People For AI
People For AI provides expert-driven data labeling services for machine learning projects. They specialize in high-quality, secure annotation …
People For AI provides expert-driven data labeling services for machine learning projects. They specialize in high-quality, secure annotation for complex image and text datasets. By using in-house, long-term labelers instead of crowdsourcing, they ensure superior accuracy, flexibility, and data security. Their services cater to various industries, including autonomous vehicles, microscopy, retail, and infrastructure, helping companies accelerate their AI development by delivering reliable training data.
About Training Data
Training Data tools are platforms designed to create, manage, and procure high-quality datasets for training artificial intelligence models. As a fundamental component of AI Infrastructure, these tools provide the structured information necessary for machine learning algorithms to learn patterns and make accurate predictions. They are essential for improving model performance, reducing bias, and accelerating the development lifecycle of AI applications. Key functionalities range from data annotation and labeling to synthetic data generation and quality assurance.
Core Features
- Data Annotation and Labeling: Provides intuitive interfaces for accurately labeling various data types, including images, text, audio, and video, with techniques like bounding boxes, semantic segmentation, and entity tagging.
- Synthetic Data Generation: Creates artificial, yet realistic, data to augment or replace real-world datasets, overcoming issues of data scarcity, privacy, and edge cases.
- Dataset Management: Offers a centralized platform to version, search, and track datasets, ensuring traceability and collaboration across machine learning teams.
- Quality Assurance Workflows: Includes features for review, consensus scoring, and error detection to maintain high standards of label accuracy and data consistency.
Applicable Scenarios
These tools are critical in industries that rely on custom AI models. For example, in the automotive sector for training self-driving cars with annotated road scenes, in healthcare for developing diagnostic models from labeled medical images, and in retail for building product recommendation engines based on user behavior data.
Selection Criteria
When choosing a Training Data tool, consider the specific data types you work with (e.g., video, 3D point clouds). Evaluate the quality and efficiency of the annotation interfaces, the platform's ability to scale with large datasets, and its integration capabilities with your existing MLOps pipeline. Also, assess the collaboration features and quality control mechanisms.
Training DataUse Cases
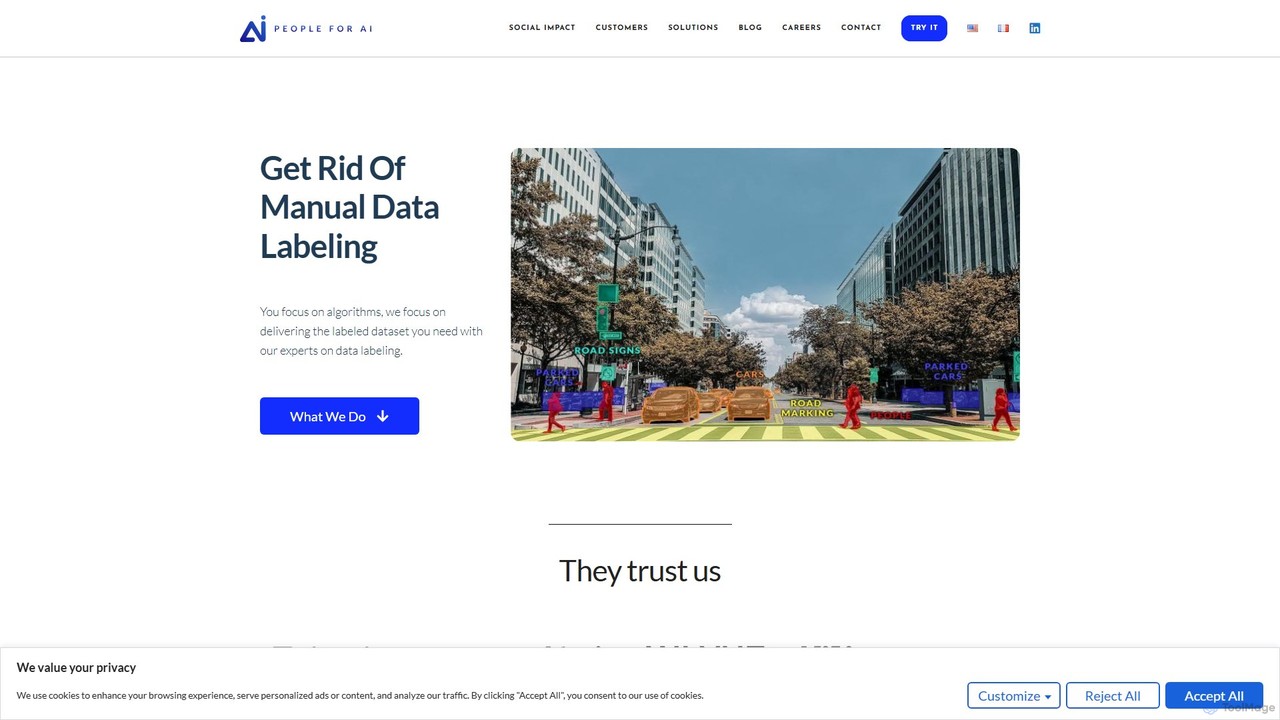
Annotating Road Scenes for Autonomous Driving
An ML engineer at an automotive technology company is tasked with improving the perception model of a self-driving vehicle. Using a training data platform, their team annotates thousands of hours of video footage from test vehicles. They use tools for semantic segmentation to label every pixel of the road, lanes, and sidewalks, and bounding boxes for object detection to identify pedestrians, vehicles, and traffic signs. This meticulously labeled dataset is then used to train and validate the AI, significantly enhancing its ability to navigate complex urban environments safely.
Labeling Medical Images for Disease Detection
A medical research team is developing an AI model to detect early signs of cancer from CT scans. Due to the critical nature of the task, data accuracy is paramount. They use a specialized training data platform that supports DICOM image formats and provides high-precision annotation tools. Radiologists collaborate on the platform to contour potential tumors and label anomalies. The platform's quality assurance features, such as peer review and consensus scoring, ensure that the final dataset is highly reliable, leading to a more accurate and trustworthy diagnostic AI.
Generating Synthetic Data for Financial Fraud Detection
A fintech company wants to build a more robust fraud detection model but is constrained by privacy regulations (like GDPR) that limit the use of real customer transaction data. To overcome this, their data science team uses a synthetic data generation tool. The tool analyzes the statistical properties of their anonymized real data and generates a new, much larger dataset of artificial transactions that mimics real-world patterns without containing any personally identifiable information. This allows them to train their model on diverse and complex fraud scenarios, improving detection rates while remaining fully compliant with privacy laws.
Curating Datasets for Natural Language Processing (NLP)
A conversational AI startup is building a next-generation chatbot. To train the model to understand user intent accurately, they need a large, diverse dataset of annotated text. Using a data platform, they collect and upload thousands of user queries. A team of annotators then uses the platform's text annotation tools to label each query with specific intents (e.g., 'check_balance', 'make_payment') and to identify and tag entities (e.g., dates, amounts, names). The platform's version control allows them to track changes and manage multiple dataset versions as the model evolves, ensuring a systematic approach to model improvement.
Improving E-commerce Search with Product Tagging
An online retail giant aims to enhance its product search and recommendation engine. Their data team uses a training data service to label millions of product images with detailed attributes. Annotators tag items with categories (e.g., 'women's apparel'), sub-categories ('dresses'), styles ('bohemian'), and specific features ('floral print', 'v-neck'). This structured, high-quality data is used to train a computer vision model that can automatically categorize new products and power a more intuitive 'visual search' feature, leading to better product discovery and increased sales.
Training a Voice Assistant with Audio Transcription
A tech company is developing a new smart home voice assistant. To ensure it understands various accents and commands, they collect thousands of audio clips of people speaking. Using a data annotation platform, a distributed team of linguists transcribes the speech to text and labels background noises like 'doorbell' or 'dog_barking'. They also tag the speaker's emotion or intent. This rich audio dataset enables the engineers to train a robust speech recognition model that performs well in real-world, noisy home environments, providing a superior user experience.