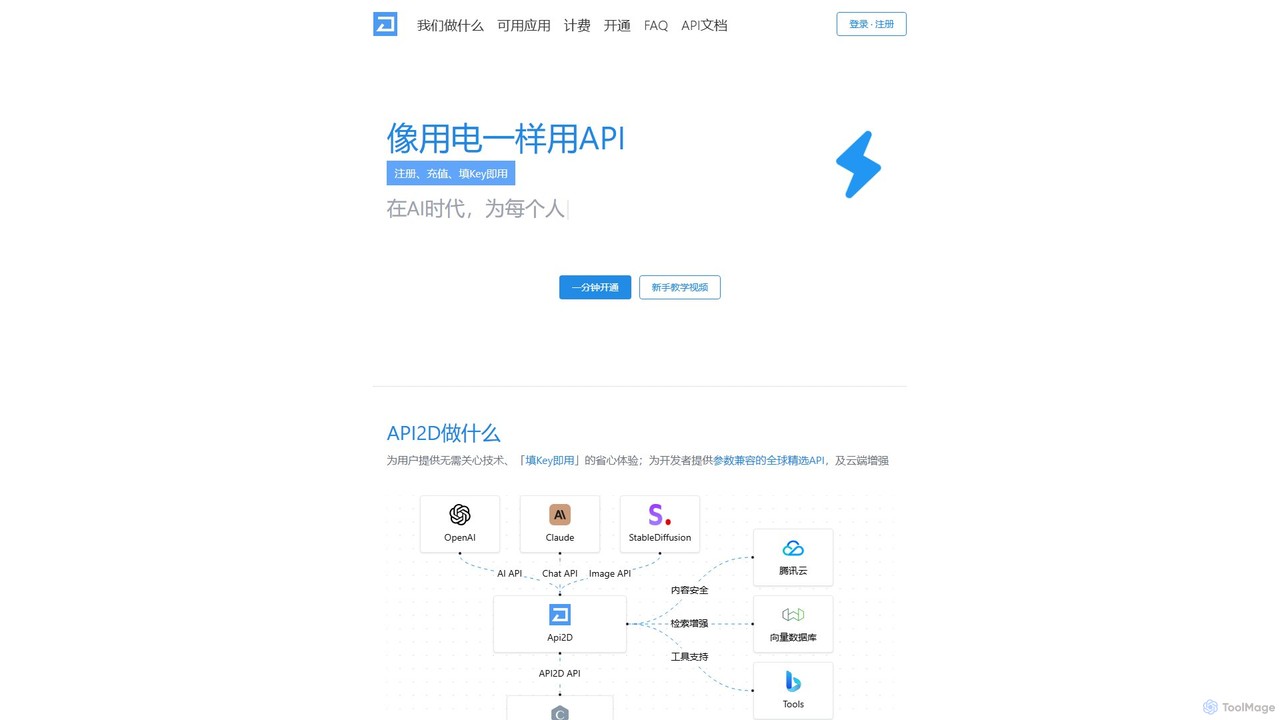
API2D
API2D is an API aggregator and proxy service that simplifies access to leading AI models like GPT-4, Claude, …
API2D is an API aggregator and proxy service that simplifies access to leading AI models like GPT-4, Claude, and Stable Diffusion. It provides a single, unified API key compatible with OpenAI standards, allowing for easy integration into hundreds of existing applications. With a pay-as-you-go pricing model and features like caching and content safety, API2D offers a convenient and cost-effective solution for developers and users to leverage powerful AI capabilities without complex setups or geographical restrictions.
About Middleware
AI Middleware is a software layer that connects and manages communication between different components of an AI application, such as models, data sources, and user interfaces. These tools provide a standardized infrastructure for deploying, scaling, and monitoring AI models, acting as the central nervous system for complex AI systems. By abstracting away low-level plumbing, middleware allows developers to build robust, production-grade AI services more efficiently. It is a critical component of the AI Infrastructure for ensuring interoperability and operational stability.
Core Features
- Model Serving & Deployment: Packages AI models into scalable, high-performance API endpoints.
- API Gateway & Management: Provides a unified entry point to manage traffic, security, authentication, and rate limiting for AI services.
- Workflow Orchestration: Defines and automates multi-step processes involving multiple models or data sources.
- Request & Response Transformation: Automatically converts data formats between applications and AI models.
- Observability & Monitoring: Tracks model performance, latency, error rates, and resource usage in real-time.
Use Cases
AI Middleware is primarily used by MLOps engineers, backend developers, and enterprise IT teams. It is essential for building production-grade systems like real-time fraud detection APIs, multi-modal AI assistants that combine language and vision models, and scalable recommendation engines for e-commerce platforms. It helps manage the complexity of microservice-based AI architectures.
How to Choose
When selecting AI Middleware, evaluate its scalability and performance under high load. Check for compatibility with your specific model frameworks (e.g., TensorFlow, PyTorch, ONNX). Assess its integration capabilities with your existing cloud infrastructure, databases, and CI/CD pipelines. Finally, consider the robustness of its monitoring, logging, and security features for maintaining production stability.
MiddlewareUse Cases
Deploying a Real-Time Fraud Detection API
A fintech company needs to deploy a machine learning model to detect fraudulent transactions in real-time. An MLOps engineer uses an AI Middleware tool to package the trained model into a secure, low-latency API endpoint. The middleware handles incoming transaction data, manages authentication, routes requests to horizontally scaled model instances for scoring, and returns a fraud probability score within milliseconds. This setup ensures high availability and can process thousands of transactions per second without manual intervention.
Orchestrating a Multi-Modal Content Analysis Pipeline
A media analysis firm wants to build a workflow to analyze video content. A developer uses AI middleware to orchestrate a multi-step pipeline. First, the middleware sends the video file to a speech-to-text model. It then routes the resulting transcript to a sentiment analysis model and a topic extraction model simultaneously. In parallel, it sends video frames to an object recognition model. Finally, the middleware aggregates all outputs into a single, structured JSON report. This automates a complex process that previously required significant manual coordination.
Managing Multiple LLM Providers via a Single Gateway
An enterprise wants to use multiple Large Language Models (LLMs) from different providers (e.g., OpenAI, Anthropic, Google) without locking into a single vendor. An IT architect implements an AI middleware solution as a unified API gateway. Application developers can now send requests to a single internal endpoint. The middleware then intelligently routes the request to the most cost-effective or best-performing LLM based on predefined rules. It also standardizes the API format, simplifying development and allowing the company to switch LLM providers seamlessly.
Scaling an E-commerce Recommendation Engine
An online retailer's recommendation engine experiences huge traffic spikes during holiday sales. To ensure stability, the operations team uses AI middleware to manage the model deployment. The middleware automatically scales the number of model instances up or down based on real-time traffic, ensuring low latency for users. It also provides load balancing to distribute requests evenly and implements caching for frequently requested recommendations, reducing the load on the core model and significantly cutting infrastructure costs while improving user experience.
Centralized Monitoring and Alerting for Deployed Models
An AIOps team is responsible for maintaining dozens of machine learning models in production. They use an AI middleware platform to gain a unified view of all models. The middleware's dashboard shows real-time metrics for each model, including request latency, error rates, and CPU/GPU utilization. The team sets up automated alerts that trigger if a model's latency exceeds a certain threshold or if its prediction accuracy starts to drift. This allows them to proactively identify and resolve issues before they impact end-users, ensuring high service reliability.
Enabling A/B Testing for Different Model Versions
A data science team has developed a new version of a customer churn prediction model and wants to compare its performance against the current one. Using AI middleware, they configure a traffic splitting rule. The middleware routes 90% of the incoming requests to the stable, existing model (A) and the remaining 10% to the new challenger model (B). It logs the predictions and outcomes for both versions separately. After a week, the team can analyze the logs to definitively determine if the new model provides a measurable improvement, allowing for data-driven decisions on model updates.