Oneinfer
Oneinferは、開発者向けの高性能AI推論プラットフォームです。GPT-4やClaudeなど15以上のLLMにアクセスするための統一APIを提供し、AIの統合を簡素化します。このプラットフォームは、サーバーレス展開、自動スケーリング、エンタープライズレベルのセキュリティ、従量課金制を特徴としています。また、カスタムAIワークロード用のGPUインスタンスをレンタルするマーケットプレイスも提供しています。
Oneinferは、開発者向けの高性能AI推論プラットフォームです。GPT-4やClaudeなど15以上のLLMにアクセスするための統一APIを提供し、AIの統合を簡素化します。このプラットフォームは、サーバーレス展開、自動スケーリング、エンタープライズレベルのセキュリティ、従量課金制を特徴としています。また、カスタムAIワークロード用のGPUインスタンスをレンタルするマーケットプレイスも提供しています。
Gmi Cloud
Gmi Cloudは、スケーラブルなAIトレーニングと推論のために設計された高性能GPUクラウドプラットフォームです。トップティアのNVIDIA GPUへのオンデマンドアクセス、低遅延のための最適化された推論エンジン、合理化されたMLOpsのためのクラスターエンジンを提供し、開発者や企業が効率的かつコスト効果的にAIアプリケーションを構築、展開、拡張できるようにします。
Gmi Cloudは、スケーラブルなAIトレーニングと推論のために設計された高性能GPUクラウドプラットフォームです。トップティアのNVIDIA GPUへのオンデマンドアクセス、低遅延のための最適化された推論エンジン、合理化されたMLOpsのためのクラスターエンジンを提供し、開発者や企業が効率的かつコスト効果的にAIアプリケーションを構築、展開、拡張できるようにします。

Baseten
Basetenは、AIモデルのデプロイ、スケーリング、管理を行うための本番環境グレードの推論プラットフォームです。高性能なランタイム、シームレスな開発者ワークフロー、柔軟なデプロイオプション(クラウド、セルフホスト、ハイブリッド)を提供します。ミッションクリティカルなAIアプリケーションを構築するエンジニアリングおよびMLチームに最適です。
Basetenは、AIモデルのデプロイ、スケーリング、管理を行うための本番環境グレードの推論プラットフォームです。高性能なランタイム、シームレスな開発者ワークフロー、柔軟なデプロイオプション(クラウド、セルフホスト、ハイブリッド)を提供します。ミッションクリティカルなAIアプリケーションを構築するエンジニアリングおよびMLチームに最適です。
HIVE Digital Technologies
HIVE Digital Technologiesは、持続可能なデータセンターインフラのグローバルリーダーであり、大規模なビットコインマイニングとAIアプリケーション向けのハイパフォーマンスコンピューティング(HPC)の提供を専門としています。HIVEはNVIDIA GPUのフリートを活用し、カナダ、スウェーデン、パラグアイにある地理的に多様なデータセンターからの効率的なグリーンエネルギーで革新的な技術を支えています。
HIVE Digital Technologiesは、持続可能なデータセンターインフラのグローバルリーダーであり、大規模なビットコインマイニングとAIアプリケーション向けのハイパフォーマンスコンピューティング(HPC)の提供を専門としています。HIVEはNVIDIA GPUのフリートを活用し、カナダ、スウェーデン、パラグアイにある地理的に多様なデータセンターからの効率的なグリーンエネルギーで革新的な技術を支えています。
Exa Laboratories
Exa Laboratories(現Zettascale)は、YCが出資するシリコンバレーのスタートアップで、AI向けの最先端でエネルギー効率の高い再構成可能チップ(XPU)を開発しています。そのポリモーフィック・コンピューティング・アーキテクチャは、従来のGPUやTPUよりも優れた性能、汎用性、効率性を提供し、AIのトレーニングと推論におけるエネルギー危機を解決することを目指しています。
Exa Laboratories(現Zettascale)は、YCが出資するシリコンバレーのスタートアップで、AI向けの最先端でエネルギー効率の高い再構成可能チップ(XPU)を開発しています。そのポリモーフィック・コンピューティング・アーキテクチャは、従来のGPUやTPUよりも優れた性能、汎用性、効率性を提供し、AIのトレーニングと推論におけるエネルギー危機を解決することを目指しています。
Prediction Guard
Prediction Guardは、組織が自社のファイアウォール内で安全に大規模言語モデル(LLM)をデプロイ、管理、スケールさせるためのエンタープライズ向けAIプラットフォームです。オンプレミス、エアギャップ、プライベートクラウドなどの柔軟なデプロイオプションを提供し、完全なデータプライバシーと制御を保証します。OpenAI互換APIにより、LangChainやLlamaIndexなどの既存ツールやフレームワークとのシームレスな統合が可能で、医療、防衛、金融などの規制産業に最適です。
Prediction Guardは、組織が自社のファイアウォール内で安全に大規模言語モデル(LLM)をデプロイ、管理、スケールさせるためのエンタープライズ向けAIプラットフォームです。オンプレミス、エアギャップ、プライベートクラウドなどの柔軟なデプロイオプションを提供し、完全なデータプライバシーと制御を保証します。OpenAI互換APIにより、LangChainやLlamaIndexなどの既存ツールやフレームワークとのシームレスな統合が可能で、医療、防衛、金融などの規制産業に最適です。

Nebius
Nebiusは、要求の厳しいAIおよび機械学習ワークロード向けに特別に設計された高性能クラウドプラットフォームです。単一インスタンスから大規模クラスタまで、最新のNVIDIA GPUへのスケーラブルなアクセスを提供し、管理サービススイートと統合AI Studioによって、トレーニングから推論までのMLライフサイクル全体を合理化します。
Nebiusは、要求の厳しいAIおよび機械学習ワークロード向けに特別に設計された高性能クラウドプラットフォームです。単一インスタンスから大規模クラスタまで、最新のNVIDIA GPUへのスケーラブルなアクセスを提供し、管理サービススイートと統合AI Studioによって、トレーニングから推論までのMLライフサイクル全体を合理化します。
StackSpaces
StackSpacesは、開発者がフルスタックAIアプリケーションを簡単に構築、デプロイ、スケーリングできるように設計された統合開発プラットフォームです。バックエンド、フロントエンド、インフラストラクチャコンポーネントを含む統一された環境を提供し、アイデアから本番までの開発ライフサイクル全体を合理化します。
StackSpacesは、開発者がフルスタックAIアプリケーションを簡単に構築、デプロイ、スケーリングできるように設計された統合開発プラットフォームです。バックエンド、フロントエンド、インフラストラクチャコンポーネントを含む統一された環境を提供し、アイデアから本番までの開発ライフサイクル全体を合理化します。
Fastly
Fastlyは、高速でスケーラブルなデジタル体験を構築、保護、配信するために設計された、最先端のエッジクラウドプラットフォームです。最新のCDN、次世代WAFなどの堅牢なセキュリティ機能、強力なサーバーレスコンピューティング環境を組み合わせています。Fastlyは、企業がパフォーマンスを向上させ、セキュリティを強化し、ユーザーに近い場所で革新を起こすのを支援し、eコマース、ストリーミング、AI搭載アプリケーション向けの特定のソリューションを提供します。
Fastlyは、高速でスケーラブルなデジタル体験を構築、保護、配信するために設計された、最先端のエッジクラウドプラットフォームです。最新のCDN、次世代WAFなどの堅牢なセキュリティ機能、強力なサーバーレスコンピューティング環境を組み合わせています。Fastlyは、企業がパフォーマンスを向上させ、セキュリティを強化し、ユーザーに近い場所で革新を起こすのを支援し、eコマース、ストリーミング、AI搭載アプリケーション向けの特定のソリューションを提供します。
Tensorfuse
Tensorfuseは、開発者が自身のAWSクラウド上で生成AIモデルのファインチューニング、デプロイ、オートスケーリングを行えるようにするサーバーレスGPUプラットフォームです。インフラ管理を簡素化し、サーバーレス推論、ジョブキュー、開発コンテナなどの機能を提供して、開発を加速し、コストを削減し、DevOpsのオーバーヘッドをなくします。
Tensorfuseは、開発者が自身のAWSクラウド上で生成AIモデルのファインチューニング、デプロイ、オートスケーリングを行えるようにするサーバーレスGPUプラットフォームです。インフラ管理を簡素化し、サーバーレス推論、ジョブキュー、開発コンテナなどの機能を提供して、開発を加速し、コストを削減し、DevOpsのオーバーヘッドをなくします。
DigitalOcean
DigitalOceanは、開発者向けのクラウドインフラプラットフォームで、アプリケーションの構築、デプロイ、スケーリングを簡素化します。仮想マシン(Droplets)、マネージドKubernetes、GradientAIプラットフォームなど、包括的な製品スイートを提供し、サイドプロジェクトから大規模ビジネスまで、世界を変えるAIアプリケーションの作成とホスティングのための強力なGPUリソースとツールを提供します。
DigitalOceanは、開発者向けのクラウドインフラプラットフォームで、アプリケーションの構築、デプロイ、スケーリングを簡素化します。仮想マシン(Droplets)、マネージドKubernetes、GradientAIプラットフォームなど、包括的な製品スイートを提供し、サイドプロジェクトから大規模ビジネスまで、世界を変えるAIアプリケーションの作成とホスティングのための強力なGPUリソースとツールを提供します。

Vast.ai
Vast.aiは、AIおよび機械学習ワークロード向けに広大なGPUネットワークへのオンデマンドアクセスを提供する、主要なGPUクラウドプラットフォームです。透明性の高い従量課金制のマーケットプレイスを通じて、従来のクラウドプロバイダーよりも最大80%安いコストで、開発者や企業に高性能コンピューティングを提供します。
Vast.aiは、AIおよび機械学習ワークロード向けに広大なGPUネットワークへのオンデマンドアクセスを提供する、主要なGPUクラウドプラットフォームです。透明性の高い従量課金制のマーケットプレイスを通じて、従来のクラウドプロバイダーよりも最大80%安いコストで、開発者や企業に高性能コンピューティングを提供します。

thundercompute
Thunder Computeは、AIおよび機械学習開発者向けに設計された超低コストのGPUクラウドプラットフォームです。NVIDIA A100やT4などのオンデマンドGPUインスタンスを、主要なクラウドプロバイダーより最大80%安い価格で提供します。ワンクリック設定、VS Code統合、シームレスなスケーラビリティといった機能により、プロトタイピングから本番環境までの開発ワークフローを劇的に簡素化し、開発者がインフラ管理ではなくモデル構築に集中できるようにします。
Thunder Computeは、AIおよび機械学習開発者向けに設計された超低コストのGPUクラウドプラットフォームです。NVIDIA A100やT4などのオンデマンドGPUインスタンスを、主要なクラウドプロバイダーより最大80%安い価格で提供します。ワンクリック設定、VS Code統合、シームレスなスケーラビリティといった機能により、プロトタイピングから本番環境までの開発ワークフローを劇的に簡素化し、開発者がインフラ管理ではなくモデル構築に集中できるようにします。

massedcompute
Massed Computeは、オンデマンドで高性能なNVIDIA GPUとCPUを提供するクラウドプラットフォームです。AI開発、機械学習、ビッグデータ分析向けに、長期契約なしで柔軟かつスケーラブルで手頃なコンピューティングパワーを提供し、イノベーターや開発者を対象としています。
Massed Computeは、オンデマンドで高性能なNVIDIA GPUとCPUを提供するクラウドプラットフォームです。AI開発、機械学習、ビッグデータ分析向けに、長期契約なしで柔軟かつスケーラブルで手頃なコンピューティングパワーを提供し、イノベーターや開発者を対象としています。

Predibase
Predibaseは、オープンソースの大規模言語モデル(LLM)を効率的にファインチューニングし、サービングするためのエンドツーエンドの開発者プラットフォームです。ユーザーが特定のタスクでGPT-4のような大規模なプロプライエタリモデルを上回るカスタムAIモデルを構築し、コストと推論レイテンシを大幅に削減することを可能にします。このプラットフォームは、強化学習ファインチューニング(RFT)やLoRAXなどの高度な技術を特徴とし、高速なマルチモデルサービングを実現します。
Predibaseは、オープンソースの大規模言語モデル(LLM)を効率的にファインチューニングし、サービングするためのエンドツーエンドの開発者プラットフォームです。ユーザーが特定のタスクでGPT-4のような大規模なプロプライエタリモデルを上回るカスタムAIモデルを構築し、コストと推論レイテンシを大幅に削減することを可能にします。このプラットフォームは、強化学習ファインチューニング(RFT)やLoRAXなどの高度な技術を特徴とし、高速なマルチモデルサービングを実現します。

PPIO
PPIOは、コスト効率が高く高性能なAIコンピューティングパワー、モデルAPI、エッジコンピューティングサービスを提供する、主要な分散型クラウドコンピューティングプラットフォームです。開発者や企業向けに、AI、ビデオ、メタバースアプリケーションのためのワンストップソリューションを提供し、サーバーレスGPU、コンテナ化インスタンス、人気のLLMやマルチモーダルモデルへのアクセスを特徴としています。
PPIOは、コスト効率が高く高性能なAIコンピューティングパワー、モデルAPI、エッジコンピューティングサービスを提供する、主要な分散型クラウドコンピューティングプラットフォームです。開発者や企業向けに、AI、ビデオ、メタバースアプリケーションのためのワンストップソリューションを提供し、サーバーレスGPU、コンテナ化インスタンス、人気のLLMやマルチモーダルモデルへのアクセスを特徴としています。
Fireworks AI
開発者が生成AIアプリケーションを構築、カスタマイズ、スケールさせるための高性能プラットフォームです。業界をリードする高速推論エンジン、高度なファインチューニング機能、幅広いオープンソースモデルへのアクセスを提供し、リアルタイムでコスト効率の高いAIソリューションを実現します。
開発者が生成AIアプリケーションを構築、カスタマイズ、スケールさせるための高性能プラットフォームです。業界をリードする高速推論エンジン、高度なファインチューニング機能、幅広いオープンソースモデルへのアクセスを提供し、リアルタイムでコスト効率の高いAIソリューションを実現します。
HyperAI
HyperAIは、エンタープライズグレードのAIコンピューティングを誰もが利用できるように設計された、ヨーロッパを拠点とするハイパーローカルGPUクラウドプラットフォームです。スポットインスタンスや専用サーバーなどの柔軟なプランを通じて、高性能なNVIDIA A100およびH100 GPUを提供します。低遅延、データコンプライアンス、そしてプリインストールされたNvidia AI SDKを備えた開発者フレンドリーな環境に重点を置き、開発者や企業が複雑なAIモデルを効率的かつ安全に構築、トレーニング、デプロイできるよう支援します。
HyperAIは、エンタープライズグレードのAIコンピューティングを誰もが利用できるように設計された、ヨーロッパを拠点とするハイパーローカルGPUクラウドプラットフォームです。スポットインスタンスや専用サーバーなどの柔軟なプランを通じて、高性能なNVIDIA A100およびH100 GPUを提供します。低遅延、データコンプライアンス、そしてプリインストールされたNvidia AI SDKを備えた開発者フレンドリーな環境に重点を置き、開発者や企業が複雑なAIモデルを効率的かつ安全に構築、トレーニング、デプロイできるよう支援します。
Google Cloud
Google Cloudは、インフラストラクチャ、プラットフォーム、サーバーレス環境を提供する包括的なクラウドコンピューティングサービスのスイートです。Vertex AIとGeminiによるAI/ML、BigQueryによるデータ分析に優れ、スタートアップからグローバル企業まで、あらゆる規模のビジネス向けにスケーラブルで安全なインフラストラクチャを提供します。
Google Cloudは、インフラストラクチャ、プラットフォーム、サーバーレス環境を提供する包括的なクラウドコンピューティングサービスのスイートです。Vertex AIとGeminiによるAI/ML、BigQueryによるデータ分析に優れ、スタートアップからグローバル企業まで、あらゆる規模のビジネス向けにスケーラブルで安全なインフラストラクチャを提供します。
Cirrascale Cloud Services
Cirrascaleは、大規模AI、ディープラーニング、およびハイパフォーマンスコンピューティング(HPC)向けに特化した高性能な専用GPUクラウドサービスを提供します。最新のNVIDIA GPUハードウェアとスケーラブルなインフラストラクチャへのアクセスを提供し、組織が巨大なモデルを効率的にトレーニングし、複雑な計算ワークロードを実行できるようにします。
Cirrascaleは、大規模AI、ディープラーニング、およびハイパフォーマンスコンピューティング(HPC)向けに特化した高性能な専用GPUクラウドサービスを提供します。最新のNVIDIA GPUハードウェアとスケーラブルなインフラストラクチャへのアクセスを提供し、組織が巨大なモデルを効率的にトレーニングし、複雑な計算ワークロードを実行できるようにします。
Clore.ai
Clore.aiは、高性能コンピューティングリソースのグローバルネットワークへのオンデマンドアクセスを提供する分散型GPUマーケットプレイスです。AIトレーニング、3Dレンダリング、科学シミュレーションなどのタスクにGPUパワーを必要とするユーザーと、アイドル状態のサーバーを収益化したいハードウェア所有者を結びつけます。このプラットフォームは、柔軟なレンタル市場、取引用の独自の暗号通貨(CLORE)、報酬と割引を強化する独自のProof-of-Holding(POH)システムを特徴とし、高性能コンピューティングのための包括的なエコシステムを構築しています。
Clore.aiは、高性能コンピューティングリソースのグローバルネットワークへのオンデマンドアクセスを提供する分散型GPUマーケットプレイスです。AIトレーニング、3Dレンダリング、科学シミュレーションなどのタスクにGPUパワーを必要とするユーザーと、アイドル状態のサーバーを収益化したいハードウェア所有者を結びつけます。このプラットフォームは、柔軟なレンタル市場、取引用の独自の暗号通貨(CLORE)、報酬と割引を強化する独自のProof-of-Holding(POH)システムを特徴とし、高性能コンピューティングのための包括的なエコシステムを構築しています。

aistudio
aistudioは、BaiduのPaddlePaddleディープラーニングプラットフォームを搭載した、オールインワンのAI学習・開発コミュニティです。開発者に無料のオンラインプログラミング環境、GPUコンピューティングパワー、豊富なオープンソースモデル、データセットを提供し、AIアプリケーションのシームレスな構築、トレーニング、デプロイを支援します。
aistudioは、BaiduのPaddlePaddleディープラーニングプラットフォームを搭載した、オールインワンのAI学習・開発コミュニティです。開発者に無料のオンラインプログラミング環境、GPUコンピューティングパワー、豊富なオープンソースモデル、データセットを提供し、AIアプリケーションのシームレスな構築、トレーニング、デプロイを支援します。
Salad
Saladは、世界中のコンシューマーPCネットワークの未使用の計算能力を活用する分散型GPUクラウドプラットフォームです。AI/MLワークロード、モデルトレーニング、推論のために、非常に手頃でスケーラブルなオンデマンドGPUリソースを企業に提供し、従来のクラウドプロバイダーと比較して計算コストを最大90%削減します。
Saladは、世界中のコンシューマーPCネットワークの未使用の計算能力を活用する分散型GPUクラウドプラットフォームです。AI/MLワークロード、モデルトレーニング、推論のために、非常に手頃でスケーラブルなオンデマンドGPUリソースを企業に提供し、従来のクラウドプロバイダーと比較して計算コストを最大90%削減します。
Juice
Juiceは、GPU-over-IPを実現するソフトウェアのみのプラットフォームで、あらゆる標準ネットワークを介してGPUリソースにアクセス、共有、プールすることができます。GPUを物理マシンから切り離し、任意のCPUノードをオンデマンドでGPUアクセラレーションシステムに変えることで、コード変更なしで利用率を最適化し、AIやグラフィックスのワークロードコストを大幅に削減します。
Juiceは、GPU-over-IPを実現するソフトウェアのみのプラットフォームで、あらゆる標準ネットワークを介してGPUリソースにアクセス、共有、プールすることができます。GPUを物理マシンから切り離し、任意のCPUノードをオンデマンドでGPUアクセラレーションシステムに変えることで、コード変更なしで利用率を最適化し、AIやグラフィックスのワークロードコストを大幅に削減します。
Hopsworks
Hopsworksは、リアルタイムAIレイクハウスであり、業界で最も先進的なフィーチャーストアです。MLOps向けに設計されており、データとコンピューティングを統合して、信頼性の高いリアルタイムAIシステムを構築・運用します。あらゆるフレームワーク、クラウド、オンプレミス環境をサポートし、モデル開発を加速し、大幅なコスト削減を実現します。
Hopsworksは、リアルタイムAIレイクハウスであり、業界で最も先進的なフィーチャーストアです。MLOps向けに設計されており、データとコンピューティングを統合して、信頼性の高いリアルタイムAIシステムを構築・運用します。あらゆるフレームワーク、クラウド、オンプレミス環境をサポートし、モデル開発を加速し、大幅なコスト削減を実現します。
HIVE Digital Technologies
HIVE Digital Technologiesは、グリーンエネルギーを活用した最先端のデータセンターを構築・運営するグローバルリーダーです。AIソリューション向けに高性能コンピューティング(HPC)とGPUクラウドインフラを提供し、大規模なビットコインマイニング事業と並行して、持続可能性とデータ主権に注力しています。
HIVE Digital Technologiesは、グリーンエネルギーを活用した最先端のデータセンターを構築・運営するグローバルリーダーです。AIソリューション向けに高性能コンピューティング(HPC)とGPUクラウドインフラを提供し、大規模なビットコインマイニング事業と並行して、持続可能性とデータ主権に注力しています。
Eventual
Eventualは、高性能なオープンソースのマルチモーダルデータクエリエンジンであるDaftを用いて、データインフラの未来を構築しています。これにより、エンジニアは深い分散システムの専門知識なしに、SQLのようなシンプルさでペタバイト規模の画像、動画、音声、テキストを処理し、AIおよびMLのワークフローを劇的に加速させることができます。
Eventualは、高性能なオープンソースのマルチモーダルデータクエリエンジンであるDaftを用いて、データインフラの未来を構築しています。これにより、エンジニアは深い分散システムの専門知識なしに、SQLのようなシンプルさでペタバイト規模の画像、動画、音声、テキストを処理し、AIおよびMLのワークフローを劇的に加速させることができます。

OctoAI
OctoAIは、開発者が生成AIモデルを効率的に実行、チューニング、スケーリングするための高性能コンピューティングプラットフォームです。Llama、Mixtral、Stable Diffusionなどの人気のオープンソースモデル向けに、最適化された本番環境対応のAPIエンドポイントを提供します。ディープなシステム最適化に注力することで、OctoAIはより高速な推論速度と低コストを実現し、企業が複雑なインフラを管理することなく、スケーラブルなAIアプリケーションを構築・展開できるようにします。
OctoAIは、開発者が生成AIモデルを効率的に実行、チューニング、スケーリングするための高性能コンピューティングプラットフォームです。Llama、Mixtral、Stable Diffusionなどの人気のオープンソースモデル向けに、最適化された本番環境対応のAPIエンドポイントを提供します。ディープなシステム最適化に注力することで、OctoAIはより高速な推論速度と低コストを実現し、企業が複雑なインフラを管理することなく、スケーラブルなAIアプリケーションを構築・展開できるようにします。

Fluidstack
Fluidstackは、最先端のAIモデルのトレーニングとサービス提供のための高性能な専用GPUクラスタを提供する、業界をリードするAIクラウドプラットフォームです。数千台のGPUの迅速な展開、24時間365日の専門家によるサポートを含むフルマネージドサービス、そしてデータ転送費用ゼロの透明な価格設定により、AIチームがインフラの摩擦なくスケールアップできるよう支援します。
Fluidstackは、最先端のAIモデルのトレーニングとサービス提供のための高性能な専用GPUクラスタを提供する、業界をリードするAIクラウドプラットフォームです。数千台のGPUの迅速な展開、24時間365日の専門家によるサポートを含むフルマネージドサービス、そしてデータ転送費用ゼロの透明な価格設定により、AIチームがインフラの摩擦なくスケールアップできるよう支援します。
GreenNode
GreenNodeは、スタートアップや企業向けに高性能なNVIDIA GPUソリューションを提供するワンストップのAIクラウドインフラプロバイダーです。H100 GPUなどの最先端リソースへの即時アクセス、スケーラブルなインフラ、専門的なAIラボのサポートを提供します。コスト効率とパフォーマンスに重点を置き、モデルのトレーニング、ファインチューニング、推論を加速させ、東南アジアで強力な存在感を示しています。
GreenNodeは、スタートアップや企業向けに高性能なNVIDIA GPUソリューションを提供するワンストップのAIクラウドインフラプロバイダーです。H100 GPUなどの最先端リソースへの即時アクセス、スケーラブルなインフラ、専門的なAIラボのサポートを提供します。コスト効率とパフォーマンスに重点を置き、モデルのトレーニング、ファインチューニング、推論を加速させ、東南アジアで強力な存在感を示しています。
Cerebras
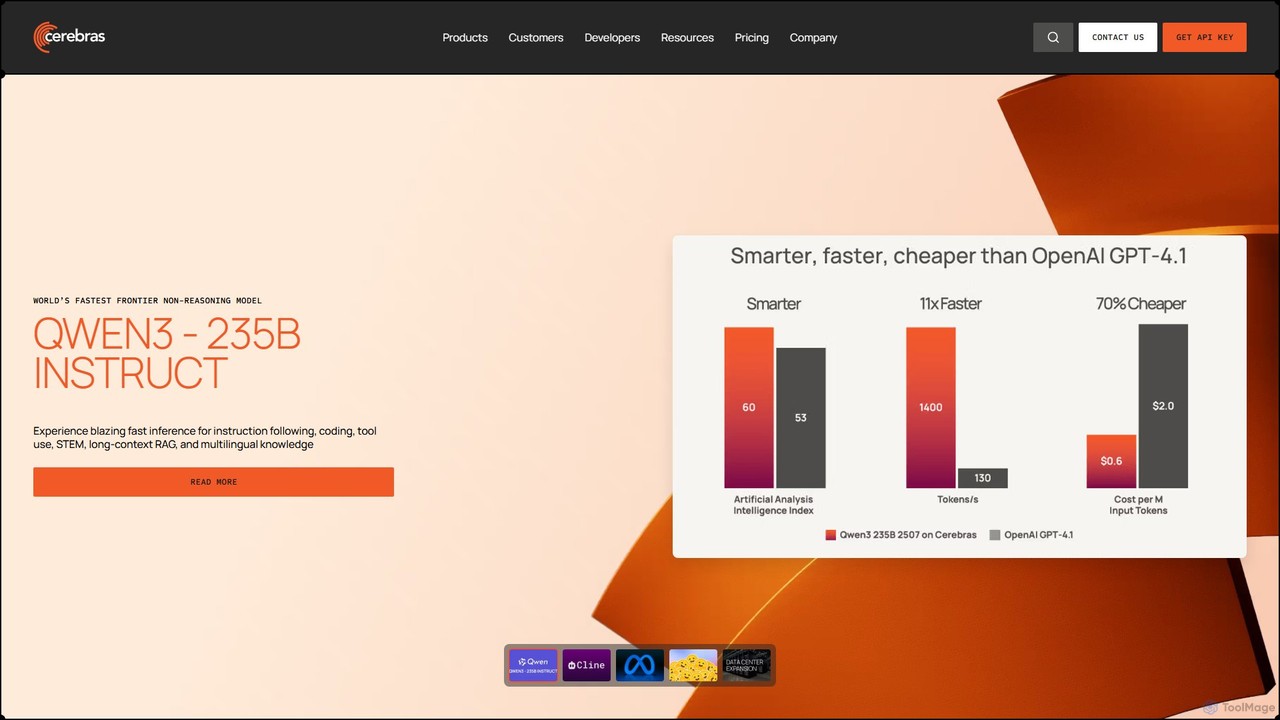
Cerebrasは、革新的なウェーハスケールエンジン(WSE)を搭載した、世界最速のAI推論およびトレーニングプラットフォームを提供します。Llama 4やQwen3などの最新の大規模言語モデルに対して比類のない速度と低遅延を実現し、柔軟なクラウドAPIとオンプレミス展開を通じて、開発者や企業がリアルタイムAIアプリケーションを構築できるよう支援します。
Cerebrasは、革新的なウェーハスケールエンジン(WSE)を搭載した、世界最速のAI推論およびトレーニングプラットフォームを提供します。Llama 4やQwen3などの最新の大規模言語モデルに対して比類のない速度と低遅延を実現し、柔軟なクラウドAPIとオンプレミス展開を通じて、開発者や企業がリアルタイムAIアプリケーションを構築できるよう支援します。


GPUX
GPUXは、高速で手頃なAIモデルの推論を実現するサーバーレス・分散型GPUクラウドプラットフォームです。開発者はAPI経由でモデルを実行でき、GPU所有者はP2Pネットワークにハードウェアを提供することで収益を得ることができます。
GPUXは、高速で手頃なAIモデルの推論を実現するサーバーレス・分散型GPUクラウドプラットフォームです。開発者はAPI経由でモデルを実行でき、GPU所有者はP2Pネットワークにハードウェアを提供することで収益を得ることができます。

Runpod
Runpodは、AIと機械学習向けに設計されたクラウドプラットフォームで、AIモデルのデプロイ、トレーニング、実行のためのスケーラブルなGPUコンピューティングを提供します。サーバーレスGPU、構築済みテンプレート、コスト効率の高い価格設定により、アイデアから本番環境までのAI開発ワークフロー全体を簡素化します。
Runpodは、AIと機械学習向けに設計されたクラウドプラットフォームで、AIモデルのデプロイ、トレーニング、実行のためのスケーラブルなGPUコンピューティングを提供します。サーバーレスGPU、構築済みテンプレート、コスト効率の高い価格設定により、アイデアから本番環境までのAI開発ワークフロー全体を簡素化します。

denvrdata
Denvr Dataworksは、トレーニング、推論、データサイエンス向けの高性能AIクラウドプラットフォームを提供します。垂直統合されたインフラストラクチャと、オンデマンドおよび専用のGPUコンピューティングサービスを提供します。開発者やスタートアップ向けに調整されており、AIイノベーションを加速するための大規模なコンピューティングクレジットを提供するAscendプログラムが特徴です。
Denvr Dataworksは、トレーニング、推論、データサイエンス向けの高性能AIクラウドプラットフォームを提供します。垂直統合されたインフラストラクチャと、オンデマンドおよび専用のGPUコンピューティングサービスを提供します。開発者やスタートアップ向けに調整されており、AIイノベーションを加速するための大規模なコンピューティングクレジットを提供するAscendプログラムが特徴です。

Nebius
Nebiusは、AIと機械学習に特化して設計された高性能クラウドプラットフォームです。最新のNVIDIA GPU、InfiniBandネットワークを備えたスケーラブルなクラスター、KubernetesやSlurmなどのフルマネージドサービスを提供し、あらゆる規模のAIモデルのトレーニング、ファインチューニング、推論をシームレスに実現します。
Nebiusは、AIと機械学習に特化して設計された高性能クラウドプラットフォームです。最新のNVIDIA GPU、InfiniBandネットワークを備えたスケーラブルなクラスター、KubernetesやSlurmなどのフルマネージドサービスを提供し、あらゆる規模のAIモデルのトレーニング、ファインチューニング、推論をシームレスに実現します。
Cloudflare
Cloudflareは、セキュリティ、パフォーマンス、信頼性のための包括的なサービススイートを提供するグローバル接続クラウドプラットフォームです。WAFとDDoS緩和機能でウェブサイトやアプリケーションをオンラインの脅威から保護し、グローバルCDNを介してコンテンツ配信を高速化し、開発者がエッジでAI搭載サービスを含むアプリケーションを構築・展開するためのサーバーレスプラットフォームを提供します。
Cloudflareは、セキュリティ、パフォーマンス、信頼性のための包括的なサービススイートを提供するグローバル接続クラウドプラットフォームです。WAFとDDoS緩和機能でウェブサイトやアプリケーションをオンラインの脅威から保護し、グローバルCDNを介してコンテンツ配信を高速化し、開発者がエッジでAI搭載サービスを含むアプリケーションを構築・展開するためのサーバーレスプラットフォームを提供します。
Awan LLM
Awan LLMは、開発者やパワーユーザー向けの、コスト効率が高く無制限のLLM推論APIプラットフォームです。月額固定料金で無制限のトークン生成を提供し、トークンごとのコストを排除します。このプラットフォームは、高性能な自社所有ハードウェア上で動作し、Meta Llama 3.1のような人気モデルへの無検閲アクセスを提供します。
Awan LLMは、開発者やパワーユーザー向けの、コスト効率が高く無制限のLLM推論APIプラットフォームです。月額固定料金で無制限のトークン生成を提供し、トークンごとのコストを排除します。このプラットフォームは、高性能な自社所有ハードウェア上で動作し、Meta Llama 3.1のような人気モデルへの無検閲アクセスを提供します。
Banana
Bananaは、AI開発者が機械学習モデルの推論をデプロイし、スケーリングするために設計されたサーバーレスGPUプラットフォームでした。オートスケーリングGPU、原価計算価格、完全なDevOpsツールスイートなどの機能を提供していました。注意:Bananaプラットフォームは2024年3月31日に正式にサービスを終了し、現在は運用されていません。
Bananaは、AI開発者が機械学習モデルの推論をデプロイし、スケーリングするために設計されたサーバーレスGPUプラットフォームでした。オートスケーリングGPU、原価計算価格、完全なDevOpsツールスイートなどの機能を提供していました。注意:Bananaプラットフォームは2024年3月31日に正式にサービスを終了し、現在は運用されていません。

Paperspace
Paperspaceは、AIと機械学習のために設計された高性能クラウドコンピューティングプラットフォームです。強力なクラウドGPU、管理されたJupyterノートブック、モデルの構築、トレーニング、デプロイを行うための完全なMLOpsプラットフォーム(Gradient)への簡単なアクセスを提供します。インフラ管理の複雑さなしにAIワークフローを加速させたい開発者、データサイエンティスト、企業に最適です。
Paperspaceは、AIと機械学習のために設計された高性能クラウドコンピューティングプラットフォームです。強力なクラウドGPU、管理されたJupyterノートブック、モデルの構築、トレーニング、デプロイを行うための完全なMLOpsプラットフォーム(Gradient)への簡単なアクセスを提供します。インフラ管理の複雑さなしにAIワークフローを加速させたい開発者、データサイエンティスト、企業に最適です。
Float16.cloud
Float16.cloudは、AI開発を加速させるために設計されたサーバーレスGPUプラットフォームです。秒単位の課金、ゼロセットアップ、コールドスタートなしで高性能なH100 GPUに即座にアクセスできます。開発者はインフラを管理することなく、Pythonスクリプトから直接オープンソースLLMのデプロイ、モデルのトレーニング、AIワークロードの実行が可能です。
Float16.cloudは、AI開発を加速させるために設計されたサーバーレスGPUプラットフォームです。秒単位の課金、ゼロセットアップ、コールドスタートなしで高性能なH100 GPUに即座にアクセスできます。開発者はインフラを管理することなく、Pythonスクリプトから直接オープンソースLLMのデプロイ、モデルのトレーニング、AIワークロードの実行が可能です。
クラウドコンピューティングについて
AIクラウドコンピューティングツールは、機械学習を活用してクラウドインフラの管理と最適化を自動化するプラットフォームです。これらのツールは、メトリクス、ログ、コストレポートなどの膨大な運用データを分析し、パターンを特定して将来のニーズを予測します。コスト削減、パフォーマンス向上、セキュリティ強化のためのインテリジェントな推奨事項を提供し、複雑なクラウド環境の維持に必要な手作業を大幅に削減します。このプロアクティブなアプローチにより、組織はAWS、Azure、GCPなどのプラットフォーム上で信頼性を向上させ、支出を管理し、セキュリティ体制を強化することができます。
主な機能
- AIによるコスト最適化:アイドル状態のリソースを自動的に特定し、インスタンスの適切なサイジングを提案し、支出を予測して予算を最適化します。
- インテリジェントなパフォーマンス監視:異常検知を使用して、パフォーマンスのボトルネックや潜在的な障害がユーザーに影響を与える前にプロアクティブに警告します。
- 自動化されたセキュリティとコンプライアンス:機械学習を利用して異常なアクティビティを検出し、脆弱性を特定し、GDPRやSOC 2などの基準への準拠を継続的にチェックします。
- 予測オートスケーリング:トラフィックパターンを予測し、従来のルールベースの方法よりも効率的にリソースをスケールアップまたはダウンさせ、パフォーマンスとコストのバランスを取ります。
- インテリジェントな資産管理:複数のアカウントやプロバイダーにわたるクラウドリソースの整理、タグ付け、管理のためのスマートなダッシュボードと推奨事項を提供します。
利用シーン
これらのツールは主に、DevOpsエンジニア、サイト信頼性エンジニア(SRE)、FinOps専門家、IT管理者に使用されます。特に、手動での監視が非現実的な大規模で動的な、またはマルチクラウドの展開を行っている組織にとって価値があります。一般的なシナリオには、Kubernetesクラスターの管理、サーバーレス関数のコスト最適化、クラウドネイティブアプリケーションの保護などがあります。
選び方のポイント
AIクラウドコンピューティングツールを選ぶ際は、お使いのクラウドプロバイダー(例:AWS、Azure、Google Cloud)との互換性を考慮してください。コスト、パフォーマンス、セキュリティにわたるAI駆動分析の深さを評価します。自動化能力、既存のツールチェーン(SlackやJiraなど)との統合、そしてレポートとユーザーインターフェースの明確さを確認しましょう。最後に、価格モデルが運用規模に合っているかを検討します。
厳選ツールランキング
最も人気
月間最高トラフィック順
最もインタラクティブ
最低離脱率順
ユーザーエンゲージメントが最も高い
平均滞在時間順
クラウドコンピューティング利用シーン
スタートアップ向けのクラウドコスト管理の自動化
急成長中のSaaSスタートアップのFinOpsチームは、開発速度を落とさずに急増するAWSの請求額を管理するという課題に直面しています。彼らは、環境を継続的にスキャンするAIクラウドコンピューティングツールを導入しました。このツールのAIモデルは、十分に活用されていないEC2インスタンスを特定し、ダウンサイジングを推奨します。また、開発テストから残されたタグ付けされていない孤立したリソースを自動的に終了させます。最初の1か月で、このツールの自動化されたアクションと実行可能な推奨事項により、スタートアップはクラウド支出を20%以上削減し、パフォーマンスを維持しながら重要な予算の緩和を実現しました。
Eコマースプラットフォーム向けのプロアクティブな異常検知
EコマースサイトのSREチームは、ピークのショッピングシーズン中の停止を防ぐためにAI監視ツールを使用しています。このツールは、CPU使用率、メモリ、API応答時間など、アプリケーションの通常のパフォーマンスベースラインを学習します。フラッシュセール中、AIは特定のマイクロサービスで、従来のしきい値ベースのアラートでは見逃されたであろう異常なメモリリークパターンを検出します。チームはSlackを介して即座に通知を受け、問題がサイト全体でのクラッシュにエスカレートする前に修正を展開することができ、収益と顧客体験を保護しました。
金融サービス向けのクラウドセキュリティ強化
フィンテック企業は、規制を遵守するために厳格なセキュリティ体制を維持する必要があります。彼らは、ユーザーアクティビティログとネットワークトラフィックをリアルタイムで分析するAI搭載のクラウドセキュリティツールを使用しています。AIモデルは、開発者の認証情報が通常とは異なる地理的な場所から使用され、機密性の高い本番データにアクセスしようとしていることを特定します。この異常な振る舞いは、高優先度のアラートをトリガーします。セキュリティチームは迅速に調査し、アカウントの侵害を確認し、アクセスを取り消すことができ、機密情報が漏洩する前に潜在的なデータ侵害を防ぎます。
Kubernetesクラスターリソースの最適化
ソフトウェア開発チームは、Google Kubernetes Engine(GKE)クラスター上でマイクロサービスを実行していますが、リソースの割り当てに苦労しており、リソースの無駄遣いやパフォーマンスの問題につながっています。彼らは、時間の経過とともにワークロードのパターンを分析するAIクラウドツールを統合しました。このツールは、各ポッドのCPUとメモリのリクエストとリミットを調整するための具体的な推奨事項を提供します。これらのAI駆動の提案を適用することで、チームはクラスター全体のリソース消費を30%削減し、同時にアプリケーションのレイテンシに影響を与えていたCPUスロットリングの問題を解消しました。
マルチクラウドのコンプライアンス監査の合理化
グローバル企業はAzureとGCPの両方でワークロードを運用しており、SOC 2などの基準のコンプライアンス監査は複雑で時間のかかるプロセスになっています。彼らは、コンプライアンス監視を自動化するためにAIクラウドプラットフォームを採用しました。このツールは、事前に構築されたSOC 2コントロールフレームワークに対して、構成、アクセスポリシー、データストレージ設定を継続的にスキャンします。AIを使用して潜在的な違反にフラグを立て、詳細で監査対応のレポートを自動的に生成します。これにより、監査準備のための手作業が数週間から数日に短縮され、セキュリティチームはコンプライアンス体制を継続的かつリアルタイムで把握できます。
メディアストリーミングサービスの予測スケーリング
ビデオストリーミングサービスは、リソースを過剰にプロビジョニングして過大なコストを発生させることなく、ライブイベント中の予測不可能なトラフィックスパイクを処理する必要があります。彼らは、予測オートスケーリングを備えたAIクラウドツールを導入しました。このツールは、過去の視聴データとリアルタイムのトレンドを分析して、今後の主要なスポーツ決勝戦の需要を予測します。その予測に基づいて、イベント開始の1時間前にサーバー容量のスケーリングを自動的に開始し、すべてのユーザーにスムーズでバッファフリーな体験を保証します。ピーク後は、ルールベースのスケーラーよりもインテリジェントにリソースをスケールダウンし、コストを節約します。