Oneinfer
Oneinfer 是一个面向开发人员的高性能 AI 推理平台。它提供统一的 API 来访问超过 15 种 LLM(如 GPT-4 和 Claude),从而简化 AI 集成。该平台具有无服务器部署、自动扩展、企业级安全性和按使用付费的定价模式。它还为自定义 AI 工作负载提供了一个租用 GPU 实例的市场。
Oneinfer 是一个面向开发人员的高性能 AI 推理平台。它提供统一的 API 来访问超过 15 种 LLM(如 GPT-4 和 Claude),从而简化 AI 集成。该平台具有无服务器部署、自动扩展、企业级安全性和按使用付费的定价模式。它还为自定义 AI 工作负载提供了一个租用 GPU 实例的市场。


BrainHost
BrainHost 提供高性能 KVM VPS 主机服务,采用 NVMe 存储,专为速度和可靠性设计。它支持 30 秒快速部署,在全球(香港和美国西部)设有数据中心,并配备直观的 VirtFusion 控制面板。BrainHost 为网站、电子商务、AI 推理和游戏应用提供强大的基础设施,灵活的扩展能力和先进的网络路由确保全球范围内稳定快速的访问。
BrainHost 提供高性能 KVM VPS 主机服务,采用 NVMe 存储,专为速度和可靠性设计。它支持 30 秒快速部署,在全球(香港和美国西部)设有数据中心,并配备直观的 VirtFusion 控制面板。BrainHost 为网站、电子商务、AI 推理和游戏应用提供强大的基础设施,灵活的扩展能力和先进的网络路由确保全球范围内稳定快速的访问。
UltiHash
UltiHash 是一个专为 AI 和大数据工作负载打造的高性能、Kubernetes 原生对象存储平台。它通过先进的字节级重复数据删除技术提供闪电般的数据访问速度和显著的成本节约,并支持在云、本地或混合环境中灵活部署。其 S3 兼容的 API 确保了与现有数据栈和 AI 工作流的无缝集成。
UltiHash 是一个专为 AI 和大数据工作负载打造的高性能、Kubernetes 原生对象存储平台。它通过先进的字节级重复数据删除技术提供闪电般的数据访问速度和显著的成本节约,并支持在云、本地或混合环境中灵活部署。其 S3 兼容的 API 确保了与现有数据栈和 AI 工作流的无缝集成。
Irisradgroup
Irisradgroup 是一款由人工智能驱动的基础设施技术解决方案,可自动执行道路及路边资产维护。它使用专用摄像头和智能仪表板,帮助市政当局和基础设施管理人员高效监控路况、盘点资产、确保合规并改善公共安全。
Irisradgroup 是一款由人工智能驱动的基础设施技术解决方案,可自动执行道路及路边资产维护。它使用专用摄像头和智能仪表板,帮助市政当局和基础设施管理人员高效监控路况、盘点资产、确保合规并改善公共安全。
Hewlett Packard Enterprise (HPE)
慧与(Hewlett Packard Enterprise, HPE)是一家全球性的边缘到云公司,为企业提供全面的人工智能、混合云、网络和数据解决方案。通过其HPE GreenLake平台、与NVIDIA等行业领导者的战略合作以及强大的硬件和服务组合,HPE助力企业加速创新、优化运营,并将数据转化为可行的洞察。
慧与(Hewlett Packard Enterprise, HPE)是一家全球性的边缘到云公司,为企业提供全面的人工智能、混合云、网络和数据解决方案。通过其HPE GreenLake平台、与NVIDIA等行业领导者的战略合作以及强大的硬件和服务组合,HPE助力企业加速创新、优化运营,并将数据转化为可行的洞察。

HIVE Digital Technologies
HIVE Digital Technologies 是可持续数据中心基础设施领域的全球领导者,专注于大规模比特币挖矿和为人工智能应用提供高性能计算(HPC)。HIVE 利用其 NVIDIA GPU 集群,通过其位于加拿大、瑞典和巴拉圭的地理多元化数据中心,以高效的绿色能源为变革性技术提供动力。
HIVE Digital Technologies 是可持续数据中心基础设施领域的全球领导者,专注于大规模比特币挖矿和为人工智能应用提供高性能计算(HPC)。HIVE 利用其 NVIDIA GPU 集群,通过其位于加拿大、瑞典和巴拉圭的地理多元化数据中心,以高效的绿色能源为变革性技术提供动力。
Exa Laboratories
Exa Laboratories(现为 Zettascale)是一家由 YC 支持的硅谷初创公司,致力于为人工智能开发最先进、高能效的可重构芯片(XPU)。其多态计算架构旨在通过提供比传统 GPU 和 TPU 更卓越的性能、通用性和效率,解决人工智能训练和推理中的能源危机问题。
Exa Laboratories(现为 Zettascale)是一家由 YC 支持的硅谷初创公司,致力于为人工智能开发最先进、高能效的可重构芯片(XPU)。其多态计算架构旨在通过提供比传统 GPU 和 TPU 更卓越的性能、通用性和效率,解决人工智能训练和推理中的能源危机问题。

Prediction Guard
Prediction Guard 是一个企业级 AI 平台,允许组织在自己的防火墙后安全地部署、管理和扩展大型语言模型 (LLM)。它提供灵活的部署选项,包括本地、物理隔离和私有云,确保完全的数据隐私和控制。凭借其与 OpenAI 兼容的 API,它可以与 LangChain 和 LlamaIndex 等现有工具和框架无缝集成,是医疗、国防和金融等受监管行业的理想选择。
Prediction Guard 是一个企业级 AI 平台,允许组织在自己的防火墙后安全地部署、管理和扩展大型语言模型 (LLM)。它提供灵活的部署选项,包括本地、物理隔离和私有云,确保完全的数据隐私和控制。凭借其与 OpenAI 兼容的 API,它可以与 LangChain 和 LlamaIndex 等现有工具和框架无缝集成,是医疗、国防和金融等受监管行业的理想选择。
Protocol Labs
Protocol Labs 是一家专注于网络协议的研究、开发和部署实验室。它致力于推动计算领域的突破,聚焦于 Web3、人工智能和去中心化基础设施。作为 IPFS 和 Filecoin 等基础技术的创建者,它构建了一个由 600 多家初创公司和组织组成的全球创新网络,旨在建设一个更具韧性和开放性的互联网。
Protocol Labs 是一家专注于网络协议的研究、开发和部署实验室。它致力于推动计算领域的突破,聚焦于 Web3、人工智能和去中心化基础设施。作为 IPFS 和 Filecoin 等基础技术的创建者,它构建了一个由 600 多家初创公司和组织组成的全球创新网络,旨在建设一个更具韧性和开放性的互联网。

StackSpaces
StackSpaces 是一个集成开发平台,旨在帮助开发人员轻松构建、部署和扩展全栈 AI 应用程序。它提供了一个包含后端、前端和基础设施组件的统一环境,简化了从创意到生产的整个开发生命周期。
StackSpaces 是一个集成开发平台,旨在帮助开发人员轻松构建、部署和扩展全栈 AI 应用程序。它提供了一个包含后端、前端和基础设施组件的统一环境,简化了从创意到生产的整个开发生命周期。
ClawCloud Run
ClawCloud Run 是一个旨在简化应用程序生命周期的云原生开发平台。它使开发人员能够在一个统一的云环境中构建、部署、管理和运行应用程序,而无需编写复杂的 YAML 文件。该平台具有可视化画布、一键式模板和集成的数据库管理功能,可加快产品上市进程。
ClawCloud Run 是一个旨在简化应用程序生命周期的云原生开发平台。它使开发人员能够在一个统一的云环境中构建、部署、管理和运行应用程序,而无需编写复杂的 YAML 文件。该平台具有可视化画布、一键式模板和集成的数据库管理功能,可加快产品上市进程。
DistributeAI
DistributeAI 是一个去中心化的 AI 超级计算机平台,为开发者提供可扩展、低成本的开源 AI 模型库访问。它通过开发者友好的 API 和 SDK 实现 AI 应用的构建与部署,同时允许用户通过贡献闲置算力来获利。
DistributeAI 是一个去中心化的 AI 超级计算机平台,为开发者提供可扩展、低成本的开源 AI 模型库访问。它通过开发者友好的 API 和 SDK 实现 AI 应用的构建与部署,同时允许用户通过贡献闲置算力来获利。
Fastly
Fastly 是一个领先的边缘云平台,旨在构建、保护和交付快速、可扩展的数字体验。它结合了现代化的 CDN、强大的安全功能(如新一代 WAF)以及功能强大的无服务器计算环境。Fastly 帮助企业提升性能、增强安全性,并在更靠近用户的位置进行创新,为电子商务、流媒体和 AI 驱动的应用提供特定解决方案。
Fastly 是一个领先的边缘云平台,旨在构建、保护和交付快速、可扩展的数字体验。它结合了现代化的 CDN、强大的安全功能(如新一代 WAF)以及功能强大的无服务器计算环境。Fastly 帮助企业提升性能、增强安全性,并在更靠近用户的位置进行创新,为电子商务、流媒体和 AI 驱动的应用提供特定解决方案。

Currux Vision
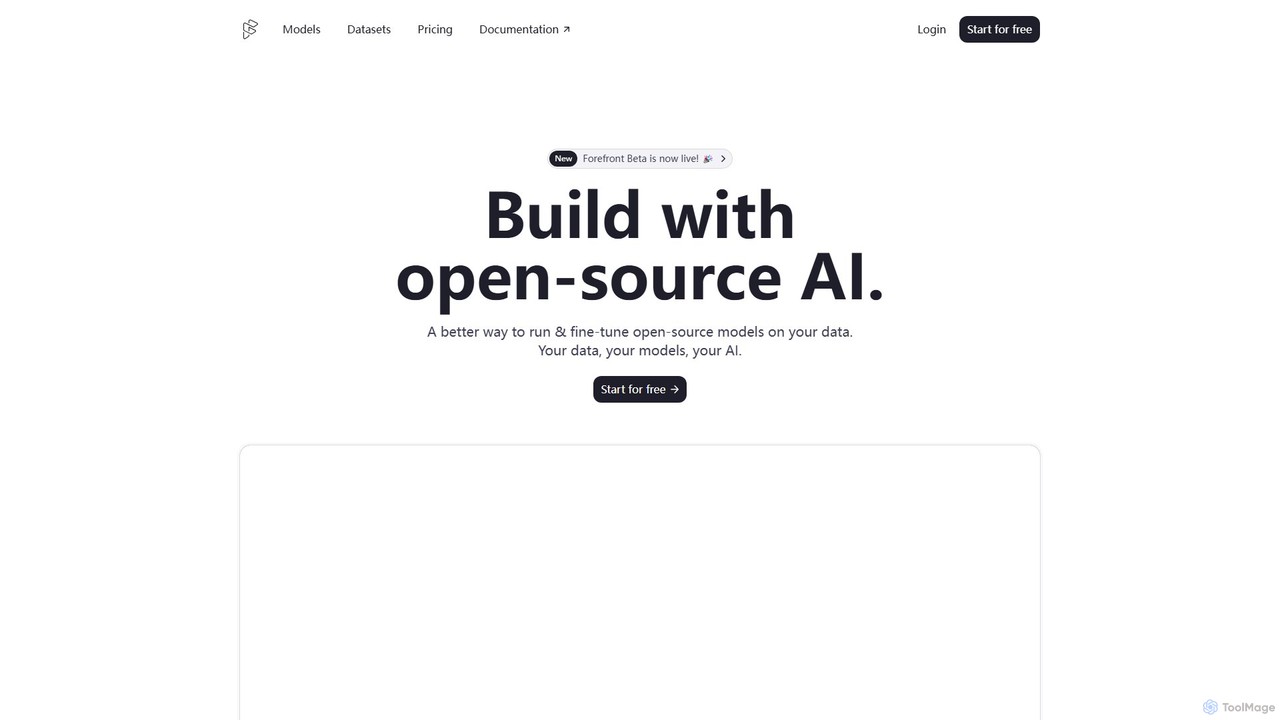
Currux Vision为智能基础设施提供自主AI系统,专注于智能交通系统(ITS)。它利用现有的闭路电视摄像头进行实时交通监控、违章检测和数据分析。该平台通过先进的计算机视觉和边缘计算,帮助城市和政府机构改善交通流量、增强安全性并优化基础设施管理。
Currux Vision为智能基础设施提供自主AI系统,专注于智能交通系统(ITS)。它利用现有的闭路电视摄像头进行实时交通监控、违章检测和数据分析。该平台通过先进的计算机视觉和边缘计算,帮助城市和政府机构改善交通流量、增强安全性并优化基础设施管理。
Permit.io
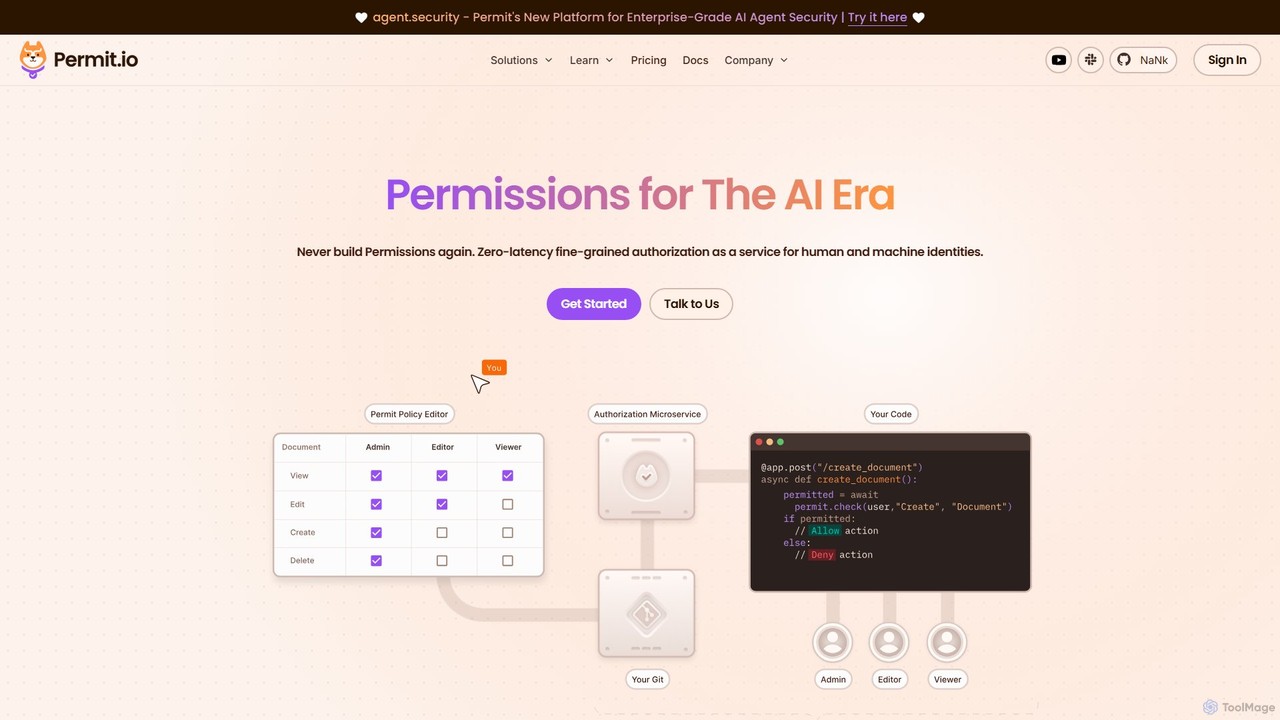
Permit.io 是一个专为 AI 时代设计的全栈授权平台。它为开发人员简化了 RBAC、ABAC 和 ReBAC 等复杂访问控制的实施。通过无代码策略编辑器、GitOps 集成和可嵌入的 UI 组件,它允许整个团队安全高效地管理权限。该平台通过混合模型运行,确保低延迟决策,同时将敏感数据保留在您的网络内,为包括 AI 代理驱动的现代应用提供强大的合规性和可扩展性。
Permit.io 是一个专为 AI 时代设计的全栈授权平台。它为开发人员简化了 RBAC、ABAC 和 ReBAC 等复杂访问控制的实施。通过无代码策略编辑器、GitOps 集成和可嵌入的 UI 组件,它允许整个团队安全高效地管理权限。该平台通过混合模型运行,确保低延迟决策,同时将敏感数据保留在您的网络内,为包括 AI 代理驱动的现代应用提供强大的合规性和可扩展性。
Tensorfuse
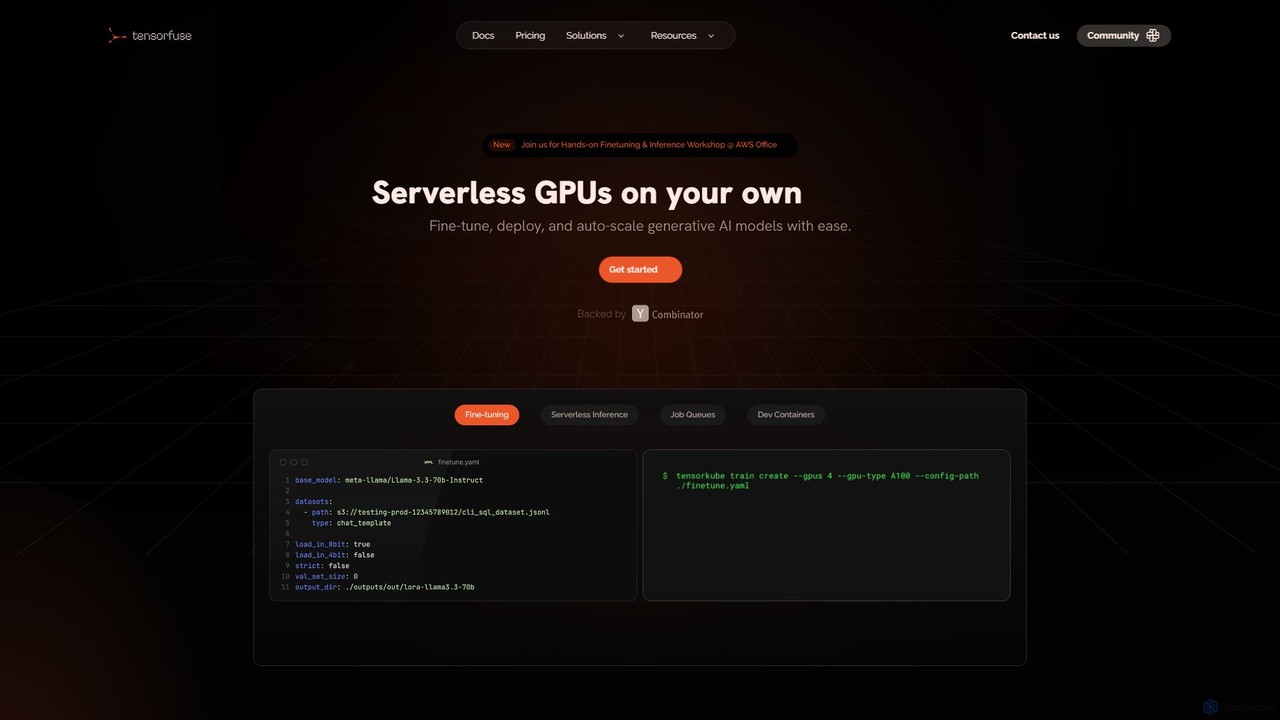
Tensorfuse 是一个无服务器 GPU 平台,允许开发者在自己的 AWS 云上微调、部署和自动扩展生成式 AI 模型。它简化了基础设施管理,提供无服务器推理、作业队列和开发容器等功能,以加速开发、降低成本并消除 DevOps 开销。
Tensorfuse 是一个无服务器 GPU 平台,允许开发者在自己的 AWS 云上微调、部署和自动扩展生成式 AI 模型。它简化了基础设施管理,提供无服务器推理、作业队列和开发容器等功能,以加速开发、降低成本并消除 DevOps 开销。

Cortex Labs
Cortex Labs 是一个去中心化的开源公共区块链,旨在直接在链上运行 AI 模型和 AI 驱动的 dApp。它以实现高效 AI 推理的 Cortex 虚拟机(CVM)和用于可扩展性的 ZkRollup Layer 2 解决方案 ZkMatrix 为特色。其目标是通过创建一个开发者可以构建、共享和商业化智能合约中 …
Cortex Labs 是一个去中心化的开源公共区块链,旨在直接在链上运行 AI 模型和 AI 驱动的 dApp。它以实现高效 AI 推理的 Cortex 虚拟机(CVM)和用于可扩展性的 ZkRollup Layer 2 解决方案 ZkMatrix 为特色。其目标是通过创建一个开发者可以构建、共享和商业化智能合约中 AI 模型的生态系统,来实现 AI 的民主化。


PowerSpect
PowerSpect 是一个由人工智能驱动的平台,旨在简化和自动化基础设施巡检。它利用先进的计算机视觉、3D建模和预测性分析技术,分析图像和传感器数据。该平台专为能源和公用事业等行业设计,帮助检测潜在问题、预测维护需求,并确保输电塔等关键资产的安全性和可靠性。
PowerSpect 是一个由人工智能驱动的平台,旨在简化和自动化基础设施巡检。它利用先进的计算机视觉、3D建模和预测性分析技术,分析图像和传感器数据。该平台专为能源和公用事业等行业设计,帮助检测潜在问题、预测维护需求,并确保输电塔等关键资产的安全性和可靠性。
DigitalOcean
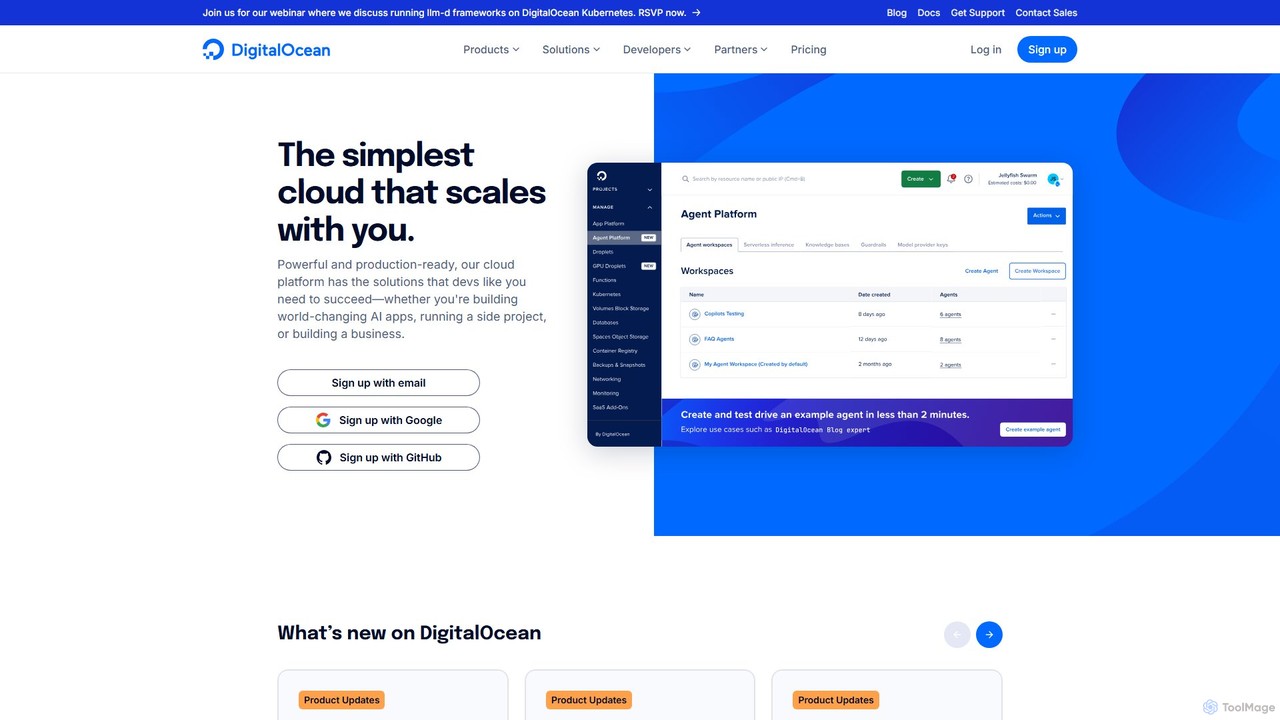
DigitalOcean 是一个专注于开发者的云基础设施平台,可简化应用程序的构建、部署和扩展。它提供一整套产品,包括虚拟机(Droplets)、托管 Kubernetes 和 GradientAI 平台,为创建和托管足以改变世界的人工智能应用(从个人项目到大型企业)提供强大的 GPU 资源和工具。
DigitalOcean 是一个专注于开发者的云基础设施平台,可简化应用程序的构建、部署和扩展。它提供一整套产品,包括虚拟机(Droplets)、托管 Kubernetes 和 GradientAI 平台,为创建和托管足以改变世界的人工智能应用(从个人项目到大型企业)提供强大的 GPU 资源和工具。
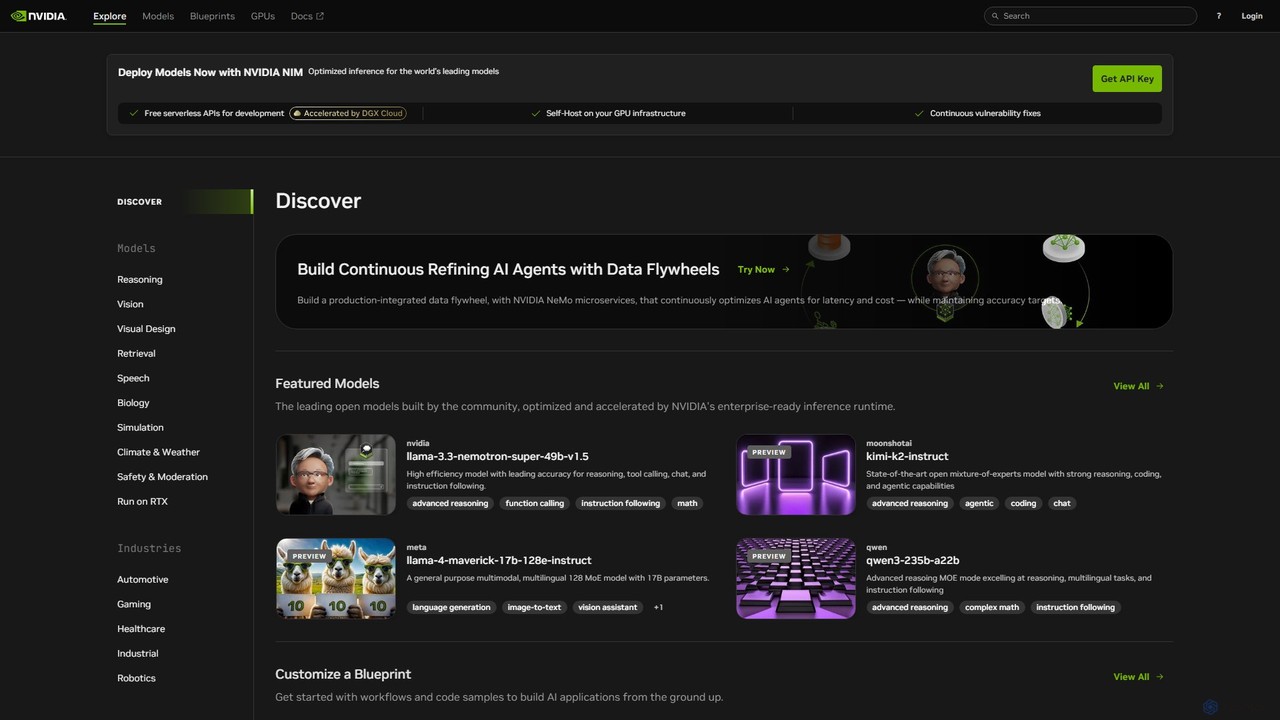
NVIDIA Build
NVIDIA Build 是一个面向开发者和企业的综合性平台,用于发现、定制和部署生产级的生成式AI模型。它提供庞大的优化模型目录、用于高性能推理的NVIDIA NIM微服务以及加速开发的应用蓝图。
NVIDIA Build 是一个面向开发者和企业的综合性平台,用于发现、定制和部署生产级的生成式AI模型。它提供庞大的优化模型目录、用于高性能推理的NVIDIA NIM微服务以及加速开发的应用蓝图。


thundercompute
Thunder Compute 是一个超低成本的GPU云平台,专为AI和机器学习开发者设计。它提供NVIDIA A100和T4等按需GPU实例,价格比主流云服务商低80%。凭借一键设置、VS Code集成和无缝扩展等功能,它极大地简化了从原型设计到生产的开发工作流程,让开发者能专注于构建模型,而非管理基础设施。
Thunder Compute 是一个超低成本的GPU云平台,专为AI和机器学习开发者设计。它提供NVIDIA A100和T4等按需GPU实例,价格比主流云服务商低80%。凭借一键设置、VS Code集成和无缝扩展等功能,它极大地简化了从原型设计到生产的开发工作流程,让开发者能专注于构建模型,而非管理基础设施。

Inferless
Inferless 是一个无服务器 GPU 平台,专为开发人员设计,可在数分钟内完成机器学习模型的部署。它无需管理基础设施,提供从零开始的自动扩展功能以应对突发性工作负载。该平台针对闪电般的冷启动和成本效益进行了优化,允许用户按使用量付费,最多可节省 90% 的 GPU 费用。
Inferless 是一个无服务器 GPU 平台,专为开发人员设计,可在数分钟内完成机器学习模型的部署。它无需管理基础设施,提供从零开始的自动扩展功能以应对突发性工作负载。该平台针对闪电般的冷启动和成本效益进行了优化,允许用户按使用量付费,最多可节省 90% 的 GPU 费用。

massedcompute
Massed Compute 是一个云平台,提供按需、高性能的 NVIDIA GPU 和 CPU。它为人工智能开发、机器学习和大数据分析提供灵活、可扩展且经济实惠的计算能力,无需长期合同,专为创新者和开发者设计。
Massed Compute 是一个云平台,提供按需、高性能的 NVIDIA GPU 和 CPU。它为人工智能开发、机器学习和大数据分析提供灵活、可扩展且经济实惠的计算能力,无需长期合同,专为创新者和开发者设计。

Predibase
Predibase 是一个端到端的开发者平台,用于高效地微调和服务开源大型语言模型(LLM)。它使用户能够构建自定义的 AI 模型,在特定任务上超越像 GPT-4 这样的大型专有模型,同时显著降低成本和推理延迟。该平台采用强化学习微调(RFT)和 LoRAX 等先进技术,实现高速、多模型的服务。
Predibase 是一个端到端的开发者平台,用于高效地微调和服务开源大型语言模型(LLM)。它使用户能够构建自定义的 AI 模型,在特定任务上超越像 GPT-4 这样的大型专有模型,同时显著降低成本和推理延迟。该平台采用强化学习微调(RFT)和 LoRAX 等先进技术,实现高速、多模型的服务。

Heurist AI
Heurist AI 是一个专为链上经济设计的全栈、去中心化人工智能基础设施。它为开发者提供统一的API以访问众多AI模型,并提供一个框架来构建可组合的AI代理。通过利用去中心化物理基础设施网络(DePIN),Heurist 连接了GPU提供商和AI开发者,旨在普及AI计算的访问权限并促进Web3领域的创新。
Heurist AI 是一个专为链上经济设计的全栈、去中心化人工智能基础设施。它为开发者提供统一的API以访问众多AI模型,并提供一个框架来构建可组合的AI代理。通过利用去中心化物理基础设施网络(DePIN),Heurist 连接了GPU提供商和AI开发者,旨在普及AI计算的访问权限并促进Web3领域的创新。

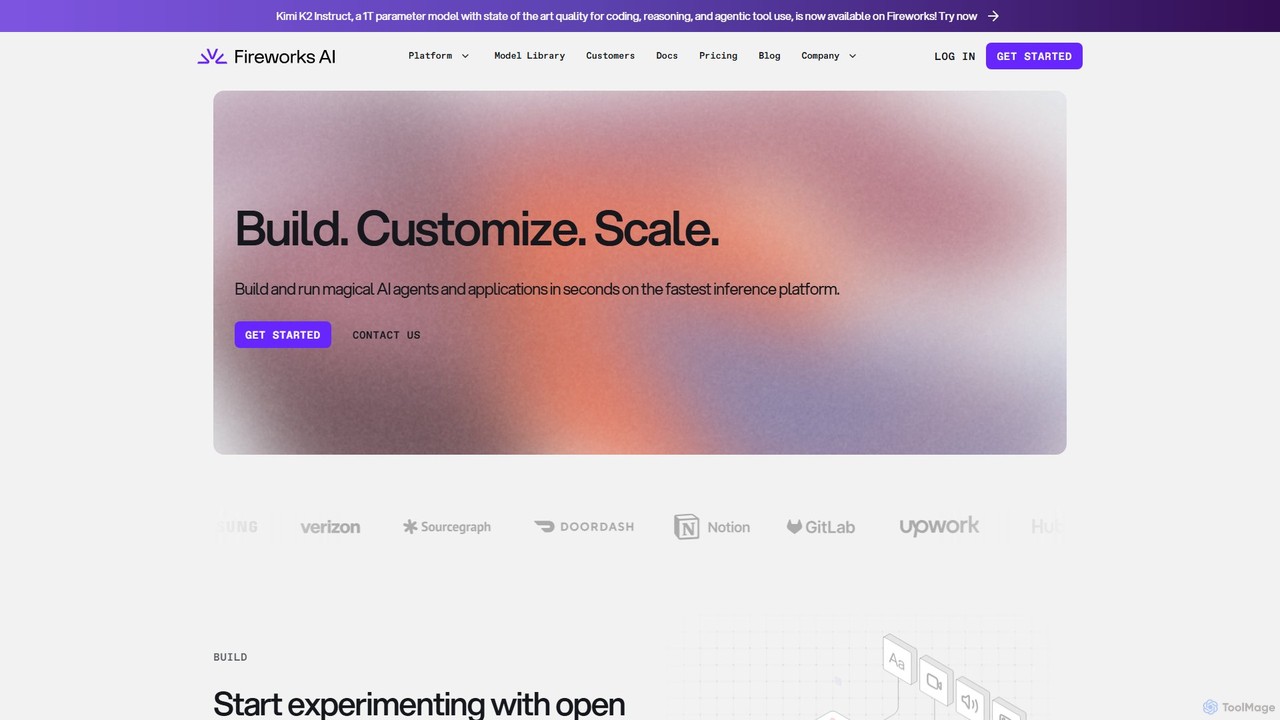
Fireworks AI
一个为开发者设计的高性能平台,用于构建、定制和扩展生成式AI应用。它提供业界领先的快速推理引擎、先进的微调功能以及对广泛开源模型的访问,从而实现实时、高性价比的AI解决方案。
一个为开发者设计的高性能平台,用于构建、定制和扩展生成式AI应用。它提供业界领先的快速推理引擎、先进的微调功能以及对广泛开源模型的访问,从而实现实时、高性价比的AI解决方案。
HyperAI
HyperAI 是一个位于欧洲的超本地化 GPU 云平台,旨在普及企业级 AI 计算。它通过灵活的计划(包括即用实例和专用服务器)提供高性能的 NVIDIA A100 和 H100 GPU。HyperAI 专注于低延迟、数据合规性和开发者友好的环境,并预装了 Nvidia AI SDK,助力开发者和企业高效、安全地构建、训练和部署复杂的 AI 模型。
HyperAI 是一个位于欧洲的超本地化 GPU 云平台,旨在普及企业级 AI 计算。它通过灵活的计划(包括即用实例和专用服务器)提供高性能的 NVIDIA A100 和 H100 GPU。HyperAI 专注于低延迟、数据合规性和开发者友好的环境,并预装了 Nvidia AI SDK,助力开发者和企业高效、安全地构建、训练和部署复杂的 AI 模型。
ClearML GenAI App Engine
一个企业级平台,用于快速部署、管理和扩展生成式AI应用。它提供统一的基础设施控制平面,以简化LLM部署、监控性能并优化计算成本,从而安全高效地加速生成式AI的采用。
一个企业级平台,用于快速部署、管理和扩展生成式AI应用。它提供统一的基础设施控制平面,以简化LLM部署、监控性能并优化计算成本,从而安全高效地加速生成式AI的采用。
Google Cloud
Google Cloud 是一套全面的云计算服务,提供基础设施、平台和无服务器环境。它在人工智能/机器学习(Vertex AI 和 Gemini)和数据分析(BigQuery)方面表现卓越,并为从初创公司到全球性企业的各种规模的企业提供可扩展、安全的基础设施。
Google Cloud 是一套全面的云计算服务,提供基础设施、平台和无服务器环境。它在人工智能/机器学习(Vertex AI 和 Gemini)和数据分析(BigQuery)方面表现卓越,并为从初创公司到全球性企业的各种规模的企业提供可扩展、安全的基础设施。
Cirrascale Cloud Services
Cirrascale 提供专为大规模人工智能、深度学习和高性能计算(HPC)量身定制的高性能专用 GPU 云服务。它提供对最新 NVIDIA GPU 硬件和可扩展基础设施的访问,使企业能够高效地训练大型模型并运行复杂的计算工作负载。
Cirrascale 提供专为大规模人工智能、深度学习和高性能计算(HPC)量身定制的高性能专用 GPU 云服务。它提供对最新 NVIDIA GPU 硬件和可扩展基础设施的访问,使企业能够高效地训练大型模型并运行复杂的计算工作负载。
Clore.ai
Clore.ai 是一个去中心化 GPU 市场,提供对全球高性能计算资源的按需访问。它将需要 GPU 算力进行 AI 训练、3D 渲染和科学模拟的用户与希望将闲置服务器变现的硬件所有者连接起来。该平台拥有灵活的租赁市场、用于交易的自有加密货币 (CLORE) 以及独特的持币证明 (POH) 系统,以提供更高的奖励和折扣,为高性能计算创建了一个全面的生态系统。
Clore.ai 是一个去中心化 GPU 市场,提供对全球高性能计算资源的按需访问。它将需要 GPU 算力进行 AI 训练、3D 渲染和科学模拟的用户与希望将闲置服务器变现的硬件所有者连接起来。该平台拥有灵活的租赁市场、用于交易的自有加密货币 (CLORE) 以及独特的持币证明 (POH) 系统,以提供更高的奖励和折扣,为高性能计算创建了一个全面的生态系统。

Juice
Juice 是一个纯软件平台,可实现 GPU-over-IP(IP网络上的GPU),允许您通过任何标准网络访问、共享和池化 GPU 资源。它将 GPU 与物理机器解耦,按需将任何 CPU 节点转变为 GPU 加速系统,从而在无需更改代码的情况下优化利用率并显著降低 AI 和图形工作负载的成本。
Juice 是一个纯软件平台,可实现 GPU-over-IP(IP网络上的GPU),允许您通过任何标准网络访问、共享和池化 GPU 资源。它将 GPU 与物理机器解耦,按需将任何 CPU 节点转变为 GPU 加速系统,从而在无需更改代码的情况下优化利用率并显著降低 AI 和图形工作负载的成本。
Not Diamond
Not Diamond 是一款面向开发者的智能多模型基础设施。它利用预测性模型路由和自动提示词适配功能,通过为任何给定任务动态选择最佳的大语言模型(LLM),帮助团队加速开发、提高AI准确性并优化成本。
Not Diamond 是一款面向开发者的智能多模型基础设施。它利用预测性模型路由和自动提示词适配功能,通过为任何给定任务动态选择最佳的大语言模型(LLM),帮助团队加速开发、提高AI准确性并优化成本。
关于 基础设施
AI 基础设施是构建、训练和部署人工智能模型所需的基础平台、服务和硬件。这些工具提供可扩展的计算资源(如 GPU 和 TPU),以及用于管理整个机器学习生命周期的专用软件。对于需要处理大规模数据集和复杂计算的开发者与组织而言,它们至关重要,能够支持大规模定制化 AI 解决方案的创建。这种基础设施抽象了管理硬件的复杂性,使团队能专注于模型开发和创新。
核心功能
- 可扩展计算资源:按需访问强大的 GPU 和 TPU,以加速模型训练和推理。
- 模型部署与托管:用于将模型部署到生产环境的托管服务和 API,具备自动扩展和监控功能。
- MLOps 平台:用于自动化和管理端到端机器学习生命周期的集成工具链,涵盖从数据准备到部署的全过程。
- 优化数据存储:专为 AI 训练中使用的大规模数据集设计的高性能存储解决方案。
- 开发环境:预先配置好 AI 开发所需框架和库的开发环境。
适用场景
AI 基础设施对于构建专有 AI 能力的科技公司、研究机构和企业至关重要。它被用于训练大型语言模型 (LLM)、开发用于工业自动化的计算机视觉系统,以及为电商平台部署实时推荐引擎。数据科学团队依靠它来管理复杂的实验跟踪和模型版本控制。
选择要点
选择 AI 基础设施时,应考虑具体的计算需求,如所需 GPU 的类型和数量。评估平台的可扩展性及其处理工作负载波动的能力。考量其 MLOps 工具的全面性,以确保工作流程的顺畅。最后,分析其定价模式——按需付费、预留实例或无服务器模式——以匹配您的预算和使用模式。
精选工具排行榜
最受欢迎
按月度最高流量排序
互动性最强
按最低跳出率排序
用户粘性最高
按平均访问时长排序
基础设施应用场景
训练定制化大型语言模型
一个研究实验室或 AI 初创公司需要基于其专有数据集训练一个大型语言模型 (LLM)。他们使用 AI 基础设施提供商来访问一个由数百个高性能 GPU 组成的集群。这使他们能够高效地进行分布式训练,将训练时间从数月缩短至数周。平台预配置的环境和数据存储解决方案简化了设置过程,让研究人员能专注于模型架构和实验,而非硬件管理。
部署实时推理 API
一家电子商务公司希望部署一个用于实时产品推荐的机器学习模型。他们使用 AI 基础设施提供商的托管式模型托管服务。该服务提供了一个可扩展的 API 端点,能在促销活动期间自动处理流量高峰。内置的监控工具让其运维团队能够跟踪延迟和错误率,确保流畅的用户体验。通过使用托管服务,该公司避免了自行搭建和维护服务基础设施的复杂性。
管理端到端的 MLOps 工作流
一个企业数据科学团队管理着数十个生产环境中的模型。他们采用了一个 MLOps 平台来简化整个工作流程。该平台提供了数据版本控制、实验跟踪和模型注册等工具,为每个模型创建了可复现和可审计的记录。他们的 CI/CD 管道与该平台集成,自动化了测试、验证和部署新模型版本的流程,从而显著减少了人为错误,并加快了新 AI 功能的上市时间。
通过 API 微调基础模型
一位开发者正在为法律行业构建一个专业的聊天机器人。他们没有从头开始训练模型,而是使用来自基础设施提供商的无服务器 API 来微调一个大型基础模型。他们将一个经过整理的小型法律问答数据集上传到该服务。平台在其托管的基础设施上处理整个微调过程。完成后,开发者会获得一个用于其定制模型的私有 API 端点,从而可以轻松地将其集成到应用程序中,而无需管理任何服务器。
构建可扩展的数据处理管道
一家计算机视觉公司需要处理数百万张图像以备模型训练。他们使用 AI 基础设施提供商的云存储和数据处理服务。他们构建了一个自动化管道,每当新图像上传时,就会触发调整大小和归一化等处理作业。这种无服务器方法使他们能够并行处理海量数据,而无需预配或管理服务器,确保其数据集随时可用于下一次训练运行。
在安全环境中进行协作式 AI 开发
一家金融服务公司正在使用敏感的客户数据开发欺诈检测模型。他们需要一个安全且协作的环境。他们使用一个专业的 AI 平台,该平台提供具有严格访问控制的隔离开发环境(笔记本)。数据科学家可以在不暴露原始数据的情况下协作进行模型开发。该平台内置的安全功能和合规认证确保所有开发活动都遵守行业法规,从而在保护数据隐私的同时实现创新。