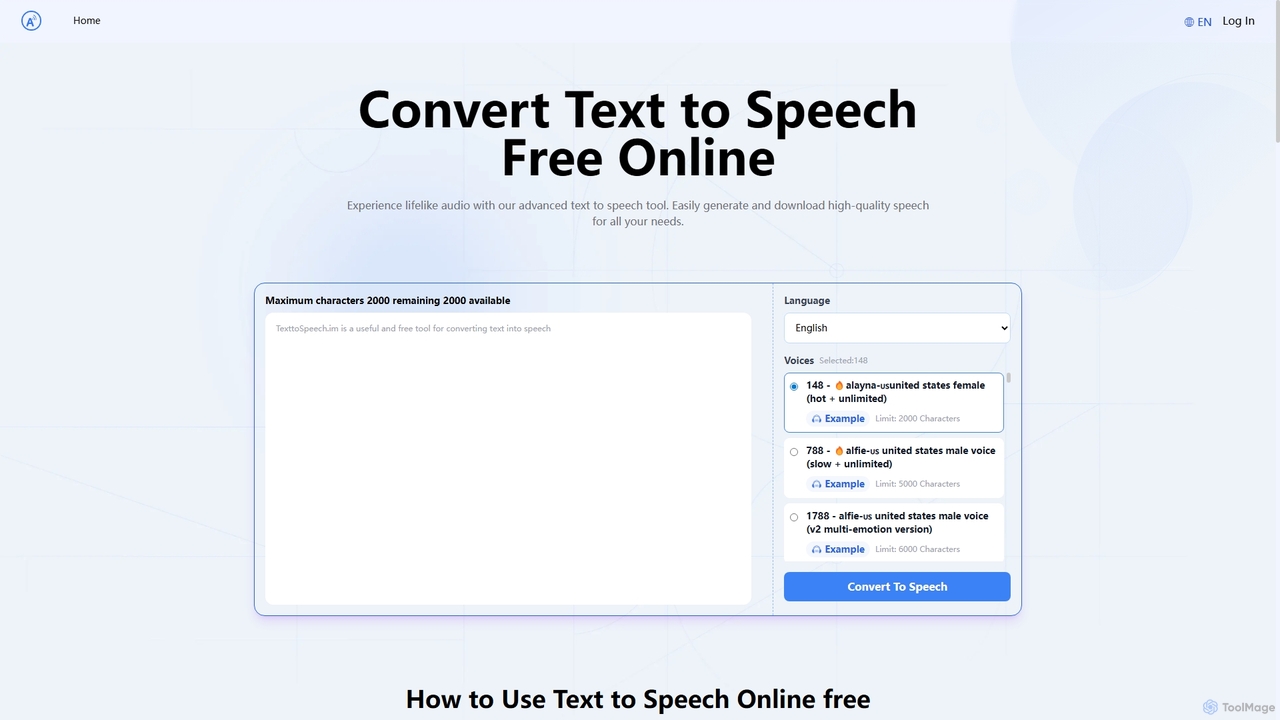
Text to Speech.im
Text to Speech.im is a free online AI tool that converts text into natural-sounding speech. It supports a …
Text to Speech.im is a free online AI tool that converts text into natural-sounding speech. It supports a vast array of languages and voices, allowing users to generate high-quality audio for videos, e-learning, accessibility, and more. Customize voice speed and volume, then easily download the generated audio as an MP3 file.

Voice Isolator
Voice Isolator is a comprehensive AI-powered audio suite designed for pristine sound quality. It excels at removing background …
Voice Isolator is a comprehensive AI-powered audio suite designed for pristine sound quality. It excels at removing background noise, isolating vocals and instruments from any track, cleaning up voice recordings for clarity, and generating natural-sounding speech from text. Ideal for podcasters, musicians, and content creators seeking professional-grade audio processing with a simple, fast, and intuitive web-based interface.
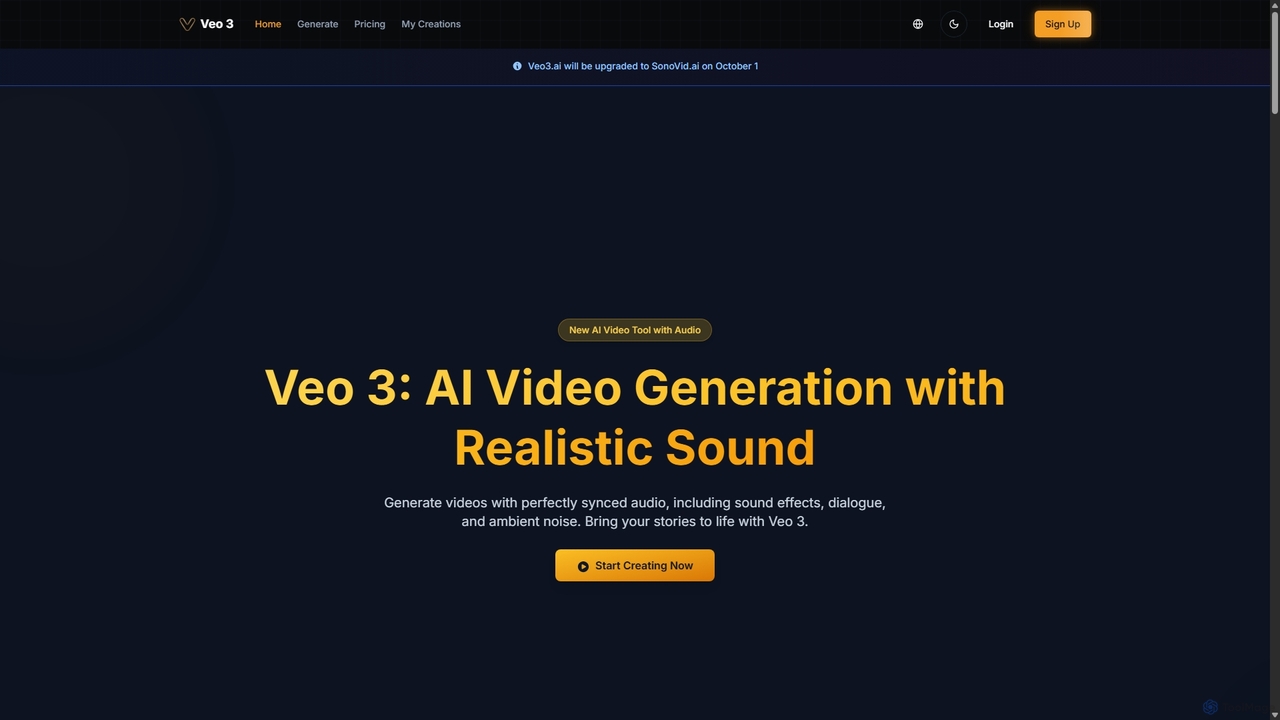
Veo 3
Veo 3 is an advanced AI video generator powered by Google's Veo 3 model. It specializes in creating …
Veo 3 is an advanced AI video generator powered by Google's Veo 3 model. It specializes in creating high-quality, 1080p videos up to 8 seconds long with perfectly synchronized, natively generated audio. Users can generate content from text or image prompts, complete with realistic dialogue, sound effects, ambient noise, and precise lip-syncing, making it ideal for creators and marketers.
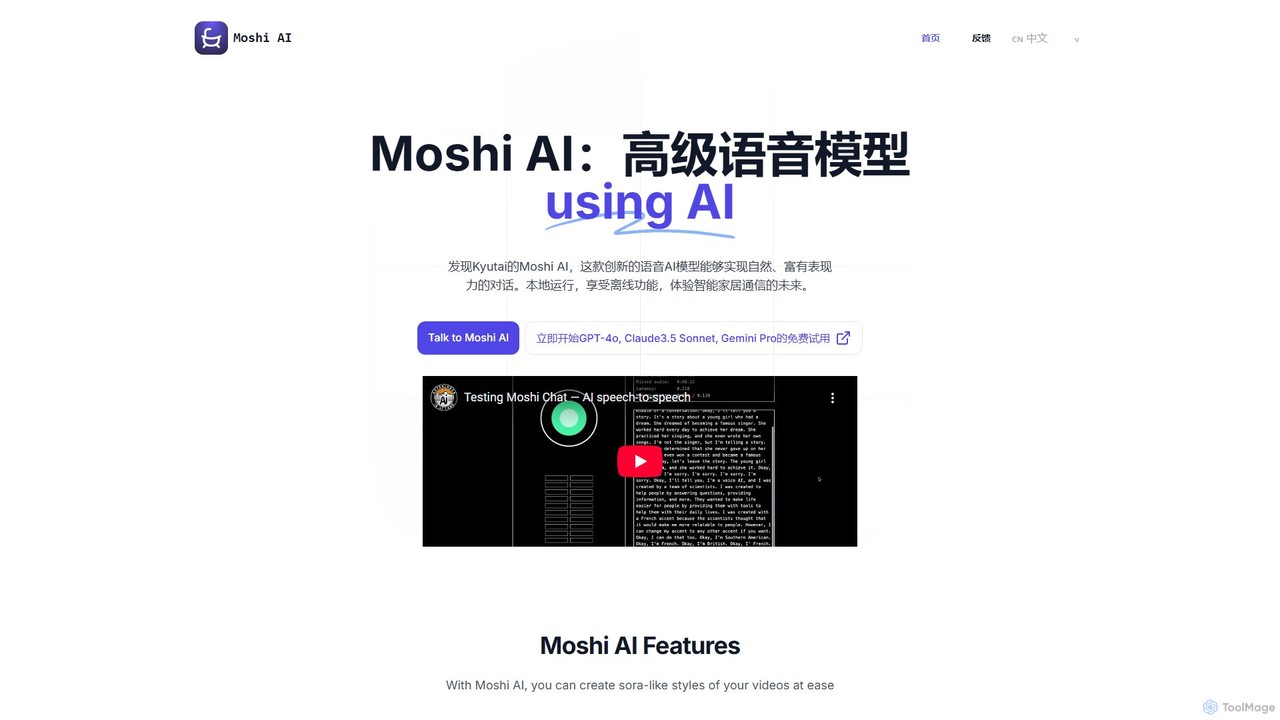
Moshi AI
Moshi AI is an advanced, low-latency conversational voice AI model developed by Kyutai. It enables natural, expressive, and …
Moshi AI is an advanced, low-latency conversational voice AI model developed by Kyutai. It enables natural, expressive, and interruptible dialogues, designed to run locally on various hardware for offline use. This makes it ideal for privacy-focused applications like smart home devices and in-car systems.
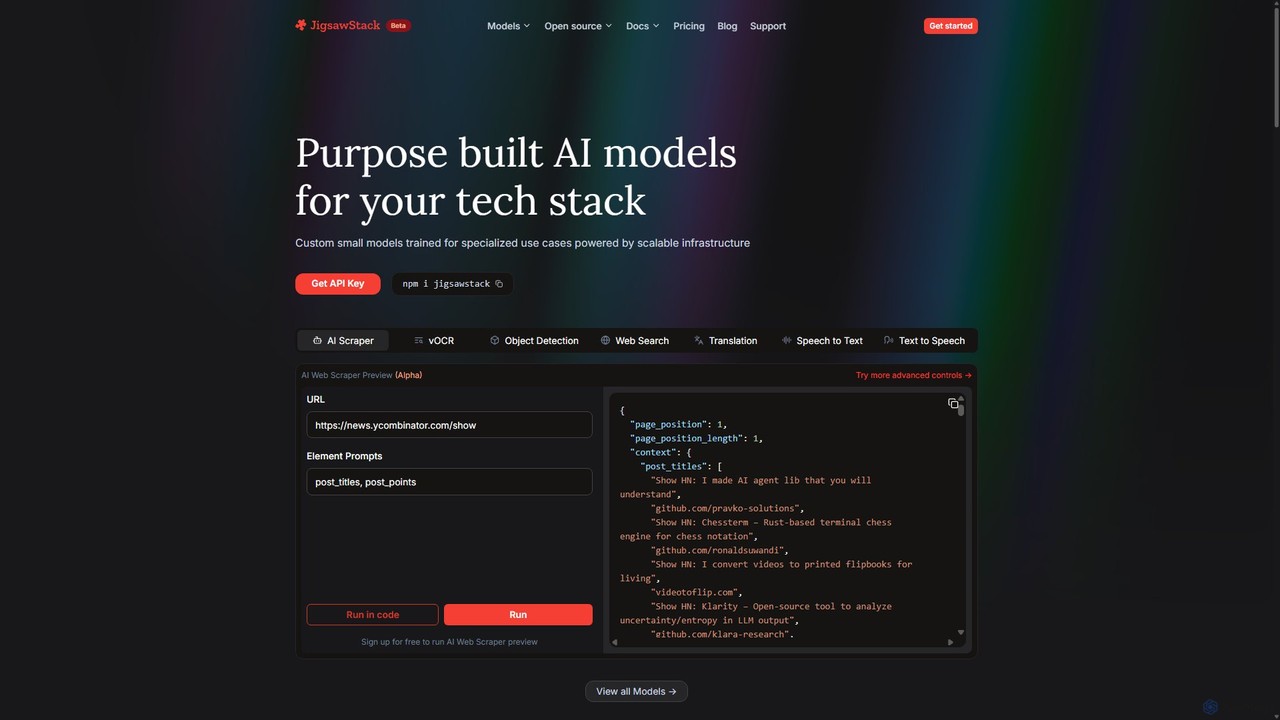
JigsawStack
JigsawStack offers a suite of purpose-built, small AI models for developers, accessible via a single API. It simplifies …
JigsawStack offers a suite of purpose-built, small AI models for developers, accessible via a single API. It simplifies complex backend tasks like web scraping, OCR, translation, and speech-to-text with fast, reliable, and scalable infrastructure. Designed for seamless integration, it provides a developer-first experience with structured data output and global support, enabling teams to build and ship features faster.
Speechllect
Speechllect is an advanced AI-powered speech-to-text (STT) and text-to-speech (TTS) platform. It utilizes a unique "Sense Theory" to …
Speechllect is an advanced AI-powered speech-to-text (STT) and text-to-speech (TTS) platform. It utilizes a unique "Sense Theory" to not only transcribe and synthesize speech but also to understand and generate emotional tone and intonation. This makes it ideal for creating human-like voice interactions for businesses, developers, and content creators.
TextSynth
TextSynth offers developers powerful, cost-effective access to a suite of AI models, including large language models (LLMs), text-to-image, …
TextSynth offers developers powerful, cost-effective access to a suite of AI models, including large language models (LLMs), text-to-image, text-to-speech, and speech-to-text, through a flexible REST API and an interactive playground. It features models like Llama, Mistral, Stable Diffusion, and Whisper, optimized for speed and affordability.
WaveSpeedAI
WaveSpeedAI is a high-performance, unified API platform designed to accelerate AI image, video, and audio generation. It provides …
WaveSpeedAI is a high-performance, unified API platform designed to accelerate AI image, video, and audio generation. It provides developers and creators with a single point of access to a vast library of state-of-the-art models from providers like Google, ByteDance, and Kuaishou, enabling faster building, creation, and scaling of multimodal AI applications.
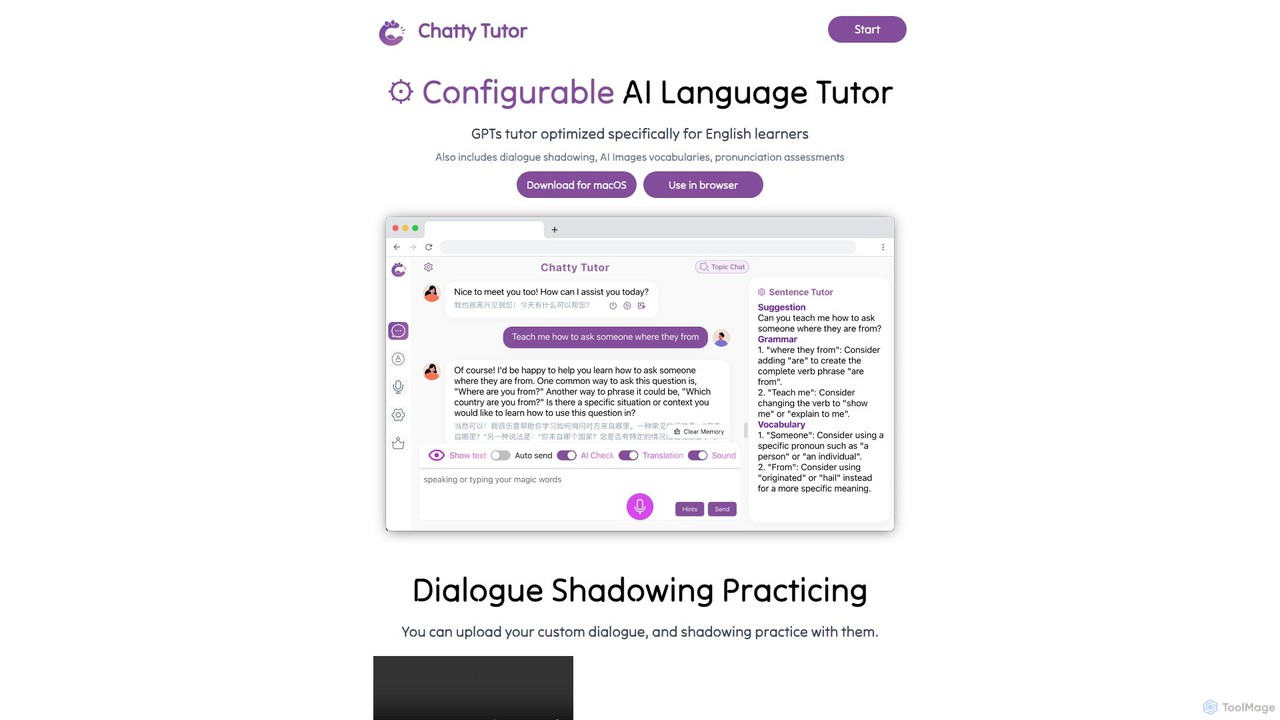
ChattyTutor
ChattyTutor is a highly configurable AI language tutor, powered by GPT, specifically optimized for English learners. It offers …
ChattyTutor is a highly configurable AI language tutor, powered by GPT, specifically optimized for English learners. It offers interactive features like dialogue shadowing, pronunciation assessment, and vocabulary building with AI-generated images, available on macOS and web browsers.
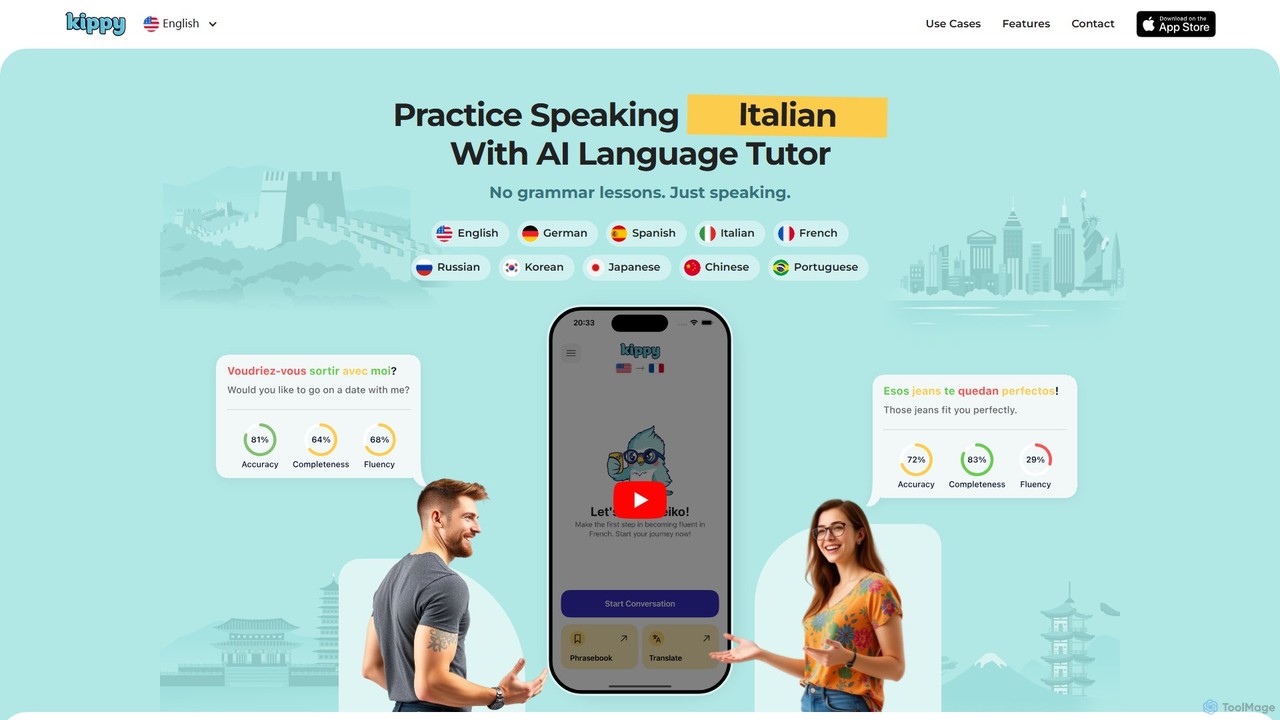
Kippy
Kippy is an AI-powered language tutor designed to help you master speaking and pronunciation. Practice real-world conversations in …
Kippy is an AI-powered language tutor designed to help you master speaking and pronunciation. Practice real-world conversations in 10 languages with instant feedback, grammar correction, and guided responses to build fluency and confidence. It's the perfect supplement for learners who want to move beyond textbooks and start speaking naturally.
Text Generator
Text Generator is a versatile and highly affordable AI platform offering unlimited text, code, and speech generation. It …
Text Generator is a versatile and highly affordable AI platform offering unlimited text, code, and speech generation. It provides a powerful API, including an OpenAI-compatible endpoint for easy migration, making it a cost-effective solution for developers, marketers, and content creators.

MiniMax
MiniMax is an AI research company providing a full-stack platform of AGI-powered foundation models. It offers state-of-the-art APIs …
MiniMax is an AI research company providing a full-stack platform of AGI-powered foundation models. It offers state-of-the-art APIs for text (MiniMax-M1 with 1M context), video (Hailuo 02), and speech (Speech 02), alongside a suite of free AI-native applications like MiniMax Chat, Agent, and creative tools. It focuses on high performance, computational efficiency, and cost-effectiveness for both developers and end-users.
About Speech Synthesis
Speech Synthesis tools are AI-powered technologies that convert written text into natural-sounding human speech. These systems leverage advanced deep learning models and neural networks to generate audio output with customizable voices, emotions, and languages. They are widely used to automate voiceovers, enhance accessibility features, and create interactive user experiences across various digital platforms.
Core Features
- Text-to-Speech (TTS): Converts input text into spoken audio, often with options for different voices and speaking styles.
- Voice Customization: Allows users to select from a range of predefined voices or even create custom voice profiles to match specific brand identities.
- Multi-language Support: Generates speech in numerous languages and dialects, catering to global audiences and diverse content needs.
- Emotional Expression: Incorporates emotional nuances like happiness, sadness, or anger into the synthesized speech, making interactions more lifelike.
- SSML (Speech Synthesis Markup Language) Support: Provides fine-grained control over pronunciation, emphasis, pauses, and speaking rate for highly customized audio output.
Applicable Scenarios
Speech Synthesis tools are invaluable for content creators, developers, and businesses. They enable the rapid production of audio content for e-learning modules, podcasts, and video narrations. Developers integrate these tools to build accessible applications for visually impaired users or to create more engaging voice interfaces for smart devices and chatbots.
How to Choose
When selecting a Speech Synthesis tool, consider the naturalness and quality of the generated voices, the breadth of language and accent support, and the availability of emotional expression. Evaluate the ease of integration via APIs, the flexibility of voice customization options, and the pricing model based on your usage volume and specific feature requirements.
Speech SynthesisUse Cases
Automating Audiobook and Podcast Narration
Content creators and publishers can use speech synthesis tools to quickly convert written manuscripts into high-quality audiobooks or podcast episodes. By selecting a suitable voice and adjusting parameters like pace and tone, they can produce engaging audio content without the need for human voice actors, significantly reducing production time and costs while expanding their audience reach.
Enhancing Accessibility for Visually Impaired Users
Developers integrate speech synthesis APIs into applications, websites, and operating systems to provide screen-reading capabilities. This allows visually impaired users to have digital text content, such as articles, emails, or navigation instructions, read aloud to them. This application significantly improves digital accessibility and inclusivity, enabling a wider audience to interact with information independently.
Creating Voiceovers for Video Content and E-learning
Video producers and e-learning course creators utilize speech synthesis to generate professional-sounding voiceovers for their multimedia projects. Instead of hiring voice talent or recording themselves, they can input scripts and receive audio files in various languages and voices. This streamlines the localization process for global content and ensures consistent voice quality across all learning modules or video segments.
Developing Interactive Voice Response (IVR) Systems
Businesses leverage speech synthesis to power their Interactive Voice Response (IVR) systems, providing automated customer service and support. Instead of pre-recording every possible phrase, companies can dynamically generate responses based on customer queries. This ensures a consistent brand voice, reduces the need for extensive voice talent libraries, and allows for rapid updates to IVR scripts, improving customer experience and operational efficiency.
Creating Dynamic Voice Alerts and Notifications
Applications and smart devices can use speech synthesis to generate real-time voice alerts and notifications for users. For instance, a smart home system can announce a door opening, or a navigation app can provide turn-by-turn directions. This provides a hands-free, eyes-free way for users to receive critical information, enhancing convenience and safety in various contexts, from driving to daily household tasks.
Personalizing Digital Assistants and Chatbots
Developers and product managers use speech synthesis to give digital assistants (like Siri or Alexa) and chatbots unique, recognizable voices and personalities. By customizing the voice, tone, and even emotional inflections, they can create a more engaging and human-like interaction experience. This personalization helps build user trust and makes the technology feel more intuitive and less robotic, improving overall user satisfaction.