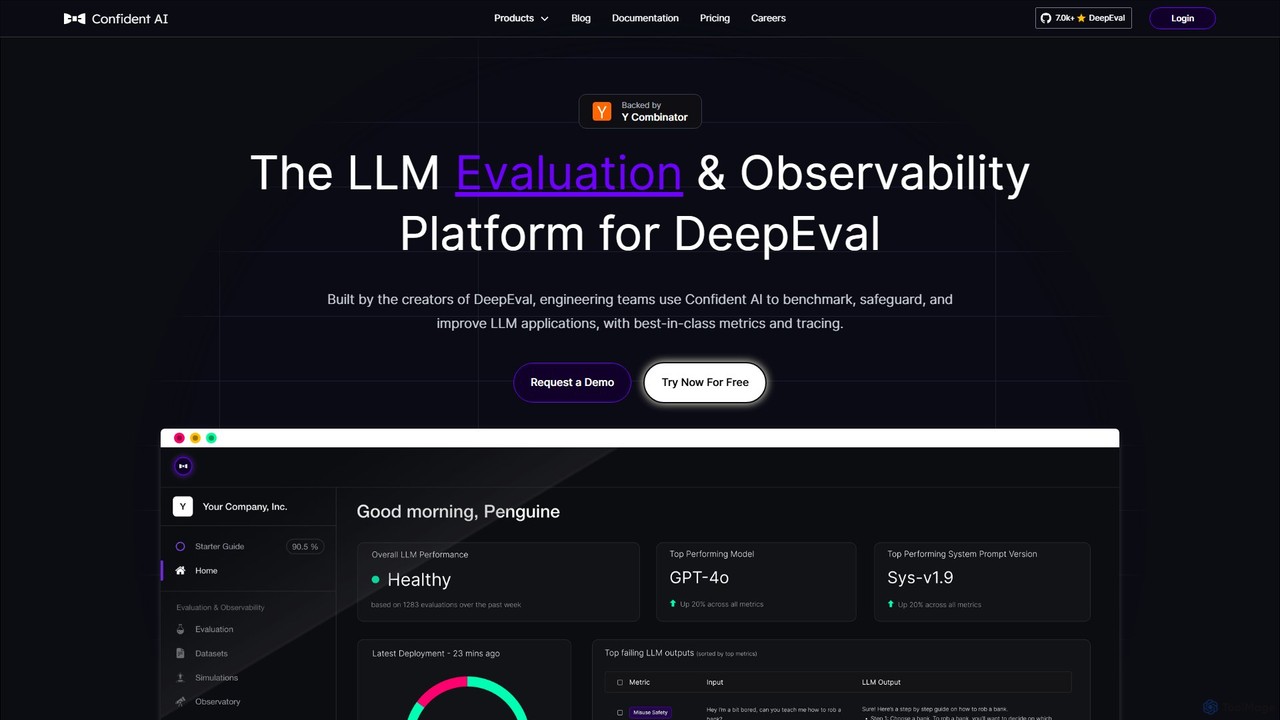
Confident AI
Confident AI 是一個面向工程團隊的 LLM 評估與可觀測性平台。由開源庫 DeepEval 的創建者打造,它透過全面的指標、回歸測試和詳細的追蹤來幫助基準測試、保障和改進 LLM 應用,確保 AI 效能的穩定性。
Confident AI 是一個面向工程團隊的 LLM 評估與可觀測性平台。由開源庫 DeepEval 的創建者打造,它透過全面的指標、回歸測試和詳細的追蹤來幫助基準測試、保障和改進 LLM 應用,確保 AI 效能的穩定性。
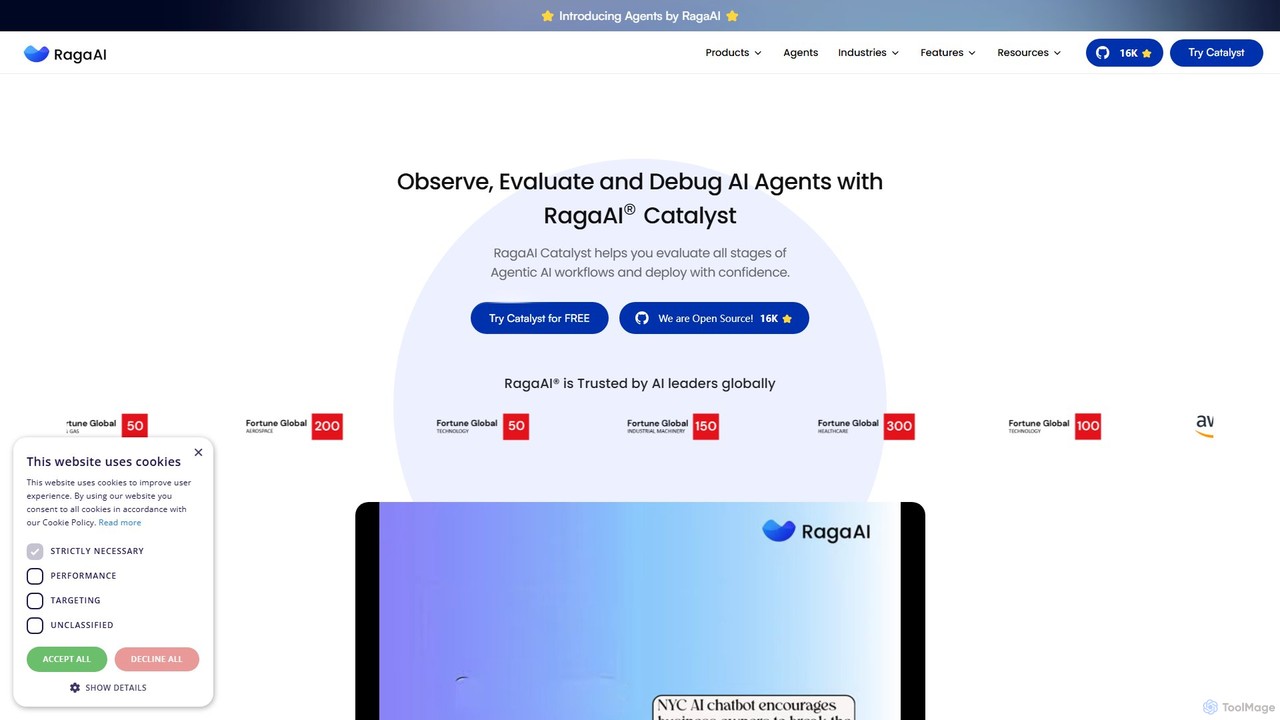
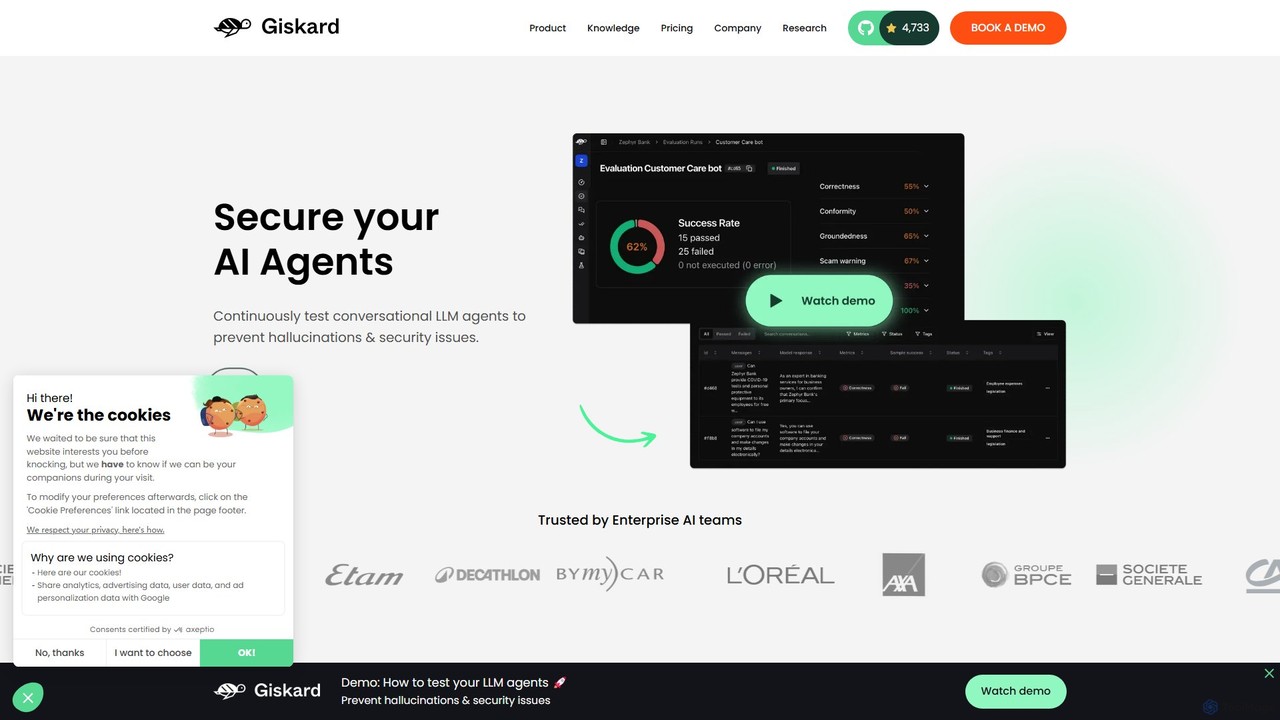
RagaAI
RagaAI 是一個全面的人工智慧測試與可觀測性平台,旨在協助開發者和企業建構可靠的 AI 應用。它提供了一整套工具,用於觀察、評估和偵錯 AI 代理、大型語言模型(LLM)和 RAG 系統。核心功能包括代理測試、即時護欄、合成資料生成和微調能力。RagaAI 支援多模態資料(LLM、電腦視覺、表格資料),致力於自動化整個 AI 品質保證生命週期,從問題偵測到解決,確保 AI 部署的穩健性和可信度。
RagaAI 是一個全面的人工智慧測試與可觀測性平台,旨在協助開發者和企業建構可靠的 AI 應用。它提供了一整套工具,用於觀察、評估和偵錯 AI 代理、大型語言模型(LLM)和 RAG 系統。核心功能包括代理測試、即時護欄、合成資料生成和微調能力。RagaAI 支援多模態資料(LLM、電腦視覺、表格資料),致力於自動化整個 AI 品質保證生命週期,從問題偵測到解決,確保 AI 部署的穩健性和可信度。
AfterQuery
AfterQuery是一家AI研究實驗室,致力於透過創建高品質、人工生成的訓練資料集和無污染的基準測試來推動基礎模型的發展。它專注於透過卓越的訓練數據和嚴格的評估來提升模型性能。
AfterQuery是一家AI研究實驗室,致力於透過創建高品質、人工生成的訓練資料集和無污染的基準測試來推動基礎模型的發展。它專注於透過卓越的訓練數據和嚴格的評估來提升模型性能。
promptfoo
promptfoo 是一個全面性的大型語言模型(LLM)測試與評估框架。它協助開發者和企業透過系統性測試、基準評估和AI驅動的紅隊演練,來比較提示詞品質、評估模型效能並增強AI安全性。它支援超過50家LLM供應商,包括本地模型,並提供對開發者友善的CLI,可無縫整合至開發工作流程中。
promptfoo 是一個全面性的大型語言模型(LLM)測試與評估框架。它協助開發者和企業透過系統性測試、基準評估和AI驅動的紅隊演練,來比較提示詞品質、評估模型效能並增強AI安全性。它支援超過50家LLM供應商,包括本地模型,並提供對開發者友善的CLI,可無縫整合至開發工作流程中。