GrowTechie
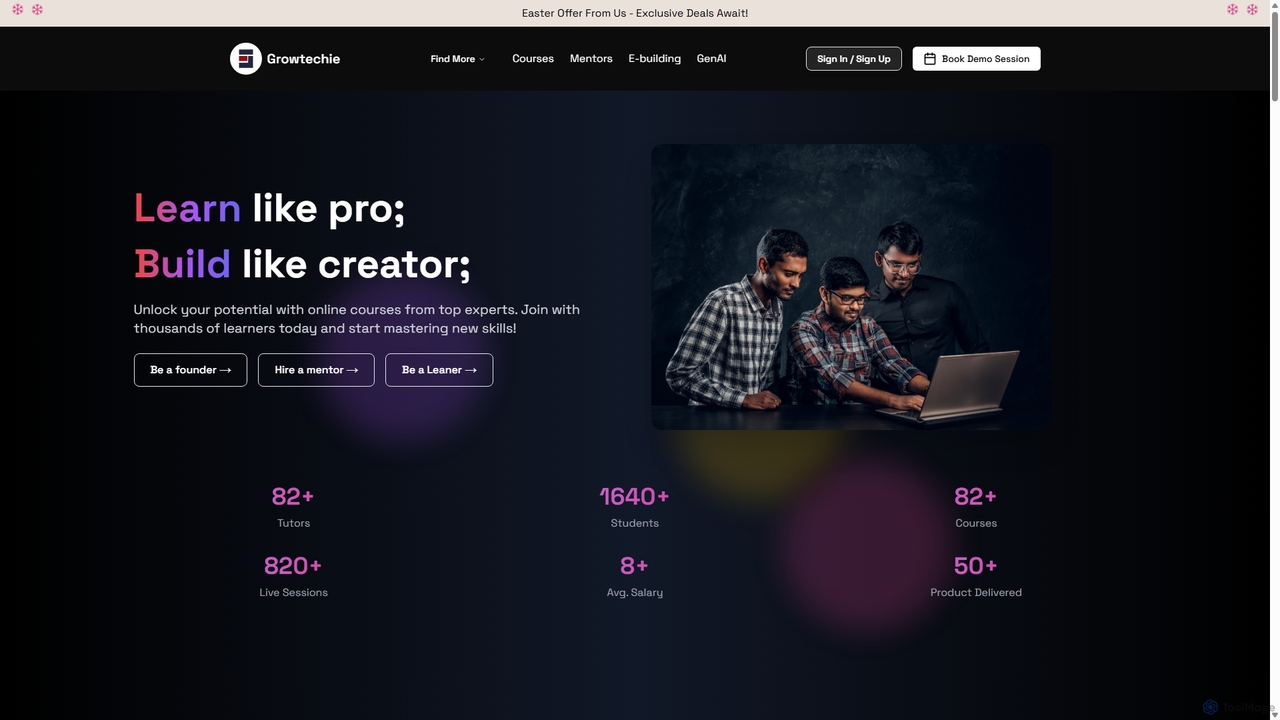
GrowTechie is an online learning platform dedicated to democratizing tech education. It offers expert-led courses, personalized mentorship, and …
GrowTechie is an online learning platform dedicated to democratizing tech education. It offers expert-led courses, personalized mentorship, and project-based learning in high-demand fields like AI Engineering, Data Science, Programming, and UI/UX Design. The platform focuses on equipping learners with practical, real-world skills to build products and advance their careers.
Interview Shepherd
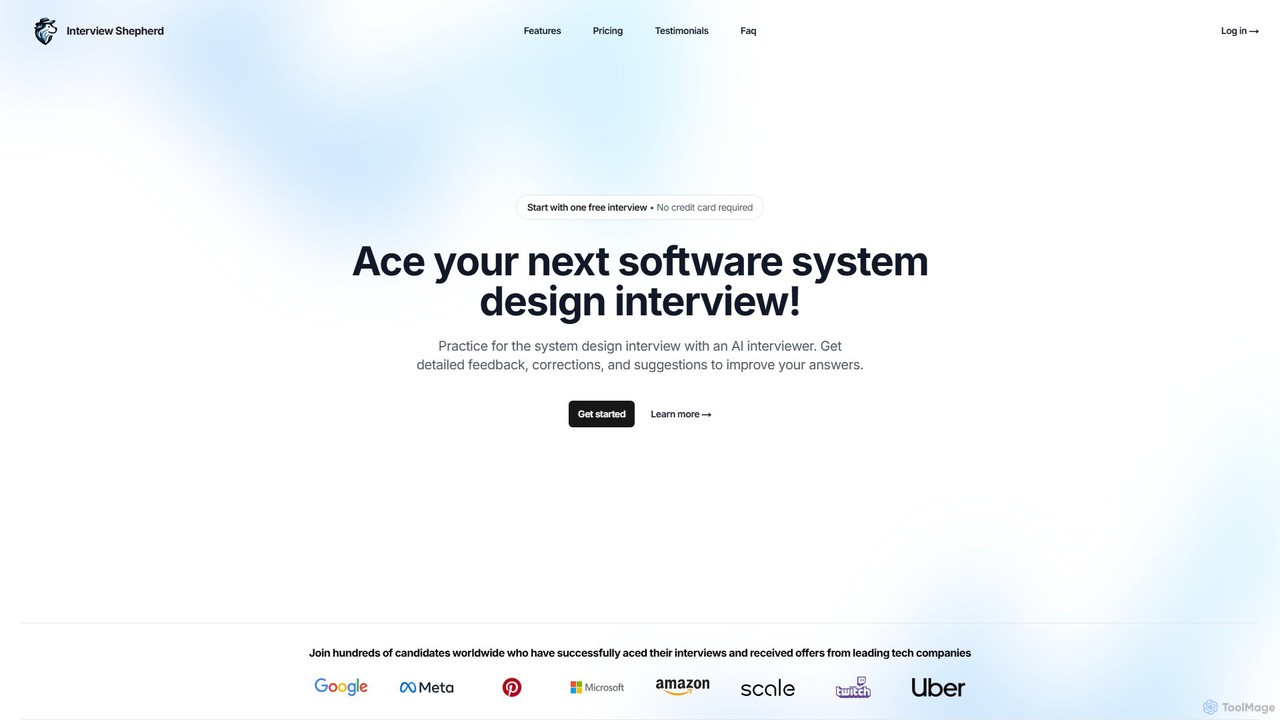
Interview Shepherd is an AI-powered platform for software engineers to master system design interviews. It features a realistic …
Interview Shepherd is an AI-powered platform for software engineers to master system design interviews. It features a realistic AI interviewer, an interactive whiteboard, and provides instant, detailed feedback with performance analysis. This helps candidates practice effectively, build confidence, and secure offers from leading tech companies.
StudyRaid
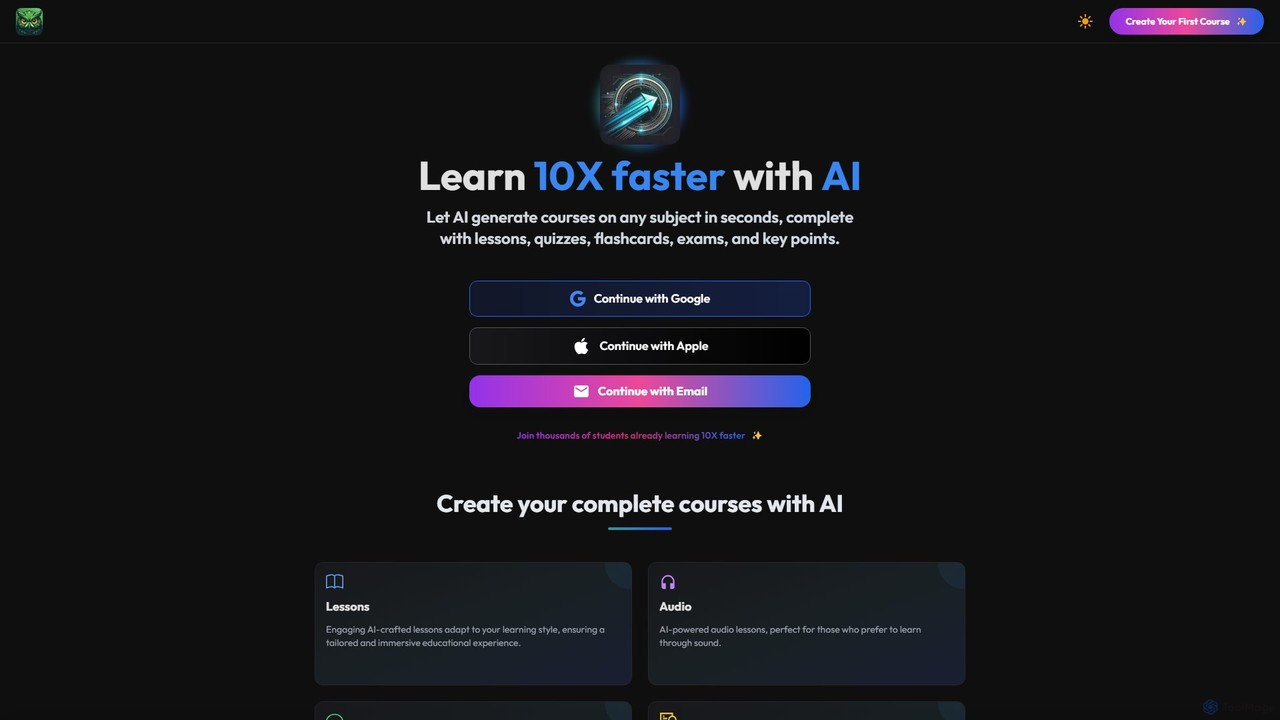
StudyRaid is an AI-powered learning platform that generates complete courses on any subject in seconds. It creates tailored …
StudyRaid is an AI-powered learning platform that generates complete courses on any subject in seconds. It creates tailored lessons, quizzes, flashcards, exams, and summaries to accelerate learning. Ideal for students, educators, and professionals, it personalizes the educational experience, making learning 10 times faster and more efficient.
About Training
AI Training tools are specialized platforms designed to manage the entire lifecycle of training and fine-tuning machine learning models. These tools provide managed infrastructure, including access to GPUs and TPUs, and workflow automation to streamline complex development processes. They empower developers and data scientists to systematically track experiments, optimize model parameters, and scale training from a single machine to distributed clusters. As a core component of the Developer Tools ecosystem, they accelerate the path from raw data and code to a high-performing, production-ready model.
Core Features
- Experiment Tracking: Log, compare, and visualize metrics, parameters, and artifacts from every training run to ensure reproducibility.
- Hyperparameter Optimization: Automate the search for the best model configurations using algorithms like Bayesian optimization or grid search.
- Managed Compute Environment: Provide on-demand access to powerful hardware (GPUs/TPUs) without the need for manual infrastructure setup.
- Distributed Training Support: Simplify the process of scaling model training across multiple nodes to reduce training time for large models and datasets.
- Model & Data Versioning: Integrate with version control systems to link specific model versions with the exact code and data used to train them.
Use Cases
These tools are essential for machine learning engineers, data scientists, and AI researchers. They are widely used in industries like tech, healthcare, and finance for tasks such as training large language models (LLMs), developing computer vision algorithms for medical diagnostics, or building predictive models for financial markets. The focus is on creating a structured, reproducible, and efficient model development environment.
How to Choose
When selecting an AI Training tool, consider its support for your preferred ML frameworks (e.g., PyTorch, TensorFlow). Evaluate its scalability and the availability of different compute resources. Assess its integration capabilities with other MLOps tools for deployment and monitoring. Finally, compare pricing models and the balance between user-friendly UI-driven workflows and the flexibility of code-based configuration.
TrainingUse Cases
Fine-tuning an LLM for Customer Support
A machine learning engineer at an e-commerce company needs to build a specialized chatbot. Using an AI Training platform, they take a pre-trained large language model (LLM) like Llama 3 and fine-tune it on their company's historical customer support conversations. The platform manages the GPU allocation, tracks the model's performance (e.g., perplexity, accuracy) across different epochs, and logs all hyperparameters. This process results in a custom model that understands company-specific jargon and provides more accurate, relevant answers, reducing the workload on human agents.
Training a Computer Vision Model for Medical Imaging
A data scientist in a healthcare research institute is developing an algorithm to detect anomalies in MRI scans. They use an AI Training tool to manage their large dataset of images and train a convolutional neural network (CNN). The tool's experiment tracking feature is crucial for comparing different model architectures and data augmentation techniques. By running multiple experiments in parallel on a GPU cluster managed by the platform, they can iterate much faster. The final, validated model can assist radiologists by highlighting potential areas of concern, improving diagnostic accuracy.
Collaborative Experiment Tracking for a Research Team
An academic research team is working on a novel reinforcement learning algorithm. Team members are geographically distributed. They use a centralized AI Training platform to manage their work. Each researcher can launch training jobs, and the platform automatically logs the code version, hyperparameters, and resulting performance metrics. This creates a shared, transparent dashboard where the team can compare results, identify the most promising approaches, and build upon each other's work without confusion. It ensures that all experiments are reproducible and prevents duplicated effort.
Automating Hyperparameter Search for a Fraud Detection Model
An ML engineer at a fintech company is optimizing a gradient boosting model for fraud detection. Manually testing combinations of learning rate, tree depth, and regularization is time-consuming. They use the hyperparameter optimization (HPO) feature of their training platform. They define the search space for each parameter and let the platform's automated algorithm (e.g., Bayesian optimization) run dozens of training jobs to find the optimal combination. The platform visualizes the results, showing which parameter ranges yield the best performance, leading to a more accurate model in a fraction of the time.
Scaling NLP Model Training with Distributed Computing
An AI researcher is training a large transformer model on a massive text corpus. Training on a single GPU would take months. They leverage a training platform's distributed training capabilities. By writing a small amount of configuration code, they can distribute the training job across a cluster of 16 high-end GPUs. The platform handles the complexities of data parallelism and synchronization between nodes. This reduces the total training time from months to just a few days, enabling them to experiment with larger models and achieve state-of-the-art results much more quickly.
Building Reproducible Training Pipelines for Compliance
A data science team in a financial institution must ensure their credit scoring models are fair and auditable. They use an AI Training platform to build end-to-end, versioned pipelines. Every time the model is retrained, the platform captures the exact data version, feature engineering code, training script, and resulting model artifact. This creates an immutable audit trail. When regulators ask for proof of how a specific model was built, the team can instantly retrieve the entire lineage, demonstrating compliance and ensuring the process is fully reproducible.