Webcrawlerapi
Visit Website
Webcrawlerapi Overview
Webcrawlerapi is a specialized API designed to streamline the process of web crawling and data extraction for developers. In an era where data is crucial for training large language models (LLMs) and powering AI applications, traditional web scraping presents significant challenges. These include handling dynamic JavaScript-rendered content, bypassing sophisticated anti-bot systems, managing proxies, and cleaning messy HTML into usable formats. Webcrawlerapi abstracts away all these complexities, providing a simple yet powerful interface to turn any website into a structured data source.
With a reported 98% success rate and an average crawling time of just 6 seconds, the service is built for efficiency and reliability. It allows developers to focus on their core application logic instead of getting bogged down in the intricacies of building and maintaining a scalable crawling infrastructure. By providing a link, developers can receive clean, ready-to-use content in formats like Markdown, text, or raw HTML, making it perfect for feeding into AI model training pipelines or knowledge bases for RAG systems.
How to use Webcrawlerapi
Integrating Webcrawlerapi into your project is designed to be straightforward. The process typically involves just a few lines of code. First, you need to sign up on the Webcrawlerapi website to obtain your unique API access key. Then, you can use one of their provided client libraries for popular programming languages.
For example, in a NodeJS environment, you would start by installing the client library via npm: npm i webcrawlerapi-js. Then, in your code, you import the library, create a new client instance with your API key, and call the `crawl` method. This method takes parameters such as the target `url`, the desired `scrape_type` (e.g., 'markdown'), and optional limits like `items_limit`. The API then handles the entire crawling process in the background and returns a structured JSON response with the extracted data. Similar simple integration patterns are available for Python, PHP, and .NET, making it accessible to a wide range of developers.
Core Features of Webcrawlerapi
- Automated Link Handling: The API intelligently discovers and manages all internal links on a website, ensuring comprehensive crawling while automatically handling duplicates and cleaning URLs.
- Advanced JavaScript Rendering: It effectively renders dynamic, client-side content using a stable and robust system, overcoming the instability and memory issues often associated with tools like Puppeteer or Playwright.
- Robust Anti-Bot Evasion: Webcrawlerapi comes with built-in mechanisms to deal with CAPTCHAs, IP blocks, rate limits, and other common anti-bot defenses, ensuring a high success rate.
- Automatic Data Cleaning: It includes powerful parsing rules to convert raw, complex HTML into clean, structured formats like Markdown or plain text, saving developers significant post-processing time.
- Scalable Infrastructure: The service manages a distributed infrastructure of crawlers and proxies, allowing you to scale your data extraction efforts from a few pages to millions without worrying about the underlying hardware or network management.
- Developer-Friendly API & SDKs: Offers a simple API and official client libraries for major languages like NodeJS, Python, PHP, and .NET, complete with clear documentation.
Use Cases for Webcrawlerapi
Webcrawlerapi is versatile and can be applied to a variety of data-intensive tasks. Its primary use cases revolve around AI and data analysis.
- LLM Training Data Collection: Systematically crawl websites, blogs, and forums to gather vast amounts of high-quality, domain-specific text data for training or fine-tuning custom large language models.
- Retrieval-Augmented Generation (RAG): Build and maintain up-to-date knowledge bases for RAG systems. Crawl product documentation, help centers, or news sites to provide LLMs with accurate, real-time information to answer user queries.
- Market Research and Competitive Analysis: Automatically extract product details, pricing information, customer reviews, and marketing content from competitor websites to gain strategic insights.
- Content Aggregation: Power news aggregators, job boards, or real estate listing sites by regularly crawling multiple sources and consolidating the data into a unified platform.
Advantages of Webcrawlerapi
The main advantage of Webcrawlerapi is its simplicity and efficiency. It allows development teams to offload the entire web crawling infrastructure and maintenance burden. This means faster time-to-market for data-driven products. The high success rate (98%) and robust anti-bot features ensure data pipelines are reliable. Furthermore, its transparent, pay-as-you-go pricing model is highly cost-effective, as you only pay for successful requests, eliminating the risk and overhead associated with subscriptions or building an in-house solution.
Pricing and Plans
Webcrawlerapi employs a straightforward and transparent 'pay-for-usage' pricing model, completely avoiding subscriptions and hidden fees. Costs are calculated based on the number of pages you successfully crawl each month. The service includes unlimited crawl jobs, an unlimited and automatically managed proxy network, and email support in its pricing. For a clear cost estimation, the website provides a calculator. As an example, crawling 10,000 pages in a month would cost approximately $20. This model is ideal for projects of all sizes, from small-scale experiments to large-scale data operations, as costs scale directly with usage. The platform also allows users to try the service before making a purchase, likely through a free credit allocation for new accounts.
Webcrawlerapi Comments (0)
Log in to post comments
Log in nowWebcrawlerapiWebsite Traffic Analysis
Latest Traffic
Status
Monthly Traffic Trend
Geography
Top 5 Countries/Regions
-
🇺🇸 United States51.51%
-
🇮🇳 India14.82%
-
🇩🇪 Germany12.24%
-
🇪🇸 Spain11.01%
-
🇧🇷 Brazil10.42%
Popular Keywords
| Keyword | Cost Per Click |
|---|---|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
Webcrawlerapi Alternatives
View All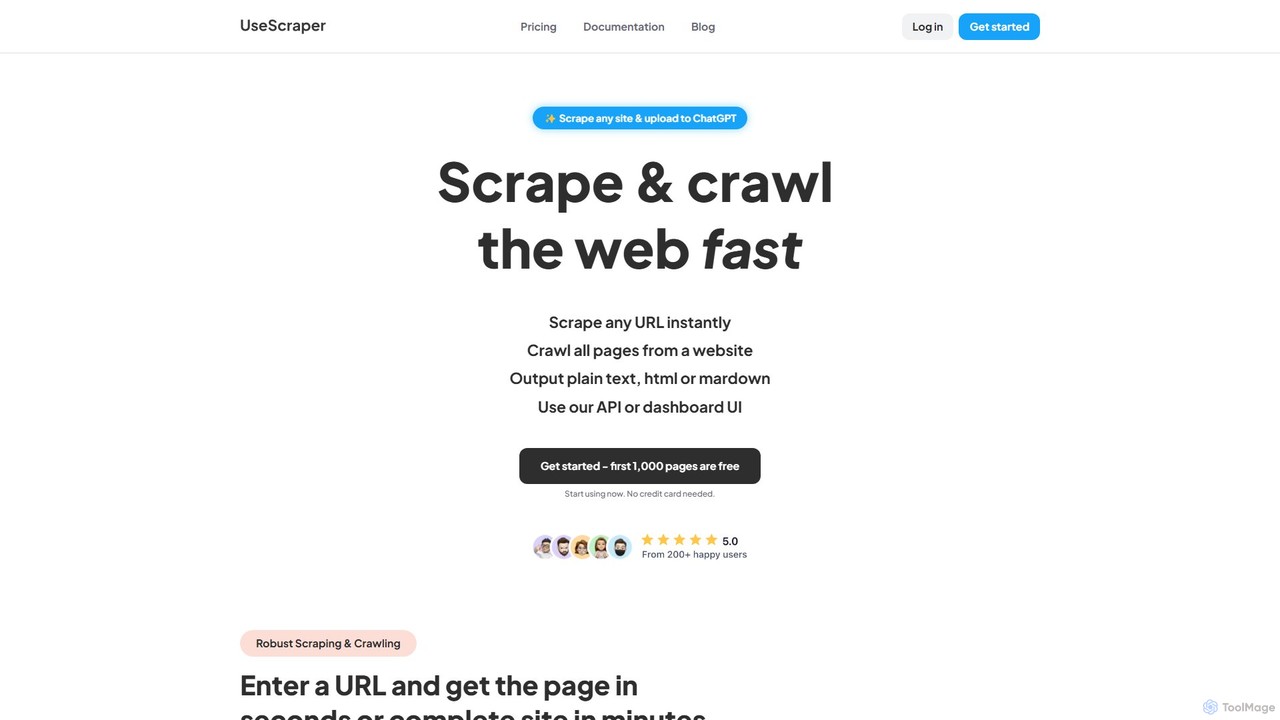
UseScraper
UseScraper is a powerful web crawler and scraper API designed for developers and AI applications. It efficiently extracts …
UseScraper is a powerful web crawler and scraper API designed for developers and AI applications. It efficiently extracts data from any website, featuring full JavaScript rendering, auto-scaling infrastructure, and clean output formats like Markdown, ideal for feeding data into LLMs like ChatGPT.

Foxscrape
FoxScrape is an AI-powered web scraping REST API for developers. It simplifies data extraction by converting any website …
FoxScrape is an AI-powered web scraping REST API for developers. It simplifies data extraction by converting any website into structured JSON data using features like AI-driven parsing from plain English, JavaScript rendering for dynamic sites, and automatic proxy rotation to prevent blocks.
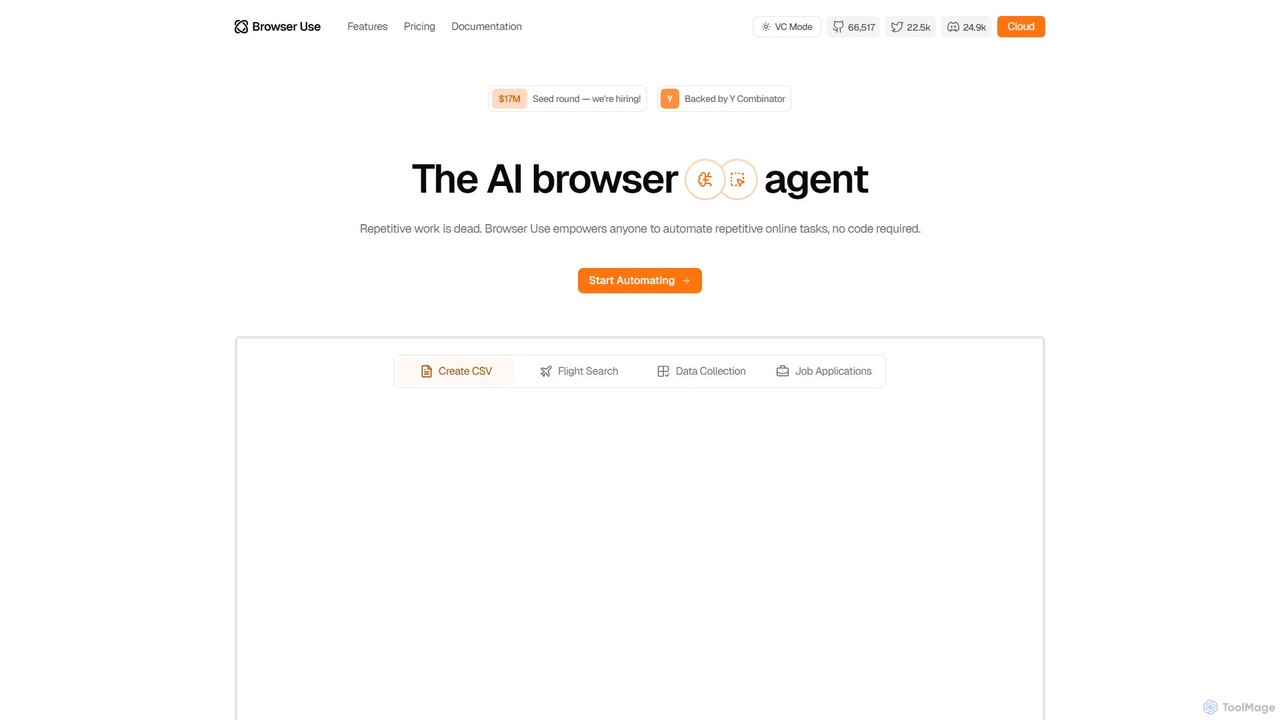
Browser Use
Browser Use is an AI-powered browser agent that automates repetitive online tasks without requiring any code. It can …
Browser Use is an AI-powered browser agent that automates repetitive online tasks without requiring any code. It can handle complex data scraping, form filling, and other web-based workflows. Backed by Y Combinator, it offers a simple chat interface for users and a powerful API for developers to streamline their online activities.
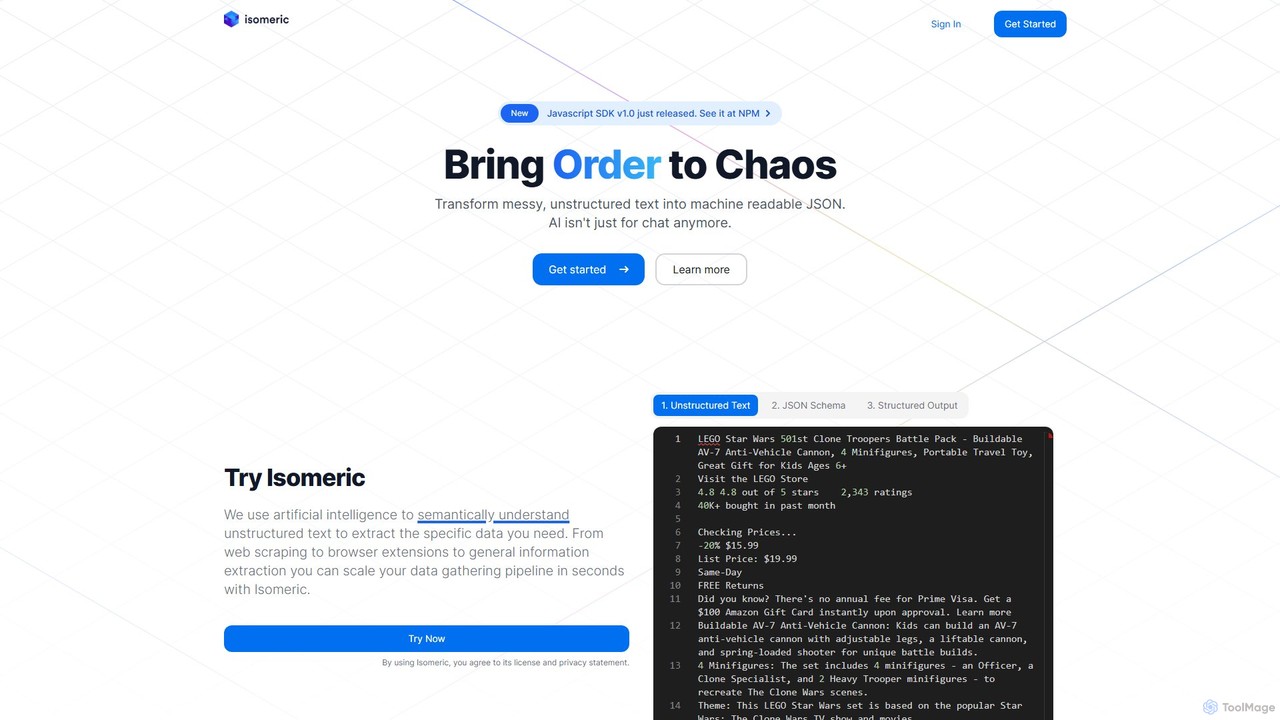
Isomeric
Isomeric is an AI-powered API that transforms messy, unstructured text from any source into clean, structured JSON data. …
Isomeric is an AI-powered API that transforms messy, unstructured text from any source into clean, structured JSON data. By defining a simple JSON schema, you can automatically extract specific information from websites, legal documents, customer support transcripts, and more, streamlining data pipelines and automation.
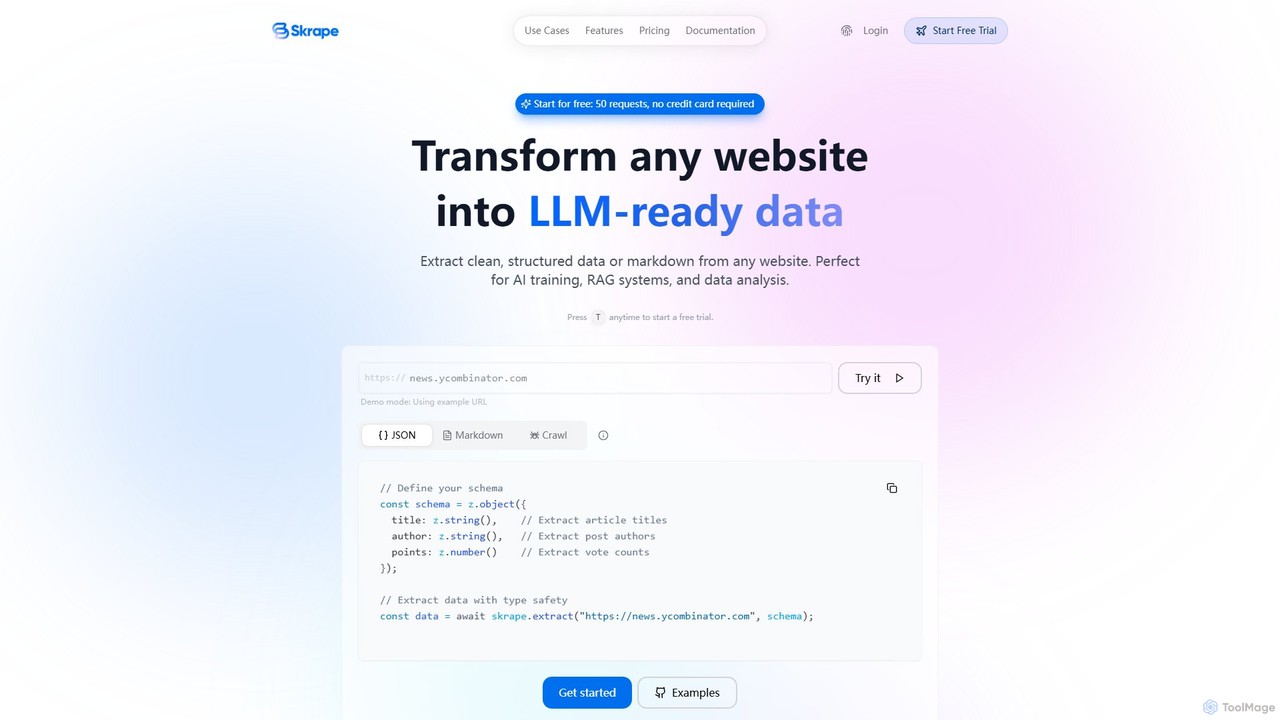
Skrape
Skrape is an LLM-powered web scraping API designed to transform any website into clean, structured, and LLM-ready data. …
Skrape is an LLM-powered web scraping API designed to transform any website into clean, structured, and LLM-ready data. It simplifies data extraction by converting web pages into structured JSON or clean markdown, making it ideal for AI training, RAG systems, and data analysis. With features like dynamic content handling and smart crawling, Skrape provides a reliable solution for developers and businesses to automate their data collection pipelines.
instantapi
instantapi is an AI-powered web scraping API designed for simplicity and speed. It allows users to extract structured …
instantapi is an AI-powered web scraping API designed for simplicity and speed. It allows users to extract structured data from any website with a single API call, eliminating the need for complex coding or manual setup. Ideal for developers, data analysts, and businesses who need fast, affordable, and reliable data extraction without the hassle of traditional web scrapers.
Scrapeless
An AI-powered web scraping toolkit for developers and businesses. It offers a suite of tools including a Scraping …
An AI-powered web scraping toolkit for developers and businesses. It offers a suite of tools including a Scraping Browser, Universal Scraping API, and Deep SERP API to effortlessly extract public web data at scale. It specializes in bypassing anti-bot measures, providing structured data for e-commerce, market research, and AI model training, with a focus on reliability and ease of use.
Textraction
Textraction is a powerful AI-powered API that transforms unstructured text into structured data. By simply describing the information …
Textraction is a powerful AI-powered API that transforms unstructured text into structured data. By simply describing the information you need in natural language, you can extract any entity from documents, emails, or web content. With seamless API and Zapier integration, it automates data extraction, converting messy text into clean, table-ready JSON format, supporting multiple languages and endless custom use cases.

CapSolver
CapSolver is an AI-powered, automatic CAPTCHA solving service designed for developers and RPA professionals. It provides a high-accuracy, …
CapSolver is an AI-powered, automatic CAPTCHA solving service designed for developers and RPA professionals. It provides a high-accuracy, fast, and scalable solution to bypass various types of CAPTCHAs, including reCAPTCHA, hCaptcha, and FunCaptcha, facilitating seamless web scraping, data extraction, and process automation.

Apify
Apify is a full-stack web scraping and automation platform that enables developers to build, deploy, and publish data …
Apify is a full-stack web scraping and automation platform that enables developers to build, deploy, and publish data extraction tools, known as 'Actors'. It offers a vast marketplace of pre-built scrapers for popular websites like Google Maps, Instagram, and TikTok, alongside a robust cloud infrastructure for creating custom solutions. With support for Python and JavaScript, open-source libraries, and seamless integrations, Apify simplifies collecting web data at any scale.
Webcrawlerapi Category
Webcrawlerapi Tag
Webcrawlerapi AI Tool Comparison
Webcrawlerapi Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!