
The Foundry AI
The Foundry AI is a specialized platform for developers building AI web agents. It offers a deterministic web …
The Foundry AI is a specialized platform for developers building AI web agents. It offers a deterministic web simulator and an advanced annotation framework to test, benchmark, and debug agents in a reproducible environment, free from the unpredictability of the live web.
Coval
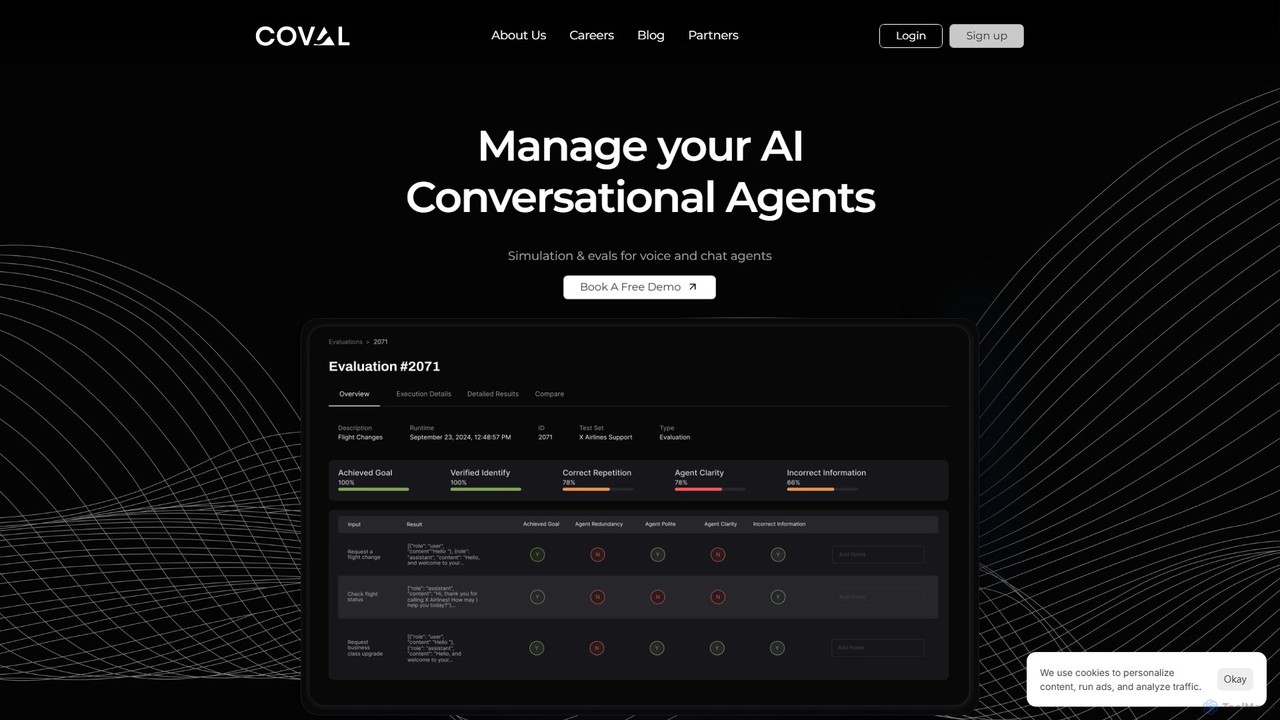
Coval is an advanced platform for simulating and evaluating AI conversational agents. Built by experts from Waymo, it …
Coval is an advanced platform for simulating and evaluating AI conversational agents. Built by experts from Waymo, it helps developers test voice and chat agents at scale, ensuring reliability and performance. It automates testing by simulating thousands of scenarios, provides in-depth performance metrics, and offers production monitoring to catch regressions and optimize agent behavior.
Atla AI
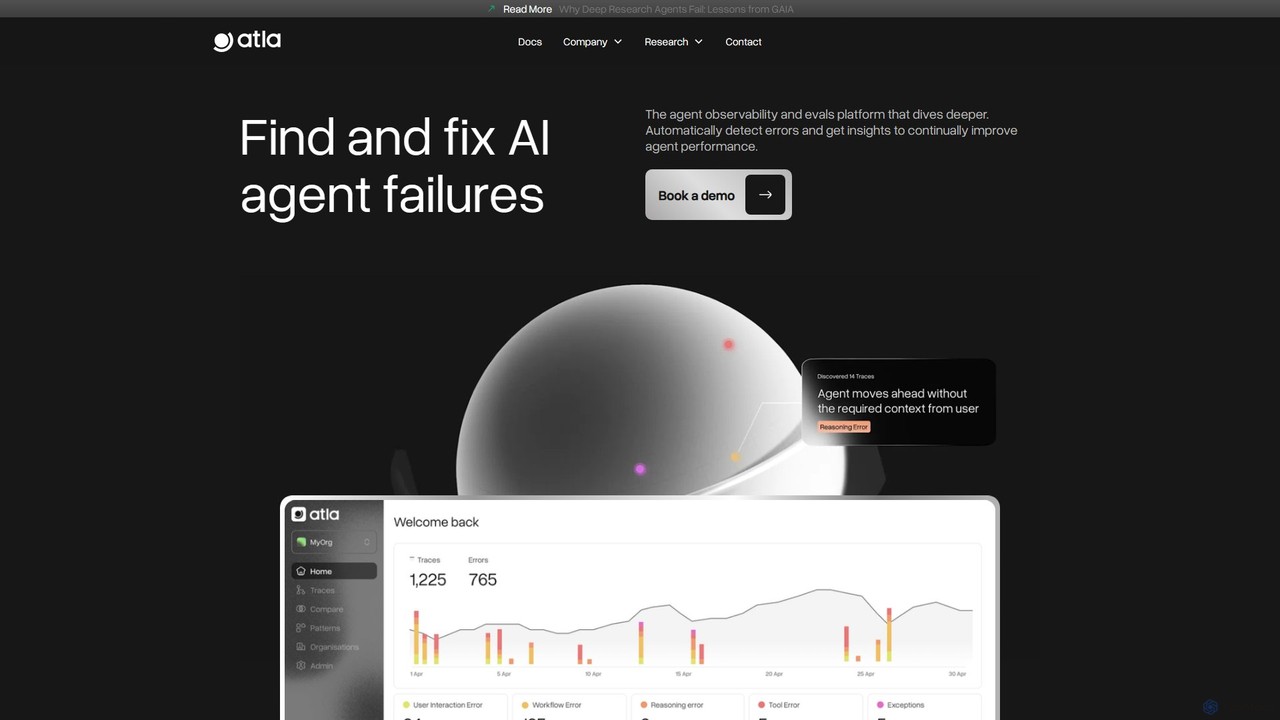
Atla AI is an observability and evaluation platform designed for AI agents. It helps developers find, understand, and …
Atla AI is an observability and evaluation platform designed for AI agents. It helps developers find, understand, and fix agent failures by providing deep insights into their behavior. The platform automatically detects errors, identifies recurring patterns, and offers actionable suggestions to continuously improve agent performance and completion rates.
About Model Evaluation
Model Evaluation tools are a specialized category of AI infrastructure designed to systematically assess the performance, fairness, and reliability of machine learning models. These platforms automate the process of calculating key metrics like accuracy, precision, and recall, while also providing advanced capabilities for bias detection, explainability analysis, and robustness testing. Their primary value lies in providing objective, data-driven insights that help developers select the best-performing model, ensure ethical AI practices, and validate model readiness for production environments. This rigorous assessment is a critical step in the MLOps lifecycle, ensuring that deployed models are effective, trustworthy, and aligned with business objectives.
Core Features
- Performance Metrics Tracking: Automatically calculates and visualizes standard metrics for classification (Accuracy, F1-Score, AUC) and regression (MSE, MAE, R²).
- Bias and Fairness Auditing: Identifies performance disparities across different demographic subgroups to detect and mitigate potential biases in model predictions.
- Explainability (XAI) Analysis: Generates insights into model decisions using techniques like SHAP and LIME, making black-box models more transparent.
- Robustness and Stress Testing: Evaluates model stability against adversarial attacks, data drift, and edge cases to ensure reliable real-world performance.
- Model Comparison and Versioning: Provides a framework to compare multiple models or different versions of the same model side-by-side on standardized datasets.
Use Cases
Model Evaluation tools are essential for data scientists, machine learning engineers, and MLOps teams, particularly in regulated industries such as finance, healthcare, and insurance. They are used during the development cycle to benchmark and select candidate models, in pre-deployment checks to validate compliance and fairness, and for periodic audits of live models to ensure continued performance and reliability.
How to Choose
When selecting a Model Evaluation tool, consider its compatibility with your machine learning frameworks (e.g., TensorFlow, PyTorch, Scikit-learn). Evaluate the breadth of its features—does it cover performance, fairness, and explainability? Assess its integration capabilities with your existing MLOps stack, such as experiment trackers and model registries. Finally, consider the quality of its visualization and reporting features for communicating results to both technical and non-technical stakeholders.
Model EvaluationUse Cases
Auditing Financial Models for Fairness
A data scientist at a financial institution is tasked with ensuring a new credit scoring model does not discriminate against protected demographic groups. Using a model evaluation tool, they upload the model's predictions on a test dataset. The tool automatically generates a fairness report, highlighting performance metrics like false positive rates across different genders and ethnicities. By analyzing these results, the scientist can identify and mitigate biases before the model is deployed, ensuring compliance with fair lending regulations and reducing reputational risk.
Comparing Computer Vision Model Architectures
A machine learning engineer is developing an image classification feature for a mobile app and needs to choose between three different model architectures (e.g., ResNet, MobileNet, Vision Transformer). They use a model evaluation platform to run all three models on the same validation dataset. The platform provides a side-by-side comparison dashboard showing accuracy, F1-score, inference latency, and model size for each. This comprehensive view allows the engineer to make a trade-off decision, selecting the model that offers the best balance of accuracy and on-device performance.
Generating Explanations for Medical Diagnoses
In a healthcare setting, a radiologist uses an AI model that detects anomalies in medical scans. To build trust and aid in diagnosis, an explainability (XAI) feature within a model evaluation tool is used. When the model flags a potential issue, the tool generates a heatmap (like a SHAP or LIME visualization) overlaying the original scan. This heatmap highlights the specific pixels and regions that most influenced the model's decision. This allows the radiologist to quickly verify the AI's reasoning against their own expertise, leading to more confident and transparent clinical decisions.
Stress-Testing Autonomous Vehicle Perception Models
An automotive engineering team needs to ensure the perception model in an autonomous vehicle is extremely reliable. They use a model evaluation tool's robustness testing module to simulate adverse conditions. This involves programmatically adding digital noise, fog, and rain to the test images, and running adversarial attacks to find the model's blind spots. The tool reports on how much the model's accuracy degrades under each condition. This rigorous stress-testing helps the team identify weaknesses and harden the model against real-world challenges, a critical step for ensuring safety.
Benchmarking NLP Models for Customer Support Chatbots
A product manager for an AI chatbot wants to upgrade its underlying Natural Language Processing (NLP) model. The team has shortlisted two new models. Using a model evaluation suite, they benchmark both models against the current one on a 'golden dataset' of historical customer conversations. The evaluation tool measures intent recognition accuracy, entity extraction F1-score, and response relevance. The results are displayed in a leaderboard format, allowing the product manager to clearly see which model performs best on their specific data and make an evidence-based decision for the upgrade.
Validating Model Behavior for Regulatory Compliance
A compliance officer at an insurance company needs to provide regulators with proof that their claims processing AI is fair and transparent. They use a model evaluation platform to run a comprehensive audit. The platform generates a detailed report that includes:
- Overall performance metrics (e.g., accuracy in fraud detection).
- Fairness analysis across age, gender, and location subgroups.
- Example-based explanations (XAI) for specific claim denial decisions.