Diffbot
Visit Website
Diffbot Overview
Diffbot provides a suite of AI-powered tools designed to understand and structure the content of the public web, effectively turning it into the world's largest, most comprehensive database. At its core is the Diffbot Knowledge Graph, a massive, interconnected repository of data about organizations, people, articles, products, and more. Unlike traditional web scrapers that require manual rules for each website, Diffbot uses computer vision and natural language processing to automatically interpret web pages like a human, extracting structured data without site-specific configurations.
This technology allows developers and businesses to stop wrestling with the noisy, chaotic nature of web data and instead access it as if it were a clean, structured database. Whether you need to monitor news, enrich customer profiles, conduct market research, or power a machine learning model, Diffbot provides the clean, reliable data feeds required to build intelligent applications.
How to use Diffbot
Getting started with Diffbot is designed to be straightforward for developers and data teams. The primary interaction is through its powerful APIs.
- Sign Up: Begin by creating an account. Diffbot offers a free plan with 10,000 credits and full API access, allowing you to test the platform's capabilities without a credit card.
- Get Your API Token: Once registered, you'll receive an API token from your dashboard. This token is used to authenticate all your requests to the Diffbot APIs.
- Choose the Right API: Diffbot offers several distinct APIs for different tasks:
- Extract API: Point it at any URL (like an article, product page, or forum discussion), and it will automatically return structured JSON data. No rules needed.
- Crawl API: Provide a starting URL, and Diffbot will systematically crawl the entire site, using the Extract API to turn every relevant page into structured data. This is ideal for building a database from a specific website.
- Knowledge Graph Search API: Query the pre-built Knowledge Graph to find information on over 246 million organizations, 1.6 billion articles, and more. You can search for entities and build precise data feeds.
- Knowledge Graph Enhance API: Provide your own data (e.g., a company name), and Diffbot will enrich it with comprehensive data from the Knowledge Graph, such as revenue, employee count, social profiles, and recent news.
- Natural Language API: Submit raw text to infer entities, relationships between them, and perform sentiment analysis.
- Integrate and Build: Use the API responses (in JSON format) to power your applications, populate your databases, or feed your analytics dashboards. For real-time needs, you can set up webhooks for instant notifications, such as new articles mentioning a specific company.
Core Features of Diffbot
- Knowledge Graph: A massive, pre-crawled, and continuously updated graph of the web, containing structured information on organizations, people, products, articles, and their relationships.
- Automatic Extraction: AI-driven technology that automatically identifies and extracts key information from various page types (articles, products, discussions, etc.) without requiring manual setup or rules.
- Crawlbot: An intelligent web crawler that can turn an entire website into a structured database, automatically identifying and extracting content from relevant pages.
- Natural Language Processing (NLP): Advanced NLP capabilities to understand text in over 20 languages, perform entity recognition (distinguishing 'Apple' the company from 'apple' the fruit), and conduct sentiment analysis at the topic level.
- Data Enrichment (Enhance API): The ability to take a minimal piece of information, like a company name or email, and enrich it with dozens of data points from the Knowledge Graph.
- Real-time Monitoring: Build custom, noise-free feeds for news and brand mentions with real-time alerts via email or webhooks.
Use Cases for Diffbot
Diffbot's structured data is valuable across numerous industries and functions:
- Market Intelligence: Track competitors, monitor industry trends, and analyze market movements by tapping into global news, company filings, and product data.
- Risk & Compliance: Perform due diligence on companies and individuals, monitor supply chains for risk signals, and stay ahead of regulatory changes.
- Sales & Marketing: Enrich lead data in CRMs, identify new prospects based on specific criteria (e.g., companies in a certain industry that just received funding), and personalize outreach.
- News & Media Monitoring: Create highly specific, real-time news feeds that track mentions of brands, people, or topics with precise entity matching and sentiment analysis.
- Recruiting: Build databases of potential candidates, identify talent, and enrich professional profiles with data from across the web.
- Machine Learning: Use the Knowledge Graph as a source of high-quality, structured training data for various AI and machine learning models.
Advantages of Diffbot
The primary advantage of Diffbot is its ability to treat the entire web as a single, queryable database. It abstracts away the complexity of web scraping and data cleaning. Key benefits include accuracy, scale, and efficiency. Instead of building and maintaining fragile, site-specific scrapers, users can rely on a single, robust API. The entity-aware NLP ensures data quality and relevance, while the pre-built Knowledge Graph provides immediate access to a vast dataset that would take years to build in-house.
Pricing and Plans
Diffbot offers a tiered pricing structure to accommodate different levels of usage, from hobby projects to large enterprises.
- Free Plan: $0/month. Includes 10,000 credits, full API access, and is free forever. Ideal for testing and small projects.
- Startup Plan: $299/month. Includes 250,000 credits and is designed for small teams needing plug-and-play scraping and Knowledge Graph access.
- Plus Plan: $899/month. Includes 1,000,000 credits, access to the Crawl product, and higher API call rates. Suitable for growing businesses with more significant data needs.
- Enterprise Plan: Custom pricing. Offers bespoke plans with custom credit allotments, the highest API call rates, premium SLA support, and managed solutions for large-scale data operations.
Credits are consumed based on the type and complexity of the API call. A detailed breakdown is available on their website.
Diffbot Comments (0)
Log in to post comments
Log in nowDiffbotWebsite Traffic Analysis
Latest Traffic
Status
Monthly Traffic Trend
Geography
Top 5 Countries/Regions
-
🇺🇸 United States36.36%
-
🇮🇳 India28.03%
-
🇳🇬 Nigeria14.97%
-
🇨🇦 Canada10.37%
-
🇩🇪 Germany10.27%
Traffic source
| Source Type | Percentage |
|---|---|
|
Direct Access
|
93.32% |
|
Referral
|
6.03% |
|
Email
|
0.65% |
Popular Keywords
| Keyword | Cost Per Click |
|---|---|
|
$0.00
|
|
|
$4.94
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
Diffbot Alternatives
View All
Oxylabs
Oxylabs is a leading provider of premium proxy services and enterprise-level web data gathering solutions. Leveraging a massive, …
Oxylabs is a leading provider of premium proxy services and enterprise-level web data gathering solutions. Leveraging a massive, ethically-sourced proxy network of over 177 million IPs, it offers AI-powered Scraper APIs, a Web Unblocker, and the new AI Studio for natural language data extraction. It enables businesses to collect public web data at scale for e-commerce, cybersecurity, brand protection, and market research without getting blocked.
SingleAPI
SingleAPI is a GPT-4 powered tool that instantly converts any website into a structured JSON API. It simplifies …
SingleAPI is a GPT-4 powered tool that instantly converts any website into a structured JSON API. It simplifies web scraping, data extraction, and data enrichment without writing any code or selectors, allowing users to effortlessly access web data for various applications.
Import.io
Import.io is an enterprise-grade web data extraction platform that provides high-quality, structured data from any website. It offers …
Import.io is an enterprise-grade web data extraction platform that provides high-quality, structured data from any website. It offers both a fully managed service and a self-service solution to power e-commerce market intelligence, brand monitoring, and data-driven business decisions, overcoming complex anti-scraping technologies.
Hyperbrowser
Hyperbrowser is a Browser-as-a-Service platform designed for AI agents and developers. It provides scalable, lightning-fast cloud browsers to …
Hyperbrowser is a Browser-as-a-Service platform designed for AI agents and developers. It provides scalable, lightning-fast cloud browsers to automate web tasks, extract data, and enable AI-driven web interactions. With features like stealth browsing, automatic captcha solving, and developer-friendly APIs, it empowers complex workflows without limits.
Simplescraper
Simplescraper is a powerful web scraping tool that extracts data from any website in seconds. It offers a …
Simplescraper is a powerful web scraping tool that extracts data from any website in seconds. It offers a user-friendly Chrome extension for no-code data selection, cloud-based automation for large-scale scraping, and an innovative AI Enhance feature to pull insights using simple prompts. Turn websites into structured data (CSV, JSON) or instant APIs, and integrate with tools like Google Sheets and Airtable.
Nimbleway
Nimbleway is an enterprise-grade platform for AI-driven web data collection and scalable data pipelines. It empowers businesses to …
Nimbleway is an enterprise-grade platform for AI-driven web data collection and scalable data pipelines. It empowers businesses to interact with real-time web data, offering tools like agentic web search, an online knowledge cloud, and a robust SDK. Ideal for retail, finance, and AI, it provides hypergranular, structured data for competitive analysis, price monitoring, and feeding LLMs, ensuring ethical and compliant data gathering.
Kadoa
Kadoa is an AI-powered, no-code web scraping platform that automates data extraction from any website or document. It …
Kadoa is an AI-powered, no-code web scraping platform that automates data extraction from any website or document. It enables users to build scalable, self-healing data pipelines in minutes, eliminating engineering bottlenecks and providing real-time insights for finance, retail, and market intelligence.
Zyte
Zyte is a comprehensive web scraping platform offering a full-stack API and data extraction services. It simplifies data …
Zyte is a comprehensive web scraping platform offering a full-stack API and data extraction services. It simplifies data acquisition by managing proxies, headless browsers, and advanced anti-blocking systems. Powered by AI, Zyte delivers reliable, structured web data at scale for businesses in e-commerce, market research, and more.
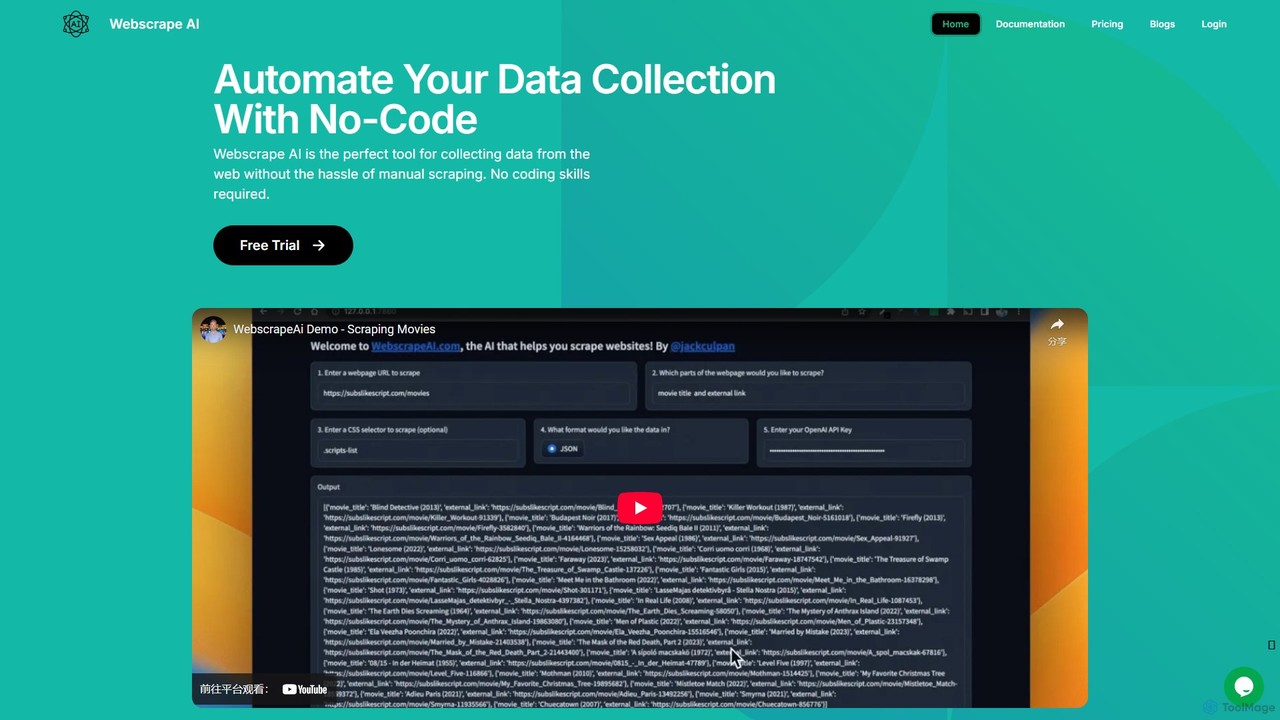
webscrapeai
WebscrapeAI is a no-code, AI-powered platform designed to automate web data collection. Simply provide a URL and specify …
WebscrapeAI is a no-code, AI-powered platform designed to automate web data collection. Simply provide a URL and specify the data you need, and the AI handles the entire scraping process. It supports dynamic websites, bulk scraping, proxy integration, and offers an API for developers, making data extraction fast, accurate, and accessible to everyone.
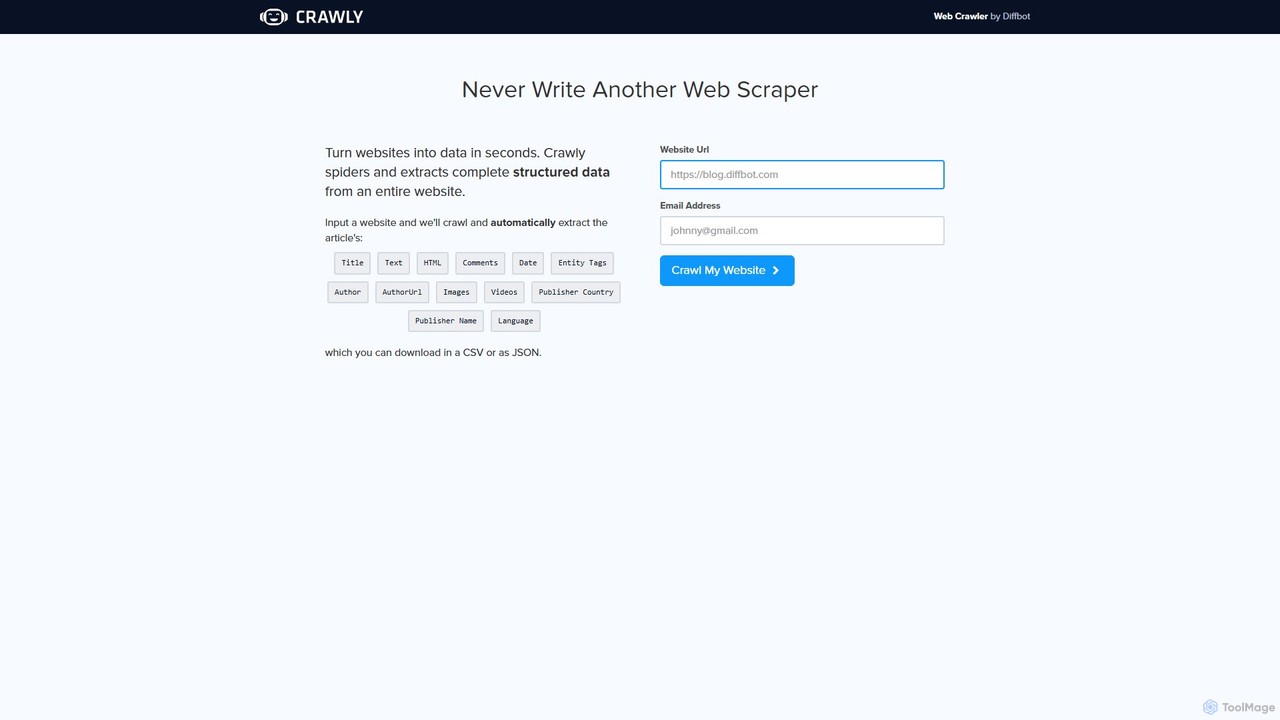
Crawly
Crawly is an AI-powered web crawler by Diffbot that automatically extracts structured data from entire websites. Simply input …
Crawly is an AI-powered web crawler by Diffbot that automatically extracts structured data from entire websites. Simply input a URL, and Crawly spiders the site to pull key information like articles, products, and discussions, converting it into clean JSON or CSV data without any coding required.
Diffbot Category
Diffbot Tag
Diffbot AI Tool Comparison
Diffbot Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!