Wirestock
A marketplace connecting creative freelancers with AI companies, enabling creators to earn money by contributing high-quality images, videos, …
A marketplace connecting creative freelancers with AI companies, enabling creators to earn money by contributing high-quality images, videos, and illustrations for AI training datasets.
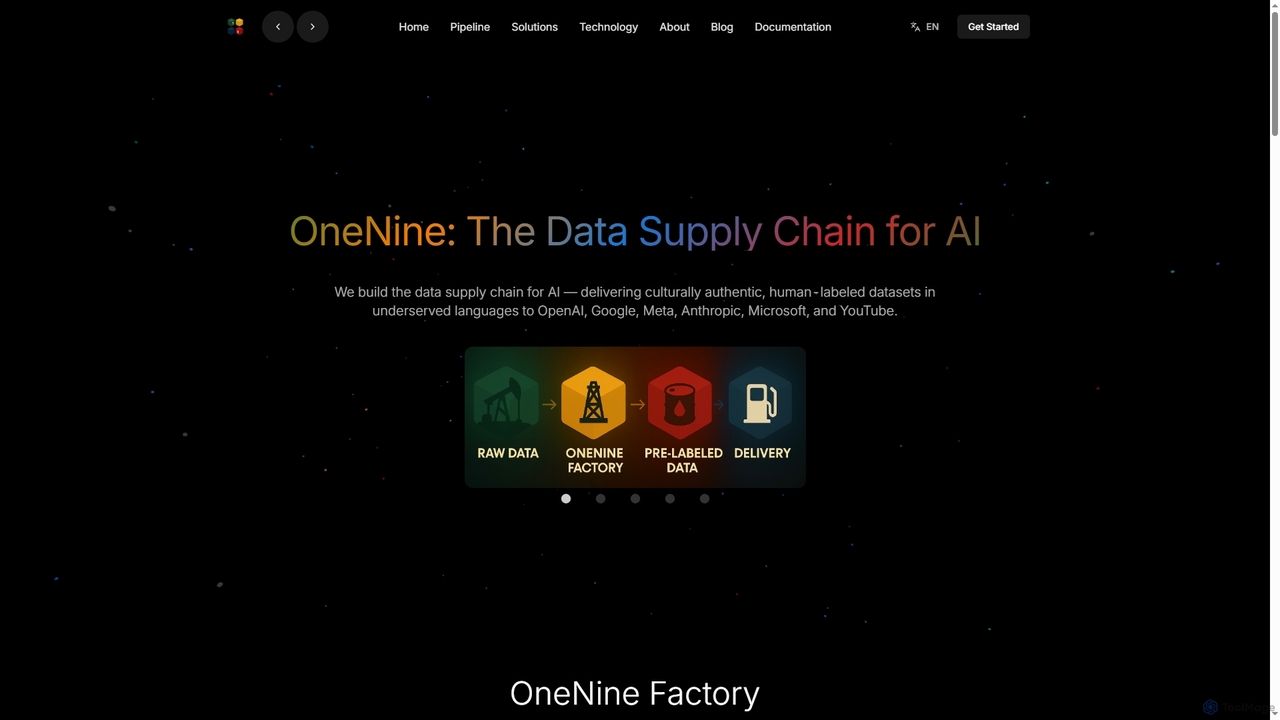
OneNine
OneNine is the data supply chain for AI, specializing in delivering high-quality, culturally authentic, human-labeled datasets in underserved …
OneNine is the data supply chain for AI, specializing in delivering high-quality, culturally authentic, human-labeled datasets in underserved languages to leading AI companies. It bridges the linguistic gap, enabling more inclusive and accurate AI models globally.

Sapien
Sapien is a decentralized data foundry that provides enterprise-grade AI training data. It leverages a global network of …
Sapien is a decentralized data foundry that provides enterprise-grade AI training data. It leverages a global network of human contributors to deliver high-quality, specialized data for complex AI systems, including 3D/4D annotation, expert reasoning, and large-scale data collection.
About Training Data
Training Data tools are platforms and services designed to create, manage, and provide high-quality datasets for machine learning models. These tools streamline the critical process of data preparation, offering functionalities for data annotation, synthetic data generation, and quality assurance. Their primary value lies in accelerating the development of accurate and robust AI systems, as the performance of any model is fundamentally dependent on the quality of its training data. As a key component of the AI Development lifecycle, they form the foundation upon which effective models are built.
Core Features
- Data Annotation & Labeling: Provides interfaces and automated tools for accurately tagging various data types, such as images, text, and audio, to create ground truth for models.
- Synthetic Data Generation: Creates artificial, yet realistic, data to augment limited datasets, cover edge cases, or protect sensitive information.
- Data Management & Versioning: Offers a centralized platform to store, track, and manage different versions of datasets, ensuring experiment reproducibility.
- Quality Assurance Workflows: Includes features for review, consensus, and error detection to maintain high standards of data accuracy and consistency.
- Dataset Sourcing: Provides access to pre-labeled, off-the-shelf datasets or services to collect and prepare custom data.
Use Cases
These tools are essential in data-intensive industries like autonomous vehicles for object detection, healthcare for medical image analysis, and retail for product categorization. Machine learning engineers, data scientists, and AI researchers use them daily to build and refine datasets for tasks ranging from natural language processing to computer vision.
How to Choose
When selecting a Training Data tool, consider its support for your specific data types (e.g., video, 3D point clouds). Evaluate the quality control mechanisms, such as reviewer roles and consensus scoring. Assess its scalability for large-scale projects and its ability to integrate with your existing MLOps pipeline and cloud storage. Finally, verify its security protocols and compliance with data privacy regulations like GDPR or HIPAA.
Training DataUse Cases
Training Autonomous Vehicle Perception Models
An automotive technology company developing self-driving cars needs to train its computer vision models to accurately identify pedestrians, vehicles, traffic signs, and lane markings. Using a data annotation platform, a team of labelers performs semantic segmentation and bounding box annotation on millions of images and video frames captured from road tests. The platform's quality control features, such as consensus scoring and reviewer workflows, ensure high accuracy. This meticulously labeled dataset is crucial for training perception models that can safely navigate complex urban environments.
Developing a Medical Imaging Diagnostic AI
A healthcare research institute aims to build an AI model to detect early-stage tumors in MRI scans. Due to the scarcity of expert radiologists and the high cost of manual annotation, they use a specialized medical imaging annotation tool. This tool offers features like DICOM support and semi-automated segmentation, which speeds up the process. To protect patient privacy, all data is anonymized within the platform. The resulting high-quality, labeled dataset enables the data science team to train a model that can assist radiologists by highlighting potential areas of concern, leading to earlier and more accurate diagnoses.
Generating Synthetic Data for Fraud Detection
A financial services company wants to improve its fraud detection model but is limited by the small number of real fraud examples and strict data privacy regulations. They use a synthetic data generation tool to create a large, balanced dataset of financial transactions. The tool models the statistical properties of their real data to generate realistic but entirely artificial transaction records, including complex fraud scenarios that are rare in the real world. This allows them to train a more robust model without using sensitive customer data, improving detection rates while maintaining full compliance.
Improving E-commerce Product Categorization
An online retail giant manages millions of products, and manually categorizing new items is slow and error-prone. They employ a data labeling service to classify a large dataset of product images and descriptions. The service uses a combination of human annotators and AI-powered pre-labeling to efficiently categorize products into a detailed taxonomy. This labeled data is then used to train a machine learning model that automatically assigns categories to new products uploaded to the site, significantly reducing manual effort, improving search relevance, and enhancing the customer shopping experience.
Managing Datasets for NLP Model Reproducibility
An AI research lab is developing a new language model and needs to run hundreds of experiments with different versions of their text corpus. To ensure their results are reproducible, they use a data management and versioning platform. This tool allows them to track every change to the dataset, link specific dataset versions to model training runs, and easily revert to previous states. It acts like 'Git for data,' providing a clear audit trail and preventing confusion. This systematic approach is vital for collaborative research and for publishing verifiable scientific findings.
Auditing Datasets for Bias in Hiring Algorithms
A human resources technology firm is building an AI tool to help screen resumes. To prevent perpetuating historical biases, they use a data quality assurance tool to audit their training dataset. The tool analyzes the distribution of demographic data (e.g., gender, ethnicity) and identifies potential imbalances or correlations that could lead to unfair outcomes. It provides visualizations and statistical reports that help the data science team identify and mitigate bias before model training. This proactive step is essential for developing responsible and ethical AI systems that promote fair hiring practices.