
deepchecks
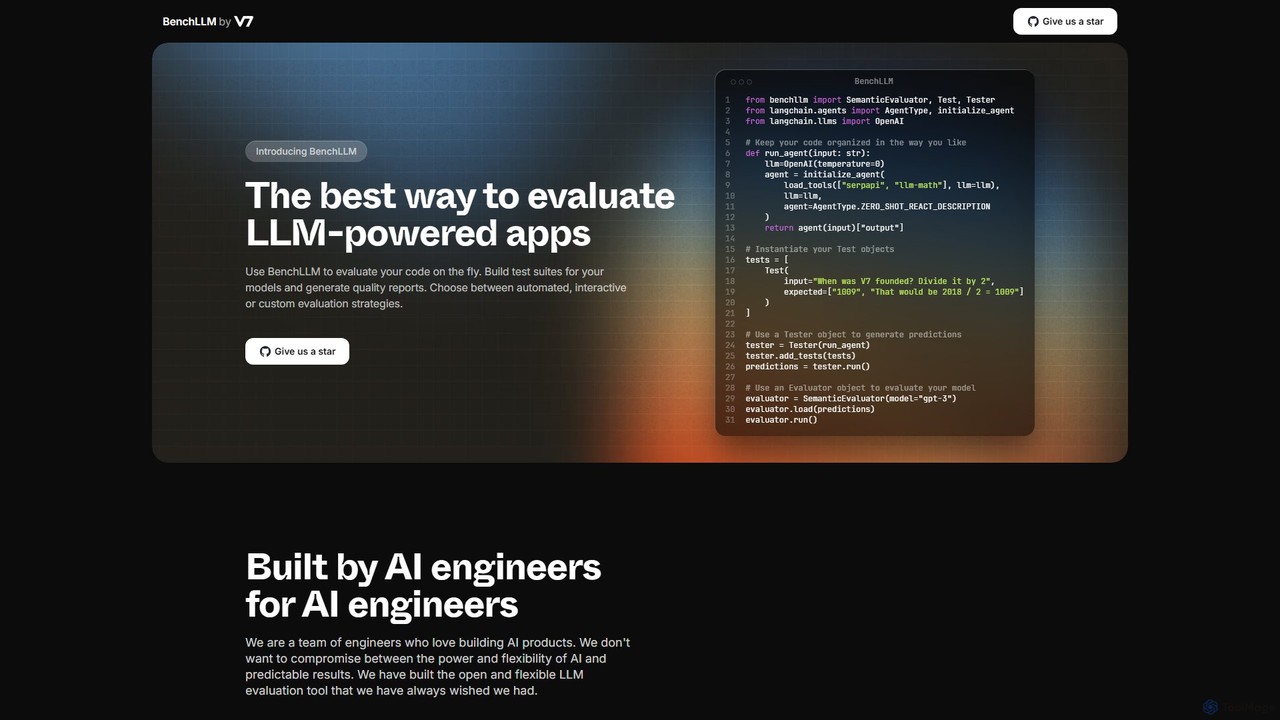
Deepchecks 是一个用于评估、验证和监控基于 LLM 的应用程序的端到端平台。它帮助人工智能团队定义、衡量和验证人工智能的进展,通过简化从开发、CI/CD 到生产的整个测试流程,确保发布高质量、可靠的应用程序。
Deepchecks 是一个用于评估、验证和监控基于 LLM 的应用程序的端到端平台。它帮助人工智能团队定义、衡量和验证人工智能的进展,通过简化从开发、CI/CD 到生产的整个测试流程,确保发布高质量、可靠的应用程序。

Prompt Octopus
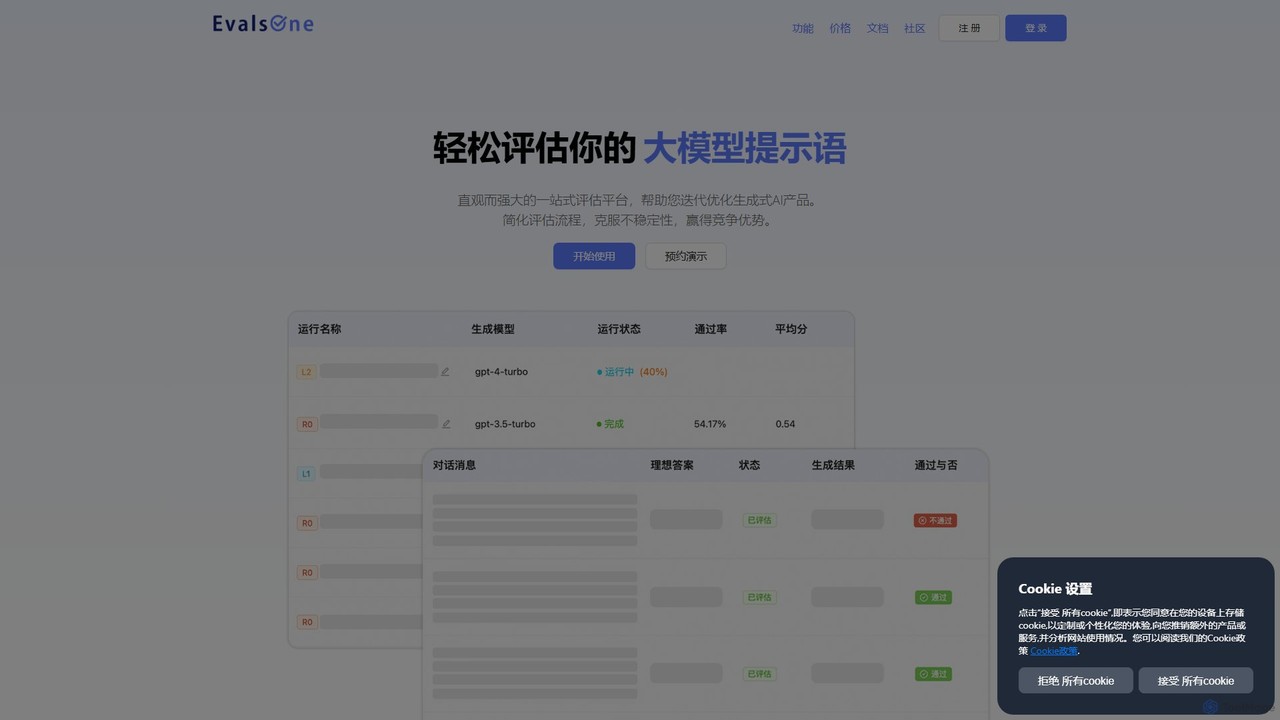
一款专为开发者设计的VSCode扩展,旨在简化提示词工程。它支持在代码库中直接并排比较超过40种LLM(如OpenAI、Anthropic、Mistral)的响应,帮助您高效地为任何任务找到最佳模型。
一款专为开发者设计的VSCode扩展,旨在简化提示词工程。它支持在代码库中直接并排比较超过40种LLM(如OpenAI、Anthropic、Mistral)的响应,帮助您高效地为任何任务找到最佳模型。

Ragas
Ragas 是一个用于评估和测试检索增强生成(RAG)流程的开源 Python 框架。它提供了一套度量标准来衡量 LLM 应用的性能,从上下文检索到答案生成。Ragas 受到 LangChain 和 LlamaIndex 等行业领导者的信赖,通过识别和减轻幻觉、不相关响应等问题,帮助开发者构建更健壮、可靠和准确的 AI 系统。
Ragas 是一个用于评估和测试检索增强生成(RAG)流程的开源 Python 框架。它提供了一套度量标准来衡量 LLM 应用的性能,从上下文检索到答案生成。Ragas 受到 LangChain 和 LlamaIndex 等行业领导者的信赖,通过识别和减轻幻觉、不相关响应等问题,帮助开发者构建更健壮、可靠和准确的 AI 系统。
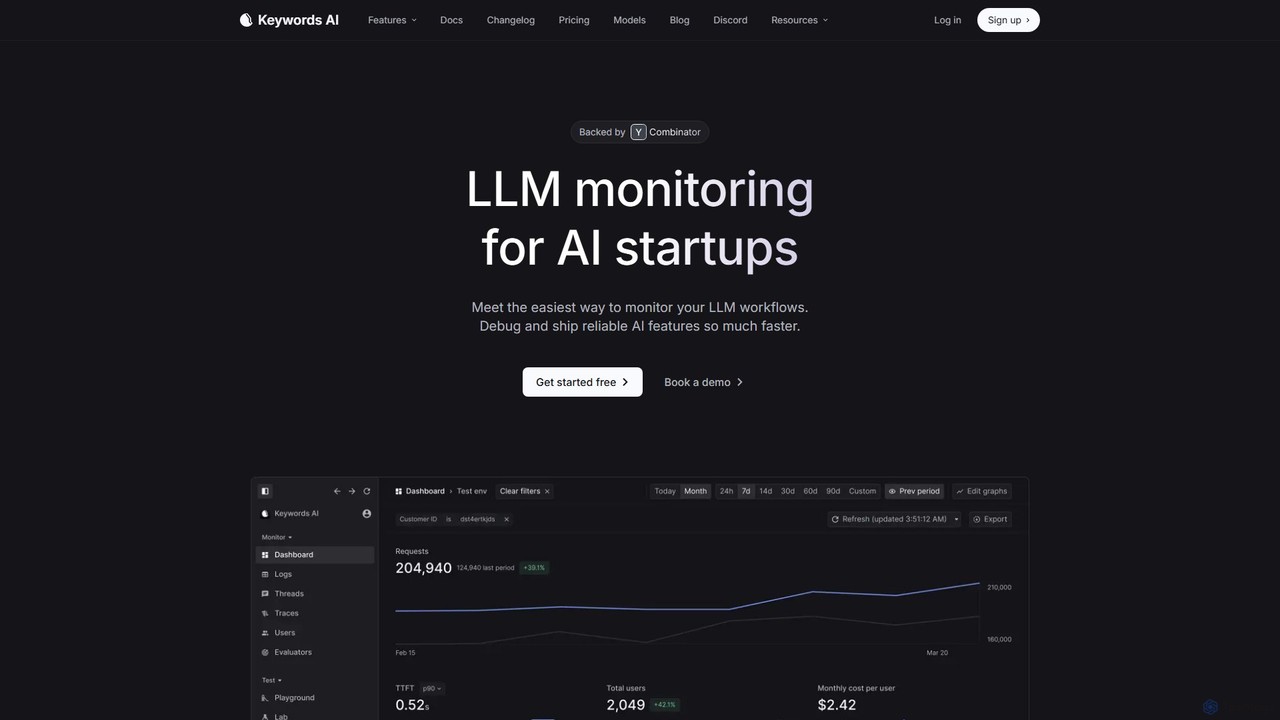
Keywords AI
Keywords AI 是一个专为AI初创公司和开发者设计的全面LLM可观测性与监控平台。它提供统一的API来部署、测试、监控和优化LLM工作流,支持超过200种模型,通过简单的两行代码集成,帮助团队更快地构建和发布可靠的AI功能。
Keywords AI 是一个专为AI初创公司和开发者设计的全面LLM可观测性与监控平台。它提供统一的API来部署、测试、监控和优化LLM工作流,支持超过200种模型,通过简单的两行代码集成,帮助团队更快地构建和发布可靠的AI功能。
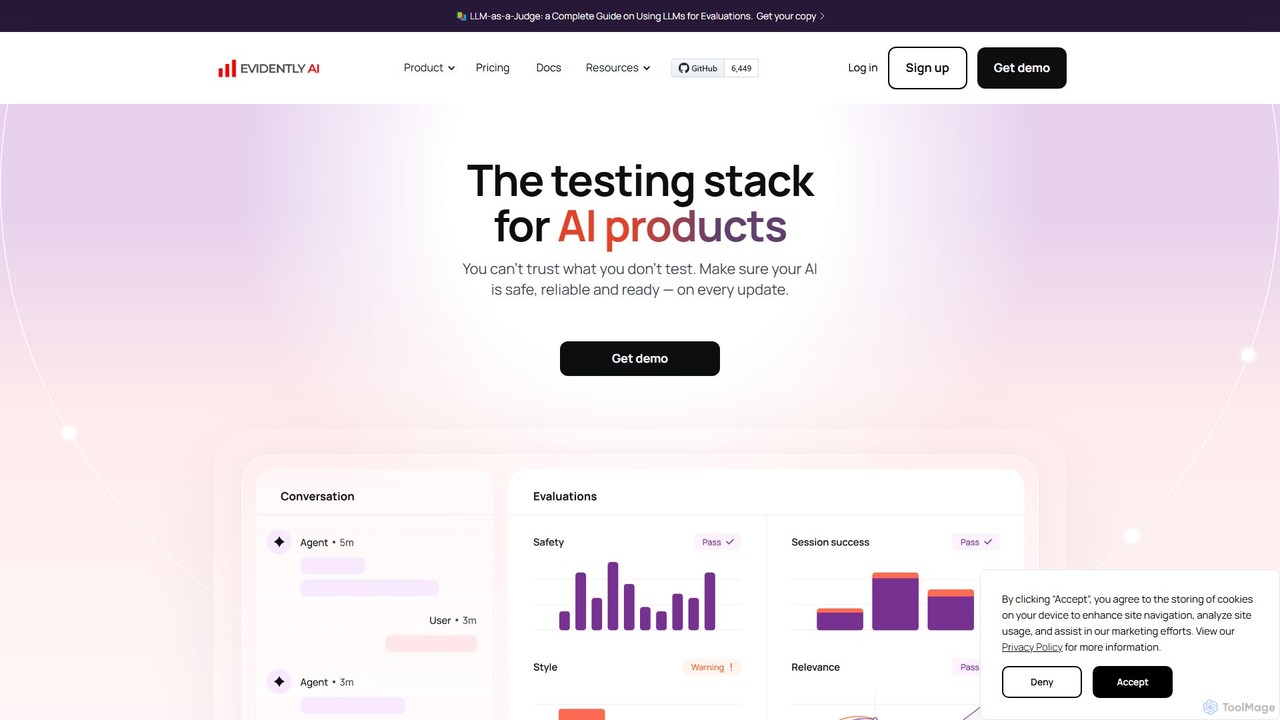
Evidently AI
Evidently AI 是一个面向AI产品的综合性测试与评估平台,专注于LLM和ML模型的监控。它通过自动化评估、合成数据生成、持续测试和对抗性攻击,帮助团队确保AI的安全性、可靠性和性能。该平台基于一个强大的开源库构建,专为数据科学家和MLOps工程师设计,用于在问题影响用户前检测幻觉、数据漂移和PII泄漏等问题。
Evidently AI 是一个面向AI产品的综合性测试与评估平台,专注于LLM和ML模型的监控。它通过自动化评估、合成数据生成、持续测试和对抗性攻击,帮助团队确保AI的安全性、可靠性和性能。该平台基于一个强大的开源库构建,专为数据科学家和MLOps工程师设计,用于在问题影响用户前检测幻觉、数据漂移和PII泄漏等问题。

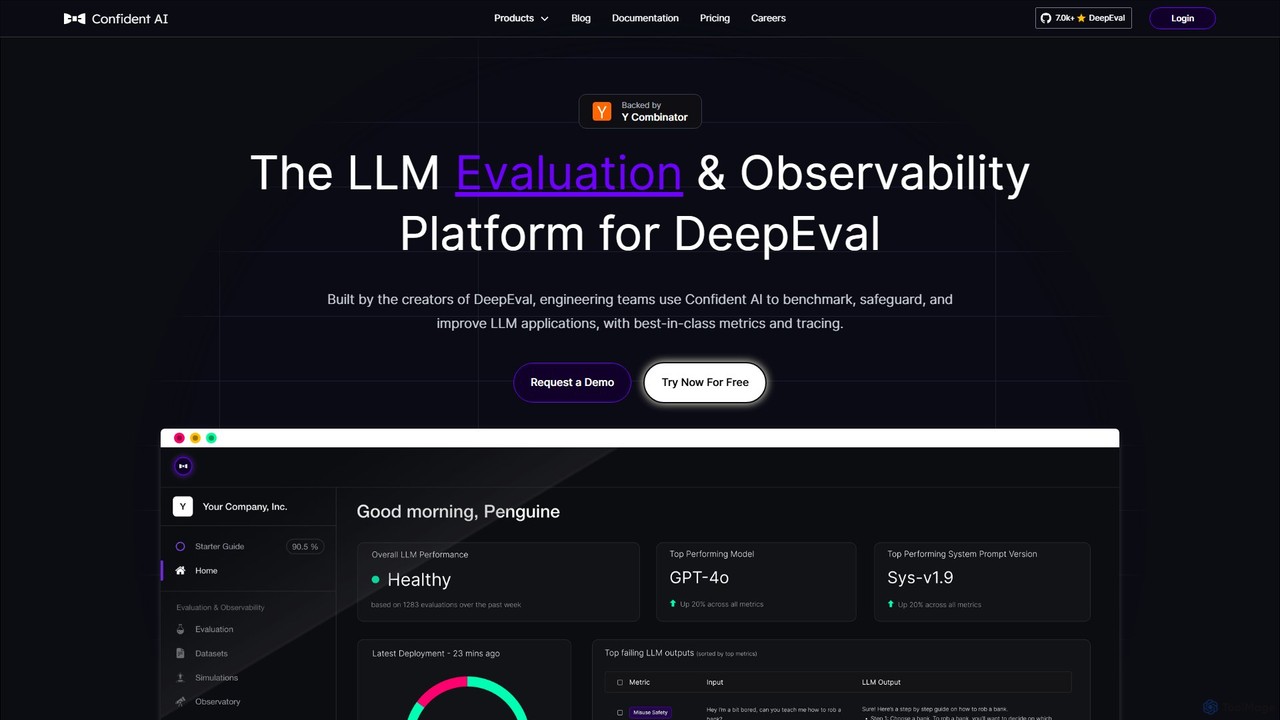
Confident AI
Confident AI 是一个面向工程团队的 LLM 评估和可观测性平台。由开源库 DeepEval 的创建者打造,它通过全面的指标、回归测试和详细的追踪来帮助基准测试、保障和改进 LLM 应用,确保 AI 性能的稳定性。
Confident AI 是一个面向工程团队的 LLM 评估和可观测性平台。由开源库 DeepEval 的创建者打造,它通过全面的指标、回归测试和详细的追踪来帮助基准测试、保障和改进 LLM 应用,确保 AI 性能的稳定性。
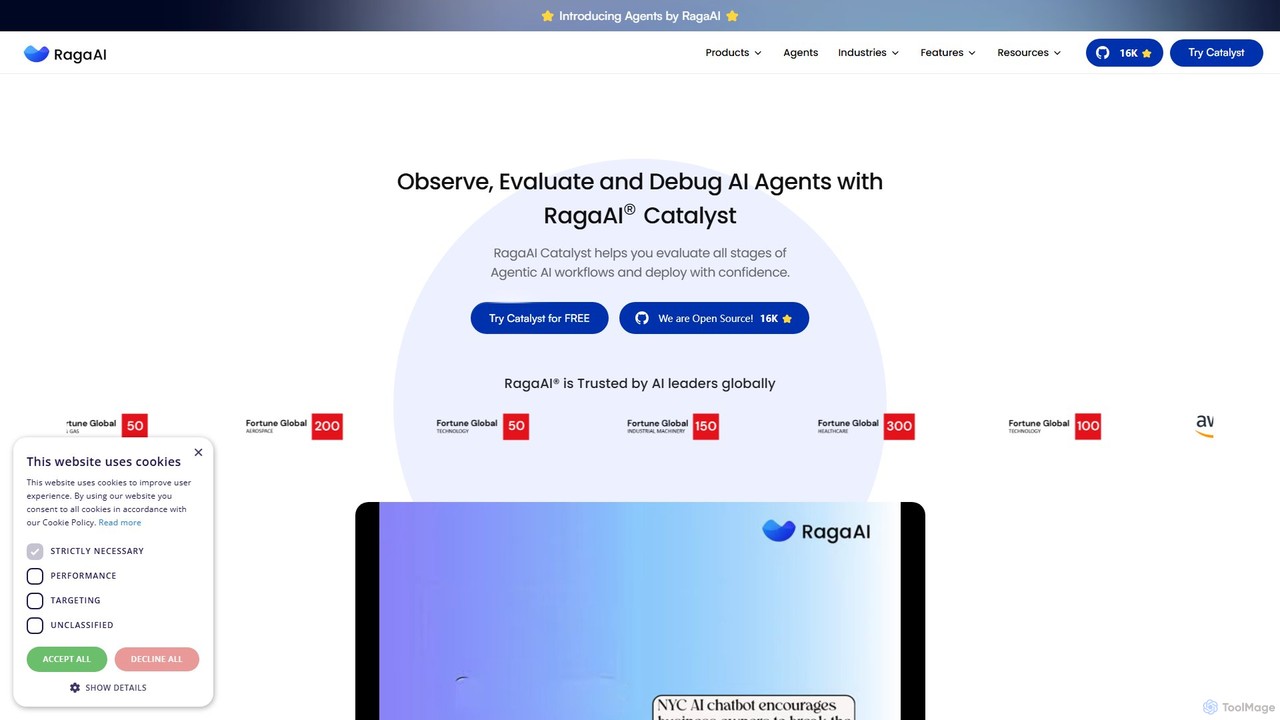
RagaAI
RagaAI 是一个全面的人工智能测试与可观测性平台,旨在帮助开发者和企业构建可靠的 AI 应用。它提供了一整套工具,用于观察、评估和调试 AI 代理、大语言模型(LLM)和 RAG 系统。核心功能包括代理测试、实时护栏、合成数据生成和微调能力。RagaAI 支持多模态数据(LLM、计算机视觉、表格数据),致力于自动化整个 AI 质量保障生命周期,从问题检测到解决,确保 AI 部署的稳健性和可信度。
RagaAI 是一个全面的人工智能测试与可观测性平台,旨在帮助开发者和企业构建可靠的 AI 应用。它提供了一整套工具,用于观察、评估和调试 AI 代理、大语言模型(LLM)和 RAG 系统。核心功能包括代理测试、实时护栏、合成数据生成和微调能力。RagaAI 支持多模态数据(LLM、计算机视觉、表格数据),致力于自动化整个 AI 质量保障生命周期,从问题检测到解决,确保 AI 部署的稳健性和可信度。
AfterQuery
AfterQuery是一家人工智能研究实验室,致力于通过创建高质量、人工生成的训练数据集和无污染的基准测试来推动基础模型的发展。它专注于通过卓越的训练数据和严格的评估来提升模型性能。
AfterQuery是一家人工智能研究实验室,致力于通过创建高质量、人工生成的训练数据集和无污染的基准测试来推动基础模型的发展。它专注于通过卓越的训练数据和严格的评估来提升模型性能。
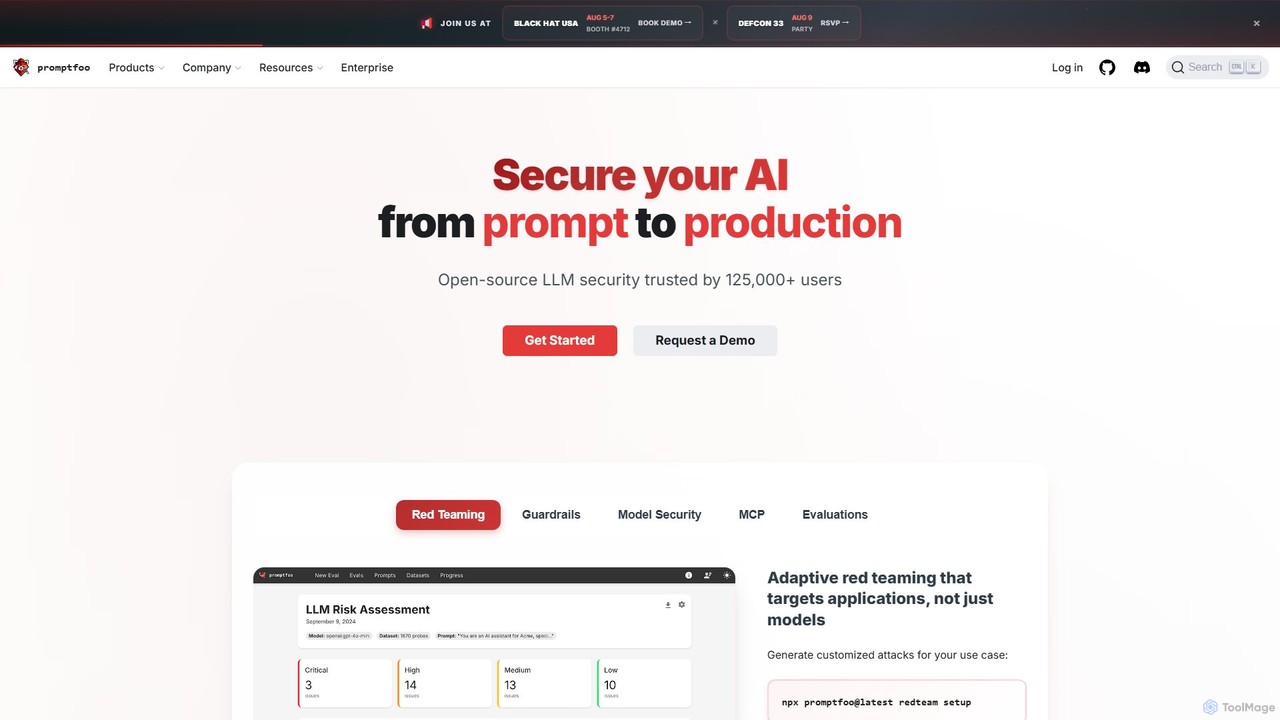
promptfoo
promptfoo 是一个全面的大型语言模型(LLM)测试和评估框架。它帮助开发者和企业通过系统性测试、基准评估和AI驱动的红队演练,来比较提示词质量、评估模型性能并增强AI安全性。它支持超过50家LLM提供商,包括本地模型,并提供对开发者友好的CLI,可无缝集成到开发工作流中。
promptfoo 是一个全面的大型语言模型(LLM)测试和评估框架。它帮助开发者和企业通过系统性测试、基准评估和AI驱动的红队演练,来比较提示词质量、评估模型性能并增强AI安全性。它支持超过50家LLM提供商,包括本地模型,并提供对开发者友好的CLI,可无缝集成到开发工作流中。