
Kite
Kite is a powerful screen recorder for Mac that helps you create stunning, professional-grade product demo videos in …
Kite is a powerful screen recorder for Mac that helps you create stunning, professional-grade product demo videos in minutes. It combines screen recording with AI-powered features like automatic zoom, 3D animations, AI voiceovers, and a music library to make your videos look as polished as an Apple commercial.
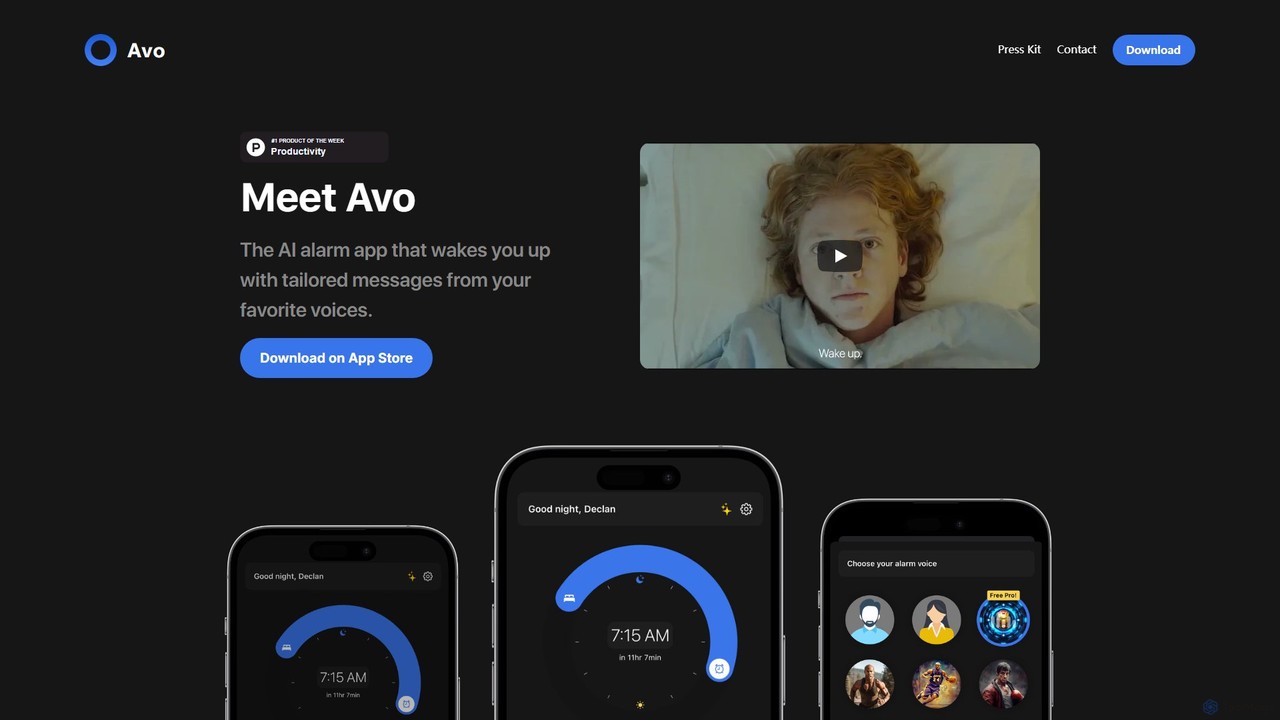
avoalarm
Avoalarm is a revolutionary AI alarm clock app that wakes you up with personalized voice messages from your …
Avoalarm is a revolutionary AI alarm clock app that wakes you up with personalized voice messages from your favorite celebrities and characters. It integrates with your calendar, weather, and news to deliver a unique, informative, and motivating start to your day.
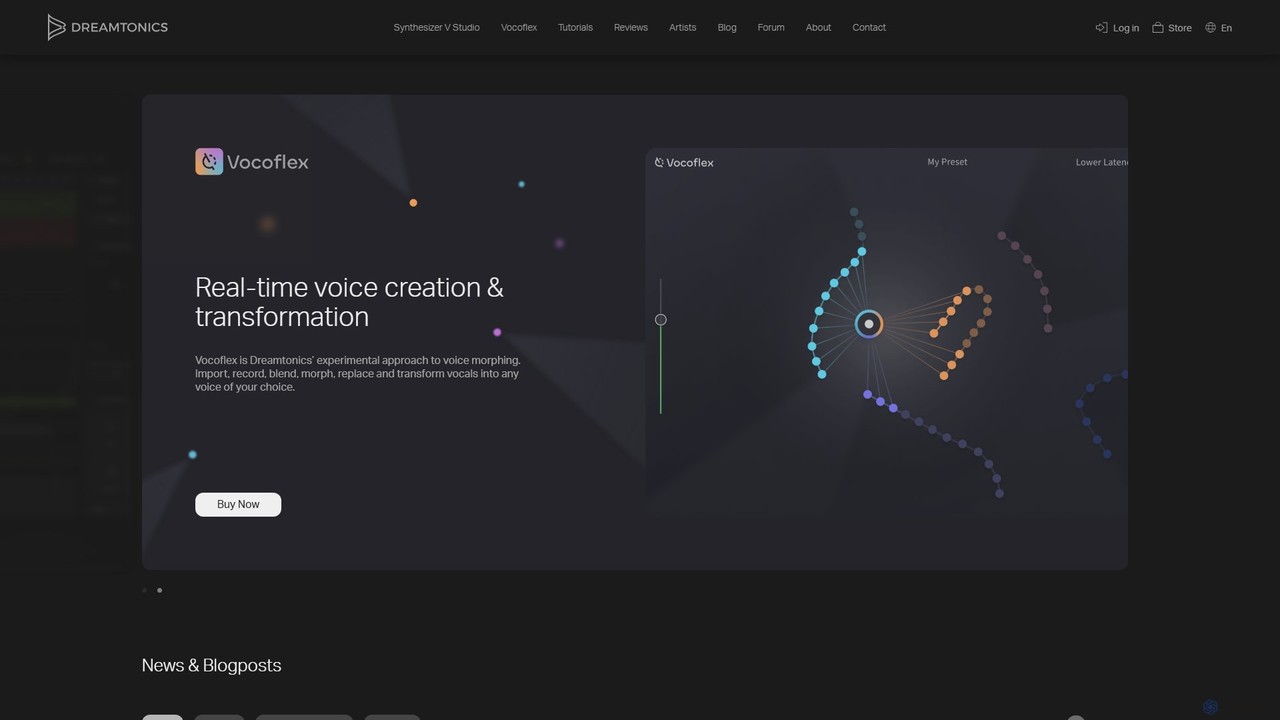
Dreamtonics
Dreamtonics offers advanced AI-powered vocal production tools, including Synthesizer V Studio for creating hyper-realistic singing vocals from text …
Dreamtonics offers advanced AI-powered vocal production tools, including Synthesizer V Studio for creating hyper-realistic singing vocals from text and melodies, and Vocoflex for real-time voice morphing. These tools are designed for music producers, composers, and artists, providing unparalleled control and realism in synthetic vocal creation.
About Voice Synthesis
Voice Synthesis tools are a class of AI-powered software that convert written text into audible, human-like speech. These tools utilize advanced deep learning models, known as Text-to-Speech (TTS) engines, to analyze text and generate realistic audio with natural intonation, pacing, and emotion. Their primary value is in creating high-quality voiceovers and audio content efficiently without the need for microphones, recording artists, or studios. This technology enables scalable audio production for everything from video narration to accessibility features.
Core Features
- Text-to-Speech (TTS) Conversion: The fundamental ability to transform text input into spoken audio files, typically in formats like MP3 or WAV.
- Voice Cloning: Allows users to create a digital replica of a specific voice from a short audio sample, enabling consistent and personalized narration.
- Multi-Language and Accent Support: Offers a wide library of pre-built voices in numerous languages and regional accents for global content creation.
- Prosody and Emotional Control: Provides fine-grained control over speech characteristics such as pitch, speed, volume, and emotional tone (e.g., happy, sad, excited).
- SSML Support: Utilizes Speech Synthesis Markup Language (SSML) for advanced customization, allowing developers to precisely control pronunciation, pauses, and emphasis.
Use Cases
Voice Synthesis tools are widely adopted by content creators for producing YouTube video voiceovers, podcasts, and audiobooks. In business, they are used to create professional narration for e-learning modules, corporate training videos, and marketing materials. Developers also integrate these tools via APIs to power interactive voice response (IVR) systems, in-app assistants, and accessibility functions like screen readers for visually impaired users.
How to Choose
When selecting a Voice Synthesis tool, first evaluate the voice quality and realism—listen to samples to ensure they meet your standards. Consider the range of customization options, including the ability to control emotion and clone voices. Assess the library of available languages and accents to ensure it covers your target audience. Finally, examine the integration capabilities (API access) and the pricing model (e.g., per-character, subscription) to find a solution that fits your technical needs and budget.
Voice SynthesisUse Cases
Creating Voiceovers for Video Content
Content creators, such as YouTubers and marketing teams, frequently use voice synthesis to produce clear and consistent narration for their videos. Instead of spending time and money on recording equipment and voice actors, they can simply type or paste a script into the tool. They can then select a suitable voice, adjust the pacing and tone to match the video's mood, and generate a high-quality audio file in minutes. This process significantly speeds up production workflows and allows for easy edits; if the script changes, they can regenerate the audio instantly without needing a re-recording session.
Developing Interactive Voice Response (IVR) Systems
Businesses and developers use voice synthesis APIs to build more natural and engaging IVR systems for customer support. Instead of using robotic, pre-recorded prompts, they can generate dynamic, human-like responses in real-time. For example, the system can address a caller by name or read out specific account information using a pleasant and clear voice. This improves the customer experience by making interactions feel more personal and less frustrating. It also allows for easy updates to call flows and scripts without needing to re-record every audio prompt manually.
Producing Audiobooks and E-Learning Content
Instructional designers and independent authors leverage voice synthesis to convert written materials into engaging audio formats. An author can turn their e-book into an audiobook without the high cost of hiring a professional narrator. Similarly, a corporate trainer can create narrated e-learning modules for employees. Using voice cloning features, they can even use a digital version of their own voice for a personal touch. This makes content more accessible and allows people to learn on the go, listening during commutes or exercise.
Creating Accessibility Features
Web developers and software engineers use voice synthesis to make digital products more accessible to users with visual impairments or reading disabilities. By integrating a TTS engine, a website or application can offer a 'read aloud' feature that converts on-screen text into speech. This allows users to consume articles, notifications, and interface instructions audibly. High-quality synthetic voices are crucial here, as a natural-sounding voice reduces listening fatigue and makes the experience more pleasant and effective for the user.
Prototyping Voice User Interfaces (VUIs)
Designers and developers creating voice-activated applications, such as smart assistants or in-car systems, use voice synthesis for rapid prototyping. Instead of recording placeholder audio for every possible interaction, they can use a TTS tool to generate responses on the fly. This allows them to quickly test conversation flows, user commands, and system feedback. They can experiment with different voices, tones, and wording to find the most effective user experience before committing to final audio production, saving significant time and resources in the design phase.
Generating Dynamic In-Game Character Dialogue
Game developers are increasingly using voice synthesis to create dialogue for non-player characters (NPCs). This is especially useful for games with vast amounts of text, such as role-playing games (RPGs), where recording every line with voice actors would be prohibitively expensive. With TTS, developers can give a voice to every NPC, making the game world feel more alive and immersive. Advanced tools can even generate dialogue with specific emotional tones based on in-game events, creating a more dynamic and responsive experience for the player.