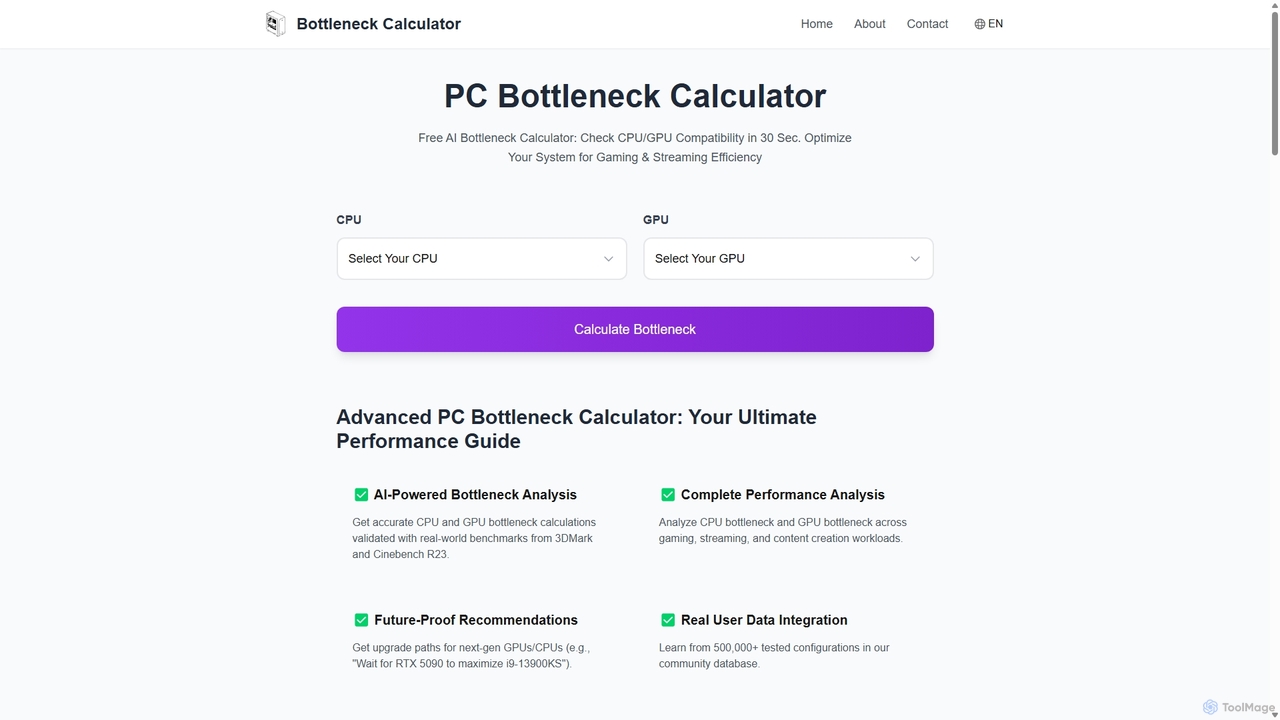
Bottleneck Calculator
An AI-powered tool that instantly analyzes your PC's CPU and GPU compatibility to identify performance bottlenecks. Get accurate …
An AI-powered tool that instantly analyzes your PC's CPU and GPU compatibility to identify performance bottlenecks. Get accurate calculations, future-proof upgrade recommendations, and optimization tips for gaming, streaming, and content creation, all validated by real-world benchmarks and a database of over 500,000 user configurations.
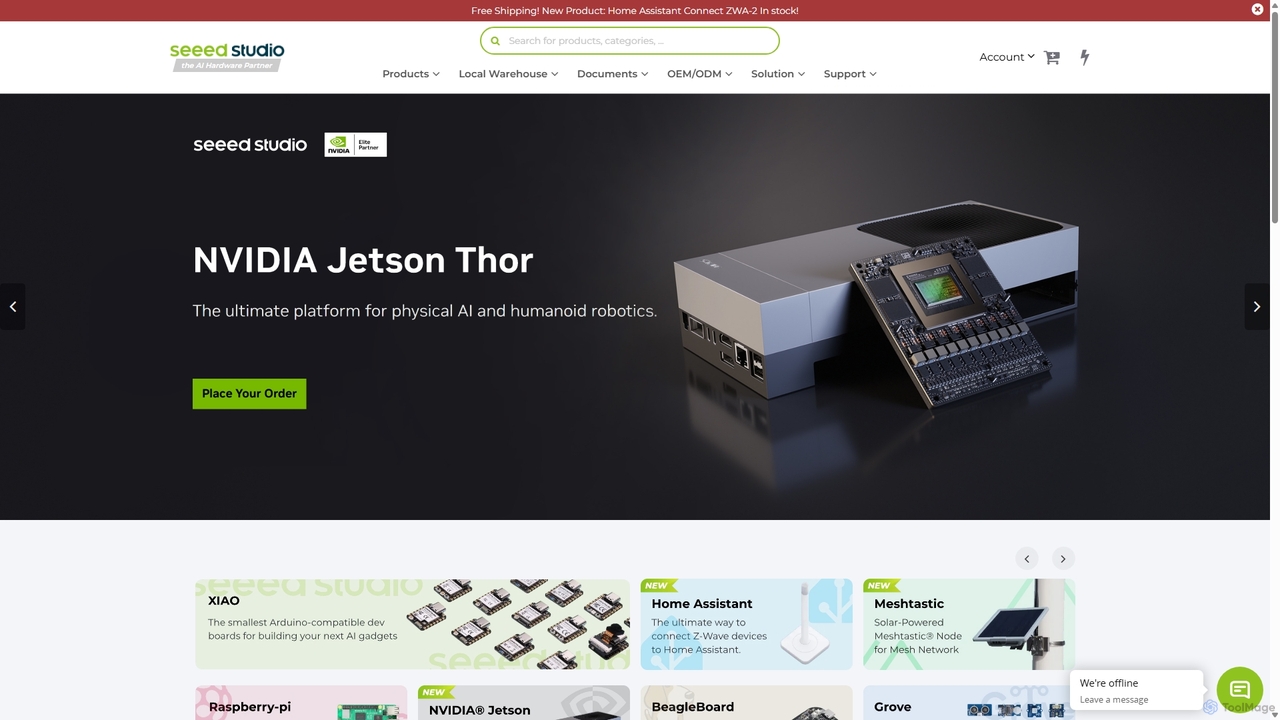
Seeed Studio
Seeed Studio is a leading IoT hardware platform for developers and businesses. It provides a vast range of …
Seeed Studio is a leading IoT hardware platform for developers and businesses. It provides a vast range of open-source hardware, development kits, sensors, and AI-accelerated modules, specializing in edge computing. From prototyping with Raspberry Pi and NVIDIA Jetson to scalable manufacturing services (OEM/ODM), Seeed Studio empowers innovators to build and deploy real-world IoT and Edge AI solutions for smart agriculture, industry, and cities.
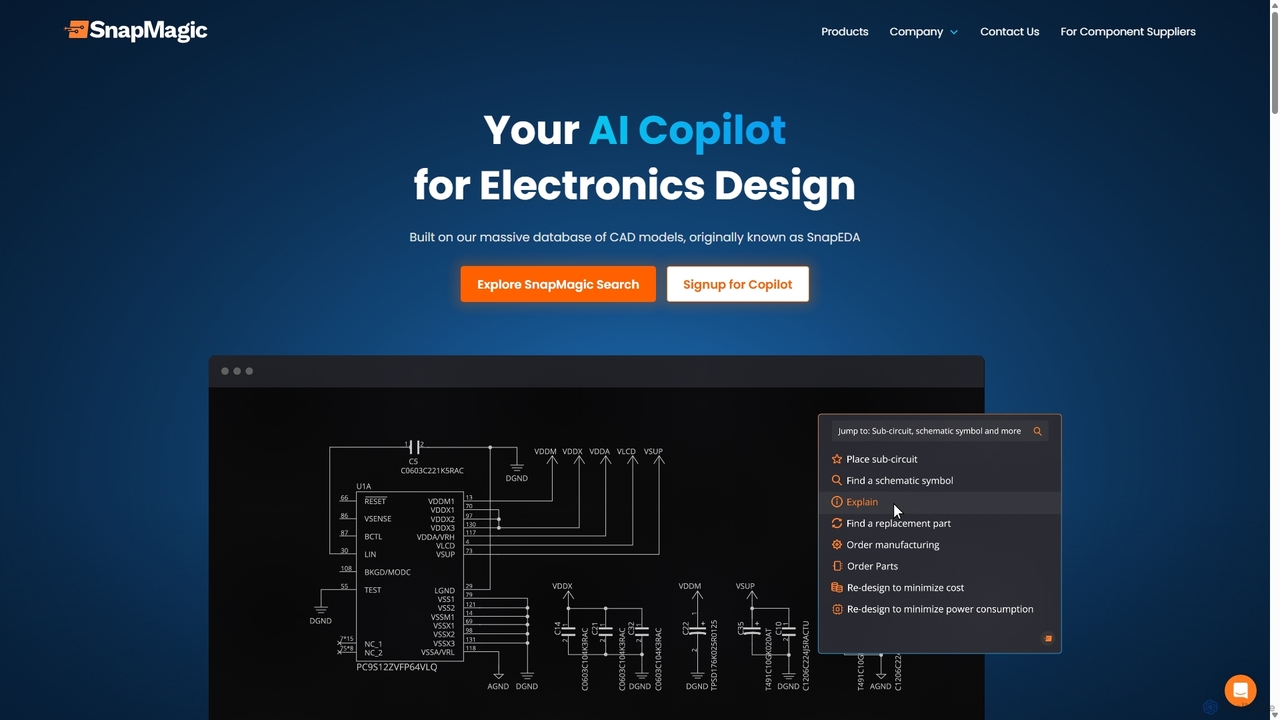
SnapMagic
SnapMagic is an AI copilot for electronics design, automating and accelerating the circuit board creation process. It uses …
SnapMagic is an AI copilot for electronics design, automating and accelerating the circuit board creation process. It uses AI to auto-complete circuits, optimize your Bill of Materials (BOM) for cost and power, and provides real-time supply chain data. Engineers can interact with designs using natural language, streamlining repetitive tasks and fostering innovation from concept to manufacturing.
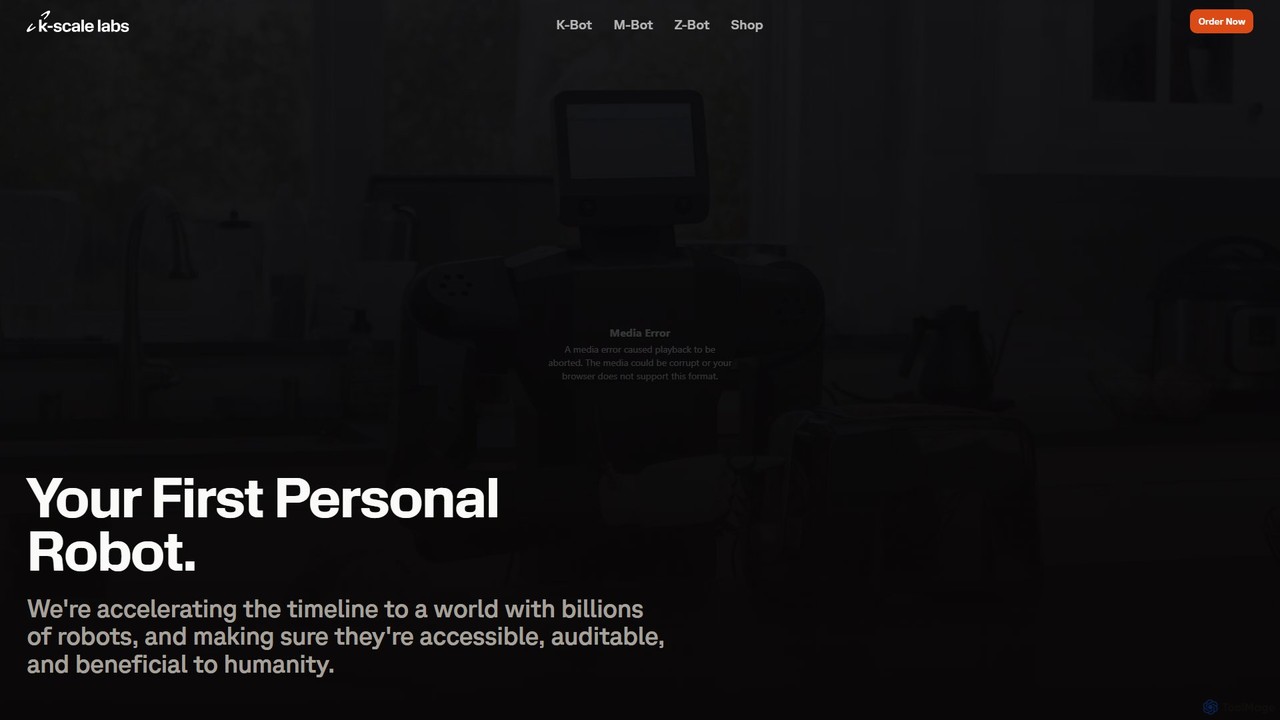
kscale
kscale by K-Scale Labs is an open-source, full-stack humanoid robot platform, K-Bot, designed for developers and researchers. It …
kscale by K-Scale Labs is an open-source, full-stack humanoid robot platform, K-Bot, designed for developers and researchers. It aims to accelerate the adoption of general-purpose robots by providing an accessible, modular, and community-driven hardware and software ecosystem for building and deploying embodied AI.
Flux
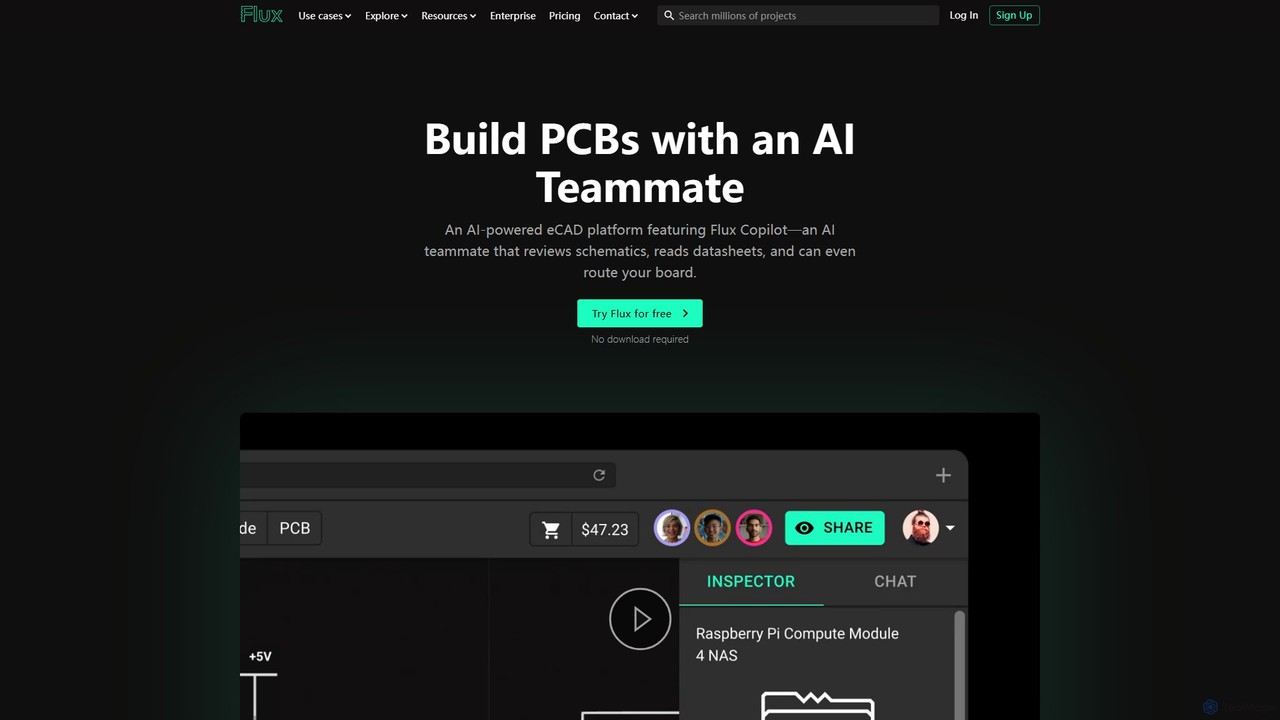
Flux is a modern, browser-based electronics design tool that leverages AI to revolutionize PCB creation. Its AI Copilot …
Flux is a modern, browser-based electronics design tool that leverages AI to revolutionize PCB creation. Its AI Copilot automates the tedious routing process with a single click, producing human-like, professional layouts. Designed for collaboration, Flux integrates a circuit simulator and a vast component library, making it accessible for beginners while offering powerful features for advanced engineers.
Hailo
Hailo is a leading chipmaker of high-performance AI processors for edge devices. Their solutions, including the Hailo-8 and …
Hailo is a leading chipmaker of high-performance AI processors for edge devices. Their solutions, including the Hailo-8 and Hailo-10H accelerators, enable data center-class AI performance and generative AI capabilities directly on edge devices. They focus on exceptional power efficiency, low latency, and cost-effectiveness for sectors like automotive, smart cities, retail, and industrial automation.
About Hardware
AI Hardware refers to specialized computing components engineered to accelerate artificial intelligence and machine learning workloads. These components, such as GPUs, TPUs, and other AI accelerators, are built with architectures optimized for parallel processing and matrix operations, which are fundamental to neural networks. Their primary value lies in drastically reducing the time required for training complex models and enabling efficient, real-time inference. This specialized hardware is a foundational element for developers building performance-intensive AI applications.
Core Features
- Parallel Processing Architecture: Thousands of specialized cores for handling massive simultaneous computations, ideal for deep learning.
- High-Bandwidth Memory (HBM): Provides ultra-fast data access, crucial for feeding large datasets to the processing units without bottlenecks.
- Tensor Cores / Matrix Units: Dedicated circuits for performing mixed-precision matrix multiplication and accumulation operations, the building blocks of AI models.
- Low-Precision Inference Support: Optimized for calculations using lower-precision number formats (like INT8 or FP16) to increase throughput and reduce latency.
- Scalable Interconnects: High-speed links (e.g., NVLink, Infinity Fabric) that allow multiple hardware units to work together as a single, powerful processor.
Use Cases
AI Hardware is essential in data centers for training large-scale models like LLMs and in cloud computing for serving high-throughput inference requests. It is also deployed at the edge in devices like autonomous vehicles, smart cameras, and industrial robots for real-time decision-making. Research institutions and enterprises use it for scientific computing, drug discovery, and financial modeling.
How to Choose
Selecting the right AI hardware depends on your specific needs. For large-scale model training, prioritize components with high memory capacity and strong FP32/TF32 performance. For edge inference, focus on power efficiency, physical size, and INT8 performance. Also, consider the software ecosystem (e.g., CUDA, ROCm), framework compatibility (TensorFlow, PyTorch), and the total cost of ownership, including power and cooling.
HardwareUse Cases
Accelerating Large Language Model (LLM) Training
An AI research team at a major tech company needs to train a new 100-billion parameter language model. Using traditional CPUs would take years. By leveraging a distributed cluster of hundreds of high-end AI GPUs with fast interconnects, they can parallelize the training process. This specialized hardware allows them to complete the training in a matter of weeks, not years, enabling faster iteration on model architecture and bringing cutting-edge AI capabilities to market much sooner.
Real-Time Object Detection on an Edge Device
A developer is building a smart security camera that needs to identify intruders in real-time without relying on a cloud connection. They use a compact, low-power AI accelerator board (like an NVIDIA Jetson or Google Coral). They deploy a pre-trained object detection model onto the device. The specialized hardware processes the video feed locally, running inference in milliseconds. This enables instant alerts and operation even during internet outages, a critical feature for security applications.
High-Throughput Medical Image Analysis
A healthcare technology company offers a cloud service that analyzes MRI scans for early signs of disease. To serve thousands of hospitals, they need to process a high volume of images quickly and accurately. They build their data center with inference-optimized AI accelerators. These cards are designed for high throughput and low latency, allowing their platform to analyze hundreds of scans concurrently. This hardware enables them to provide a scalable, life-saving service to medical professionals worldwide.
Prototyping an AI-Powered IoT Device
A hardware startup is developing a smart home assistant that performs all voice recognition locally for privacy. The engineering team uses an AI hardware development kit. This kit includes a small single-board computer with an integrated AI accelerator, along with compatible software libraries. It allows them to rapidly prototype and test different voice recognition models directly on hardware that is similar to their final product, significantly shortening the development cycle and reducing the time to market for their innovative device.
Enhancing Scientific Computing and Simulations
Researchers in computational chemistry are simulating protein folding, a process with immense complexity. Traditional supercomputers struggle with the scale of these calculations. By using AI hardware, which excels at the tensor calculations common in these simulations, they can model molecular interactions at a much larger scale and with greater speed. This hardware-accelerated approach allows them to uncover new insights into diseases and design potential new drugs more efficiently.
Powering Generative AI Services at Scale
A popular web service allows users to generate images from text prompts. To handle millions of daily requests, the service relies on a large fleet of servers equipped with AI hardware optimized for inference. When a user submits a prompt, the request is routed to a server where the hardware rapidly executes the diffusion model to generate an image. The high parallel processing capability ensures that thousands of users can receive their generated images in seconds, providing a responsive and scalable user experience.