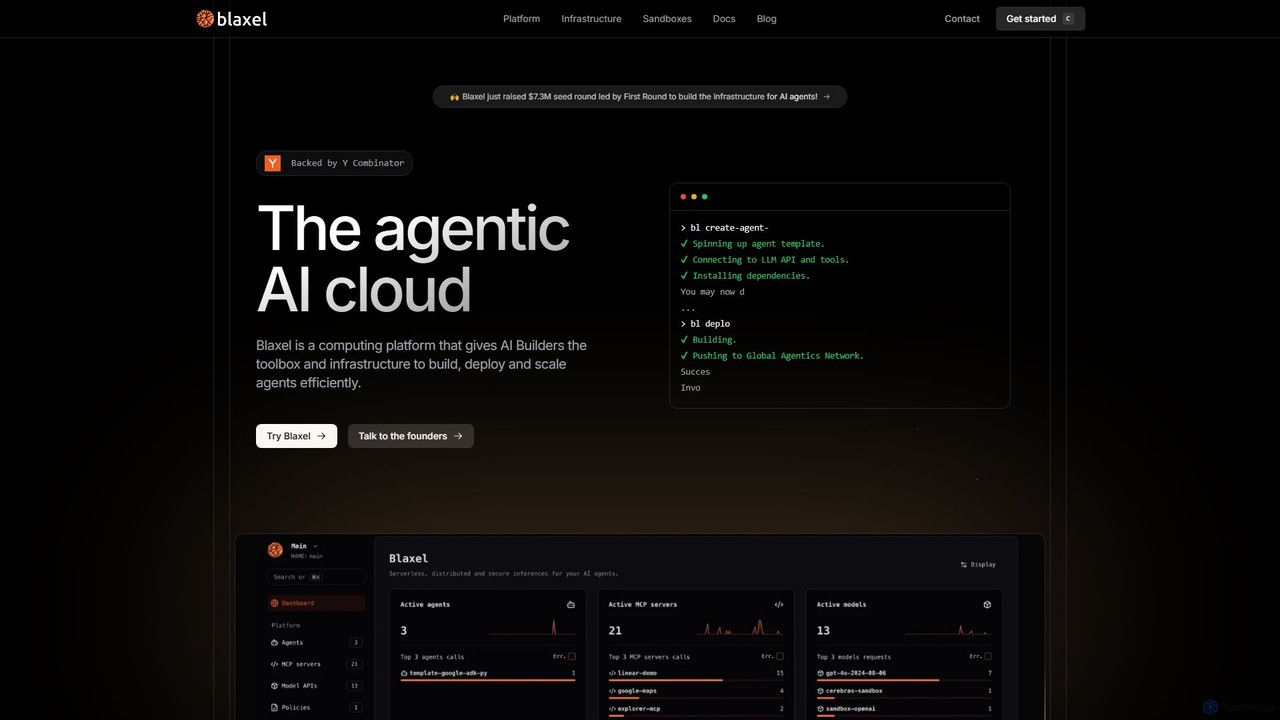
Blaxel
Blaxel is a serverless computing platform designed for AI developers, providing the infrastructure and tools to build, deploy, …
Blaxel is a serverless computing platform designed for AI developers, providing the infrastructure and tools to build, deploy, and scale agentic AI applications efficiently. It offers sandboxed VMs, a unified LLM gateway, and deep observability.
About Cloud Computing
Cloud Computing platforms provide on-demand access to scalable computing resources essential for developing and deploying AI applications. These platforms offer virtualized hardware, such as powerful GPUs and TPUs, alongside vast storage and networking capabilities, eliminating the need for significant upfront investment in physical infrastructure. This allows teams to train complex models, process massive datasets, and host AI services with high availability and flexibility. The pay-as-you-go model makes cutting-edge AI development accessible to everyone from individual researchers to large enterprises.
Core Features
- GPU/TPU Acceleration: Provides access to specialized processors designed to accelerate machine learning model training and inference tasks.
- Scalable Data Storage: Offers object storage solutions (like Amazon S3 or Google Cloud Storage) capable of holding petabytes of data for training datasets.
- Managed AI/ML Platforms: Delivers integrated environments (e.g., SageMaker, Azure ML) that streamline the entire machine learning lifecycle, from data preparation to model deployment.
- Serverless Computing: Enables the deployment of AI models as endpoints that automatically scale based on demand, optimizing cost and performance for inference.
- High-Performance Computing (HPC): Offers clusters of interconnected computers to run large-scale simulations and complex computational tasks required for advanced AI research.
Use Cases
Cloud Computing is fundamental for data scientists, machine learning engineers, and AI-focused startups. It is used for training large language models (LLMs) that require immense computational power, deploying real-time computer vision APIs for applications like autonomous driving, and running big data analytics pipelines to extract insights for model building.
How to Choose
When selecting a Cloud Computing provider for AI, consider the availability and performance of specific GPU/TPU models. Evaluate the maturity and feature set of their managed AI/ML platforms. Analyze the pricing models for both long-running training jobs and sporadic inference workloads. Also, assess data security, compliance certifications, and integration with existing MLOps tools.
Cloud ComputingUse Cases
Training a Large-Scale Deep Learning Model
A data science team at a tech company needs to train a new computer vision model on a dataset of over 10 million images. Using an on-premise server would take weeks. Instead, they utilize a cloud computing platform to spin up a cluster of 16 high-performance GPU instances. They use the platform's managed data storage to host the dataset and a pre-configured deep learning environment to manage dependencies. This parallel processing capability reduces the training time from weeks to just 48 hours, allowing for faster iteration and model improvement.
Deploying a Scalable AI Inference API
A startup has developed an AI-powered grammar correction tool and needs to serve it to thousands of concurrent users. Building and maintaining the infrastructure to handle fluctuating traffic is complex and expensive. They opt for a serverless computing service from a major cloud provider. They package their model into a container and deploy it as a serverless function. The platform automatically handles scaling, provisioning, and maintenance. This approach allows them to pay only for the compute time they actually use, significantly reducing operational costs and ensuring a responsive experience for all users, even during peak demand.
Running Big Data Processing for Feature Engineering
An ML engineer needs to process terabytes of raw user log data to create features for a recommendation engine. A single machine cannot handle this volume. The engineer uses a managed big data service on the cloud, like Apache Spark on EMR or Dataproc. They write a script to clean, transform, and aggregate the data, then run it on a dynamically provisioned cluster of dozens of machines. The cloud service handles the cluster management, and the job finishes in a few hours instead of days. The resulting feature set is then stored in cloud storage, ready for model training.
Building an End-to-End MLOps Pipeline
An enterprise AI team wants to automate their entire machine learning workflow to ensure reproducibility and speed up deployment. They use a managed AI platform from a cloud provider. This platform integrates tools for data versioning, experiment tracking, automated model training (AutoML), model registry, and CI/CD for deployment. An ML engineer defines the entire pipeline, from data ingestion to model monitoring in production. When new data is available, the pipeline automatically triggers, retrains the model, runs tests, and deploys the new version if it meets performance criteria, all within a unified cloud environment.
Fine-Tuning a Foundational Language Model
A legal tech startup wants to create a specialized AI assistant for contract analysis. Instead of building a large language model (LLM) from scratch, they decide to fine-tune a powerful open-source model on their proprietary dataset of legal documents. They use a cloud platform to rent a high-memory GPU instance (like an A100) for a few days. They upload their dataset to secure cloud storage and use a popular training framework to run the fine-tuning process. The cloud provides the necessary computational power on a temporary, cost-effective basis, enabling them to create a highly specialized and valuable AI asset without owning expensive hardware.
Hosting a Collaborative Data Science Environment
A distributed team of data scientists needs a centralized environment to collaborate on a project. Setting up individual local environments leads to version conflicts and inconsistencies. The team lead uses a cloud provider's managed notebook service (like Amazon SageMaker Studio or Google Vertex AI Workbench). This provides each team member with a cloud-based, containerized JupyterLab instance with shared access to datasets and code repositories. This ensures everyone is working with the same tools and data, streamlines collaboration, and allows the lead to easily monitor progress and manage resources without any infrastructure setup.