Trismik
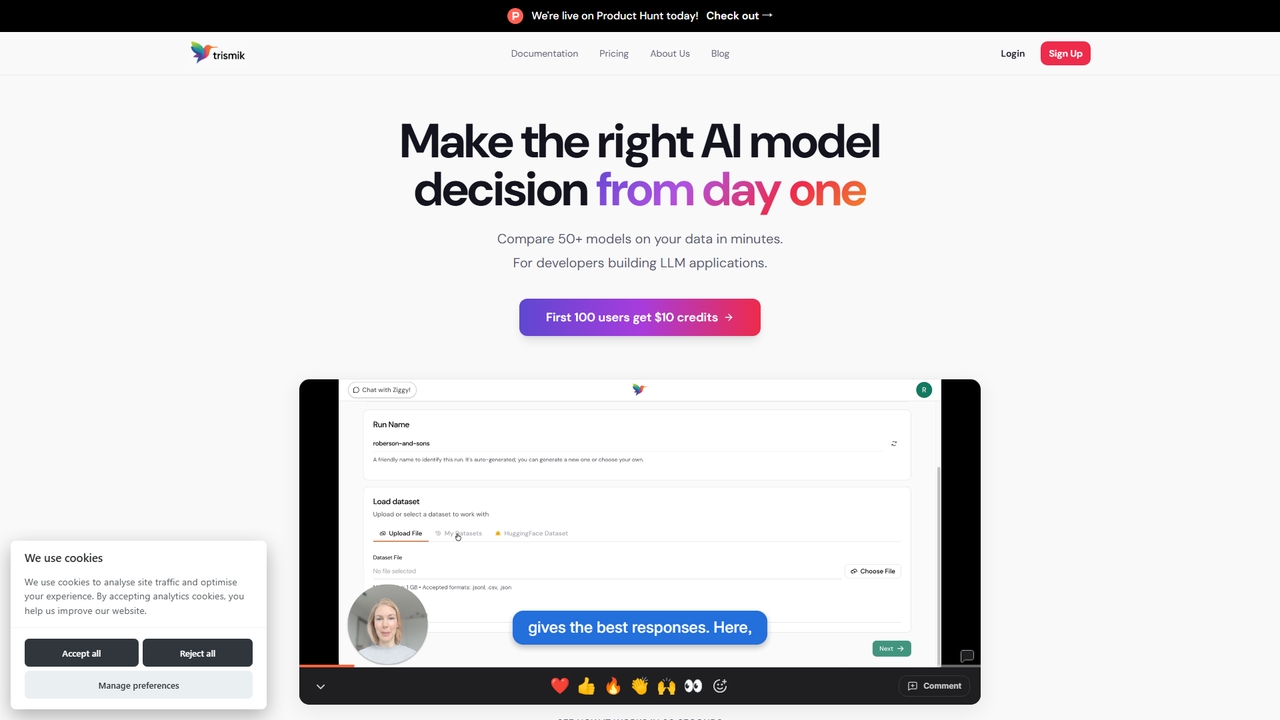
Compare 50+ LLMs on your own data in minutes. Make evidence-based model decisions on quality, cost, and speed …
Compare 50+ LLMs on your own data in minutes. Make evidence-based model decisions on quality, cost, and speed without guesswork.
Compare AI Models
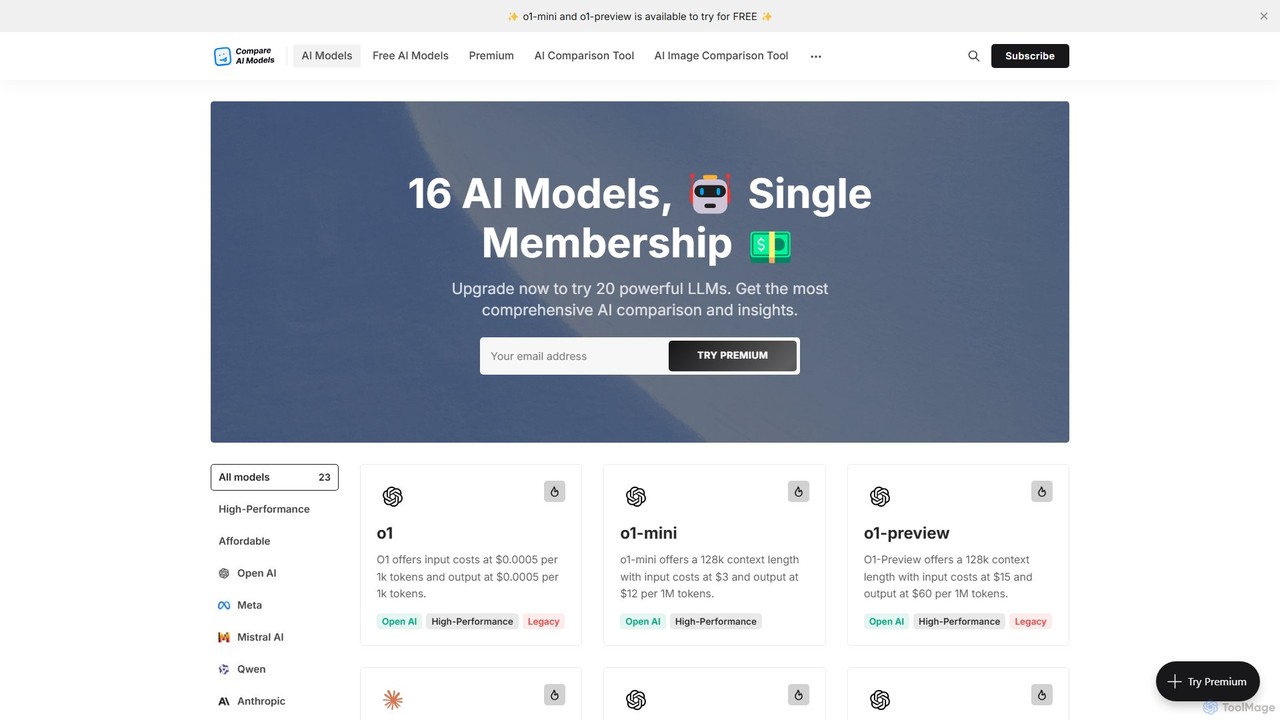
A comprehensive platform for comparing over 20 leading Large Language Models (LLMs). It offers detailed metrics on performance, …
A comprehensive platform for comparing over 20 leading Large Language Models (LLMs). It offers detailed metrics on performance, API pricing, context windows, and features, along with a free chat to test models directly. An essential tool for developers, researchers, and businesses to find the perfect AI for their needs.
Joythee AI
Joythee AI is an advanced conversational AI platform that allows you to chat with multiple AI agents simultaneously. …
Joythee AI is an advanced conversational AI platform that allows you to chat with multiple AI agents simultaneously. Compare responses from various LLMs in a single interface, enjoy personalized conversations, and protect your privacy with an incognito mode. Ideal for individuals, teams, and enterprises seeking enhanced productivity and creativity.
About Model Comparison
Model Comparison tools are specialized platforms within the developer toolkit designed to systematically evaluate, benchmark, and compare the performance of different AI models. These tools provide a structured environment for running models like LLMs or image generators against the same inputs and datasets to measure their outputs objectively. They are essential for making data-driven decisions, enabling developers and researchers to select the most accurate, cost-effective, and efficient model for a specific application. By offering side-by-side analysis and quantitative metrics, they streamline the otherwise complex and time-consuming process of model selection.
Core Features
- Side-by-Side Playground: Instantly compare outputs from multiple models for the same prompt in a unified interface.
- Automated Benchmarking: Run standardized industry benchmarks (e.g., MMLU, HumanEval) to score models on various capabilities.
- Cost and Latency Analysis: Track and compare the financial cost and response time for each model's inference.
- Qualitative Evaluation: Facilitate human feedback and scoring on subjective criteria like coherence, style, or safety.
- Version Control & History: Log and track evaluation experiments over time to monitor performance changes and regressions.
Use Cases
These tools are critical for AI developers, MLOps engineers, and product managers during the development and maintenance lifecycle. They are used when selecting a foundational model for a new feature, evaluating the impact of fine-tuning, or conducting regression testing after a model update. For instance, a team building a customer service chatbot would use these tools to compare the conversational abilities and costs of models from OpenAI, Anthropic, and Google before committing to one.
How to Choose
When selecting a Model Comparison tool, consider the breadth of supported models, including both proprietary APIs and open-source options. Evaluate the available benchmark suites and the flexibility to create custom evaluation datasets. Assess its integration capabilities with your existing MLOps workflow and CI/CD pipelines. Finally, consider collaboration features that allow team members to review results and pricing models that scale with your evaluation needs.
Model ComparisonUse Cases
Selecting the Optimal LLM for a New Chatbot
A product team is developing a new AI-powered customer support chatbot. They use a model comparison tool to evaluate GPT-4, Claude 3 Sonnet, and Llama 3 70B. They create a 'golden dataset' of 100 common customer queries and run all three models against it. The platform provides a side-by-side view of the responses, along with automated metrics for helpfulness and tone. It also calculates the average cost per 1,000 conversations for each model. Based on the results, they choose Claude 3 Sonnet as it offers the best balance of conversational quality and operational cost for their specific use case.
Evaluating Fine-Tuned Model Performance
An ML engineer has fine-tuned an open-source Mistral 7B model on internal company documents for a question-answering task. To justify the deployment, they use a comparison tool to benchmark the fine-tuned model against the base Mistral 7B and a proprietary model like GPT-4. They upload a test set of 50 technical questions. The tool measures factual accuracy and relevance. The results show that their fine-tuned model outperforms the base model by 30% in accuracy and is 10 times cheaper than GPT-4, providing clear evidence to proceed with deployment.
Regression Testing for Model API Updates
An MLOps team manages a summarization feature that relies on an external model API. The API provider announces a new version. Before switching, the team uses a model comparison platform to run their suite of 500 test documents through both the old and new API versions. The platform automatically flags any summaries from the new version that are significantly shorter, less coherent, or factually incorrect compared to the old version's output. This automated regression testing prevents a degradation in service quality and ensures a smooth transition to the updated model.
Comparing Image Generation Models for Marketing
A marketing agency needs to select an image generation model for creating ad creatives. They use a comparison tool to test DALL-E 3, Midjourney, and Stable Diffusion with 20 different prompts related to their client's products. The tool allows their creative team to rate each generated image on a 1-5 scale for prompt adherence, aesthetic quality, and brand alignment. The aggregated scores reveal that while Midjourney produces the most aesthetically pleasing images, DALL-E 3 is superior at accurately incorporating specific product details mentioned in the prompts, making it the better choice for their needs.
Optimizing Cost-Performance for a Summarization API
A news aggregation service uses an LLM to summarize articles. To reduce costs, they want to find the cheapest model that maintains quality. Using a comparison tool, they test five different models, from the high-end GPT-4 to smaller, open-source alternatives. They run 1,000 articles through each and use automated ROUGE scores to measure summary quality, while the tool tracks the cost for each model. They discover that a quantized version of a Llama 3 8B model provides 95% of the quality of GPT-4 at only 10% of the cost, leading to significant monthly savings.
A/B Testing Prompts Across Multiple Models
A prompt engineer is tasked with creating the most effective prompt for a code generation feature. Instead of testing prompts one by one, they use a model comparison tool to set up a matrix experiment. They input three different prompt variations and test them across four models (e.g., GPT-4, Claude 3 Opus, Gemini Pro, and a specialized code model). The platform runs all 12 combinations and presents the results in a heatmap, showing which prompt-model pair produces the most accurate and efficient code. This accelerates the prompt optimization process tenfold.