pdfparser
Visit Website
pdfparser Overview
pdfparser is a specialized, high-performance tool designed to unlock the data trapped within PDF files. Leveraging advanced AI and Optical Character Recognition (OCR) technology, it provides a simple yet powerful solution for converting unstructured PDF content into structured, actionable data. Whether you're dealing with native or scanned PDFs, invoices, reports, or forms, pdfparser automates the extraction process, saving countless hours of manual data entry and reducing human error. Its primary output is clean, well-organized JSON, making it incredibly easy for developers to integrate into any application or data processing pipeline.
How to use pdfparser
Using pdfparser is designed to be a straightforward process, accessible via its API for seamless integration into your projects.
- Sign Up and Get Credits: Create an account on the pdfparser website and purchase a credit package that suits your needs. One credit corresponds to the processing of one document.
- API Integration: Use your unique API key to authenticate your requests. The documentation provides clear examples for making API calls.
- Submit Your PDF: Send a POST request to the pdfparser API endpoint, including the PDF file you want to process in the request body.
- AI-Powered Processing: The service's backend will automatically analyze the document. It detects the layout, identifies text blocks, recognizes tables, and uses OCR for any image-based text.
- Receive Structured JSON: The API will return a detailed JSON object containing all the extracted content, including the raw text, structured table data (with rows and columns), and metadata about the document.
Core Features of pdfparser
- Advanced OCR Engine: Accurately extracts text from scanned documents, low-resolution images, and complex layouts, supporting multiple languages.
- Intelligent Table Extraction: Automatically detects tables within PDFs and preserves their structure, converting rows and columns into a nested JSON array for easy parsing.
- Structured JSON Output: All extracted data is delivered in a clean, predictable, and developer-friendly JSON format, ready for immediate use in databases, applications, or analytics tools.
- Scalable API: Built for developers, the robust API can handle high volumes of documents, allowing for batch processing and real-time data extraction in enterprise applications.
- Simple Credit-Based System: The transparent pay-as-you-go pricing model allows you to pay only for what you use, making it cost-effective for both small projects and large-scale operations.
Use Cases for pdfparser
pdfparser is a versatile tool applicable across numerous industries:
- Financial Automation: Automatically extract data from invoices, purchase orders, receipts, and bank statements to streamline accounting and bookkeeping.
- Data Science & Research: Parse academic papers, research reports, and datasets from PDFs to gather information for analysis without manual transcription.
- Legal and Compliance: Quickly extract clauses, case details, and key information from legal contracts, court filings, and regulatory documents.
- Logistics and Supply Chain: Digitize bills of lading, shipping manifests, and delivery notes to automate tracking and inventory management.
- Human Resources: Process resumes and application forms to extract candidate information and populate HR management systems.
Advantages of pdfparser
The key advantage of pdfparser is its focus on simplicity and power. It abstracts away the complexity of PDF parsing and OCR, providing a reliable service that just works. This leads to significantly faster development cycles for applications that rely on document data. Its high accuracy in both text and table extraction minimizes the need for manual review and correction. The scalable, credit-based model ensures that businesses of all sizes can leverage enterprise-grade document processing without a hefty upfront investment.
Pricing and Plans
pdfparser operates on a straightforward, pay-as-you-go credit system where 1 credit is used to parse 1 document.
- Lite: $1.00 for 10 credits
- Standard: $5.00 for 60 credits
- Pro: $25.00 for 500 credits
Payments are processed securely via Card or PayPal. This flexible pricing makes it accessible for developers testing an idea, small businesses automating a workflow, or large companies processing documents at scale.
pdfparser Comments (0)
Log in to post comments
Log in nowpdfparser Alternatives
View All
Finigami AI
Finigami AI offers enterprise-grade AI solutions, specializing in intelligent document processing (IDP) and custom AI development. It provides …
Finigami AI offers enterprise-grade AI solutions, specializing in intelligent document processing (IDP) and custom AI development. It provides a powerful platform to extract data from any document, including handwritten text and complex tables, and partners with businesses to build bespoke AI systems for functions like finance, HR, and operations.
CambioML
CambioML offers the AnyParser API, a powerful Vision LLM designed for high-accuracy document parsing. It extracts text, tables, …
CambioML offers the AnyParser API, a powerful Vision LLM designed for high-accuracy document parsing. It extracts text, tables, charts, and key-value pairs from PDFs, images, and Office documents. With features like PII redaction, configurable outputs, and real-time processing, it's ideal for developers and businesses in finance, research, and data analysis to automate data extraction workflows while ensuring privacy and efficiency.
hand_check
hand_check is an advanced OCR tool that uses machine learning to extract text from PDFs and images. It …
hand_check is an advanced OCR tool that uses machine learning to extract text from PDFs and images. It specializes in converting complex documents, including handwritten notes and tables, into editable text or structured JSON data. With a user-friendly interface and a powerful API for developers, it's ideal for individuals, developers, and enterprises looking to automate document processing and data extraction.
Sensible
Sensible is an API-first intelligent document processing platform for developers. It uses advanced LLM parsing and visual layout-based …
Sensible is an API-first intelligent document processing platform for developers. It uses advanced LLM parsing and visual layout-based rules to accurately extract structured data from any document, such as PDFs, images, and spreadsheets. It's designed for seamless integration, scalability, and enterprise-grade security, including SOC 2 and HIPAA compliance.
Monkt
Monkt is an AI-powered platform that transforms documents and websites into clean, AI-ready Markdown or structured JSON. It …
Monkt is an AI-powered platform that transforms documents and websites into clean, AI-ready Markdown or structured JSON. It supports various formats like PDF, Word, and Excel, offering features like OCR, batch processing, and a REST API for automating data extraction and preparing datasets for LLM training.
Doctly
Doctly is an AI-powered tool that accurately extracts data from PDFs and other documents. It converts text, tables, …
Doctly is an AI-powered tool that accurately extracts data from PDFs and other documents. It converts text, tables, figures, and charts into structured Markdown or JSON, preserving original formatting. With a simple API and high precision, it's designed for developers and businesses to automate document processing workflows.
extracta.ai
extracta.ai is an AI-powered platform designed for intelligent data extraction from documents and images. It automates the process …
extracta.ai is an AI-powered platform designed for intelligent data extraction from documents and images. It automates the process of capturing structured data from various sources like invoices, receipts, contracts, and forms, eliminating manual data entry and streamlining business workflows.
Upstage
Upstage provides high-performance, enterprise-grade AI models for businesses. Its suite includes the powerful Solar LLM for language tasks, …
Upstage provides high-performance, enterprise-grade AI models for businesses. Its suite includes the powerful Solar LLM for language tasks, advanced Document AI for parsing and extracting data with high accuracy, and flexible deployment options (API, on-premise, cloud) to automate complex workflows.
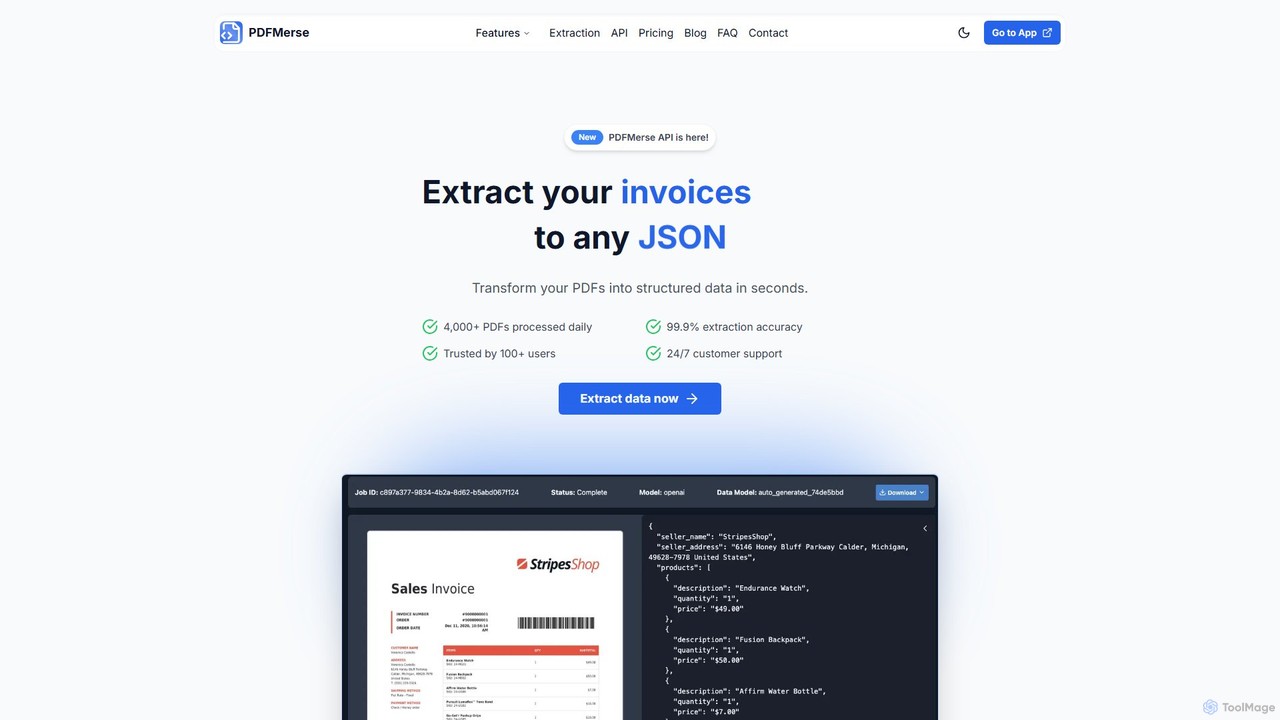
pdfmerse
pdfmerse is an AI-powered data extractor that automates the process of capturing information from any PDF document. It …
pdfmerse is an AI-powered data extractor that automates the process of capturing information from any PDF document. It intelligently converts unstructured PDF data into structured formats like JSON and text. Ideal for businesses and individuals looking to streamline document processing, reduce manual data entry, and improve workflow efficiency with high accuracy.

FormX.ai
FormX.ai is an AI-powered platform that automates data extraction from any document. It uses advanced AI, including LLMs …
FormX.ai is an AI-powered platform that automates data extraction from any document. It uses advanced AI, including LLMs and vision models, to process invoices, receipts, ID cards, and more, streamlining business workflows and improving operational efficiency.
pdfparser Category
pdfparser Tag
pdfparser AI Tool Comparison
pdfparser Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!