Sinkove
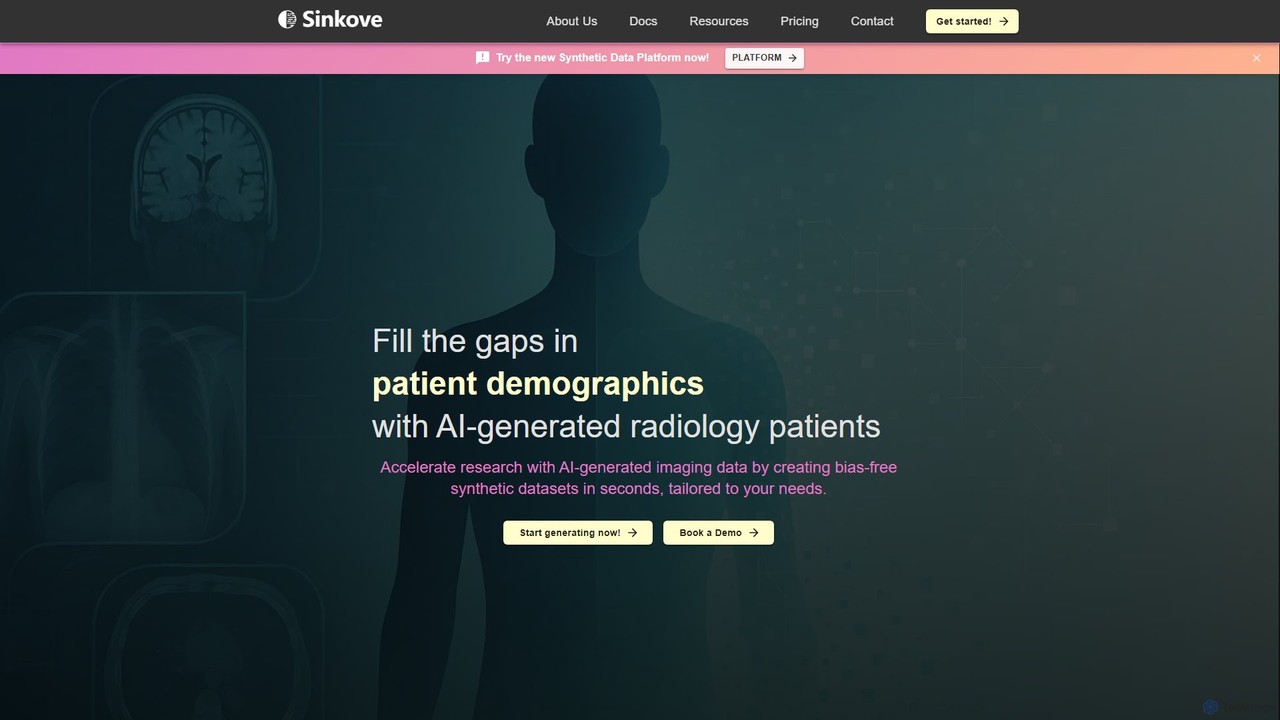
Sinkove is an AI platform that generates high-quality, synthetic radiology data. It helps medical researchers and clinicians accelerate …
Sinkove is an AI platform that generates high-quality, synthetic radiology data. It helps medical researchers and clinicians accelerate research, eliminate data bias, and reduce costs by creating customized, diverse, and regulatory-grade imaging datasets in seconds.

maketafi
Tafi is a leading provider of enterprise-grade 3D character datasets for AI training, simulation, and content creation. It …
Tafi is a leading provider of enterprise-grade 3D character datasets for AI training, simulation, and content creation. It offers scalable, topology-consistent, and parametrically generated 3D characters, complete with rich metadata, to power advanced AI models in robotics, gaming, XR, and multimodal learning.
About Synthetic Data Generation
Synthetic Data Generation tools are a class of AI applications that programmatically create artificial data that mirrors the statistical properties of real-world data. These tools often leverage advanced machine learning models, such as Generative Adversarial Networks (GANs), to learn patterns from an original dataset and then produce new, non-existent data points. The primary value lies in enabling robust AI model training and software testing in situations where real data is scarce, sensitive, or restricted by privacy regulations. This approach provides a scalable and privacy-compliant way to augment datasets and explore edge cases without exposing actual information.
Core Features
- Data Type Synthesis: Generates various data formats, including tabular, time-series, image, and text data, to match specific needs.
- Statistical Fidelity: Ensures the synthetic data maintains the same statistical distributions, correlations, and patterns as the original data.
- Privacy Preservation: Implements techniques like Differential Privacy to guarantee that generated data cannot be traced back to any real individual.
- Data Augmentation: Creates variations of existing data points to balance imbalanced datasets or expand training sets for improved model robustness.
- Scenario Simulation: Allows for the creation of data representing specific, rare, or hypothetical scenarios that are not present in the original dataset.
Use Cases
These tools are widely used in industries handling sensitive information, such as healthcare for creating anonymous patient records for research, and finance for modeling fraud patterns without using real transaction data. They are also essential for technology companies, particularly in training autonomous vehicles by simulating rare driving conditions and for software developers who need realistic user data for testing applications without compromising privacy.
How to Choose
When selecting a Synthetic Data Generation tool, first consider the types of data it supports (e.g., tabular, image, text). Evaluate the quality and fidelity of the generated data by checking for statistical similarity metrics. Assess the strength of its privacy-preserving features, such as support for Differential Privacy. Finally, consider its scalability for large datasets and whether it offers a user-friendly interface or requires deep technical expertise via an API.
Synthetic Data GenerationUse Cases
Training AI Models with Privacy-Sensitive Data
A healthcare research institution needs to develop a machine learning model to predict disease outbreaks but is restricted by strict patient privacy laws like HIPAA. Using real patient data is not an option. Data scientists use a synthetic data generation tool to analyze the statistical structure of the confidential patient records. The tool then generates a new, fully artificial dataset that mimics the patterns, correlations, and distributions of the original data without containing any real personal health information. This allows researchers to train, test, and validate their predictive models effectively and safely, accelerating medical research while ensuring complete patient confidentiality.
Augmenting Imbalanced Datasets for Fraud Detection
A financial services company is building a model to detect fraudulent transactions. The challenge is that fraudulent cases are extremely rare compared to legitimate ones, creating a highly imbalanced dataset that biases the model. An ML engineer employs a synthetic data generation tool to create realistic, high-quality examples of fraudulent transactions. By oversampling the minority class (fraud) with this synthetic data, they create a balanced training set. The resulting model becomes significantly more accurate at identifying rare fraud patterns, reducing financial losses without increasing false positives on legitimate transactions.
Simulating Edge Cases for Autonomous Vehicle Training
An automotive company is developing a self-driving car's perception system. The system needs to be trained on countless scenarios, especially rare and dangerous 'edge cases' like a pedestrian suddenly appearing from behind a bus or extreme weather conditions. It is impractical and unsafe to capture enough real-world data for all these situations. Engineers use a synthetic data generation platform to create photorealistic simulations of these specific edge cases. This allows them to generate vast amounts of training data for rare events, drastically improving the AI's reliability and safety in critical situations before any real-world deployment.
Accelerating Software Testing and Quality Assurance
A software development team is creating a new customer relationship management (CRM) platform. To ensure the software is robust, they need to test it with a large, diverse database of user profiles, interactions, and histories. Creating this data manually is slow and often lacks realism. The QA team uses a synthetic data tool to quickly generate thousands of realistic but entirely fictional user accounts, complete with names, contact details, and activity logs. This enables them to perform comprehensive load testing, bug hunting, and feature validation across a wide range of data scenarios, leading to a higher-quality product launch.
Creating Realistic Data for Product Demos
A B2B software company needs to showcase its powerful data analytics platform to potential clients. Using real customer data in a live demo is a major security and privacy risk. The marketing and sales teams use a synthetic data generator to create a rich, believable dataset that reflects their target industry. This dataset populates the demo environment with realistic customer names, sales figures, and engagement metrics. As a result, they can deliver compelling, interactive product demonstrations that highlight the platform's full capabilities without ever exposing sensitive information, building trust with prospective customers.
Modeling Future Scenarios for Financial Risk Analysis
A risk management team at an investment bank needs to stress-test their portfolios against potential market crashes or unforeseen economic events. Historical data is limited and may not cover novel scenarios. The team uses a synthetic data generation tool to create time-series data that simulates various high-stress market conditions, such as rapid inflation or a sudden asset bubble burst. By running their risk models against this synthetic data, they can better understand potential vulnerabilities in their investment strategies and develop more resilient financial plans, improving their preparedness for future market volatility.