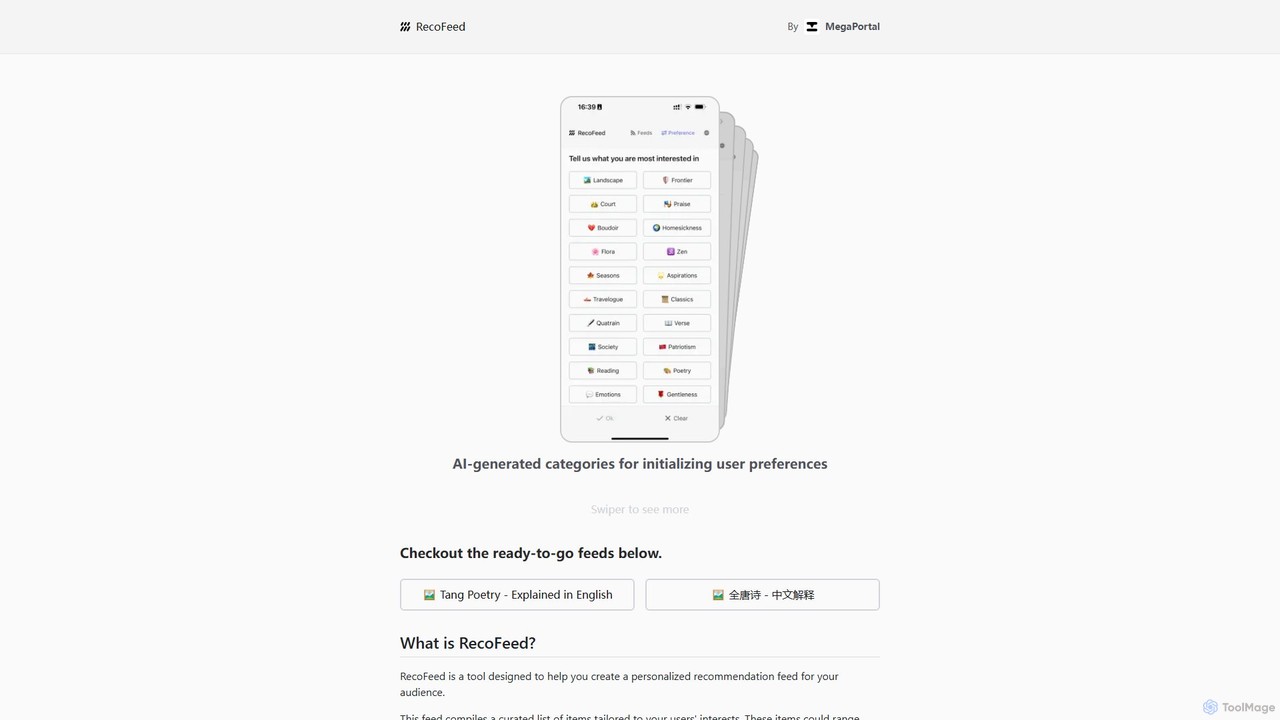
RecoFeed
RecoFeed is a developer-focused tool for creating personalized recommendation feeds. It utilizes an on-device vector database, CloseVector, to …
RecoFeed is a developer-focused tool for creating personalized recommendation feeds. It utilizes an on-device vector database, CloseVector, to generate real-time suggestions locally on the user's device, ensuring maximum data privacy and low latency. It's designed for apps and websites across various sectors like e-commerce, content platforms, and social media.
About Vector Database
A Vector Database is a specialized database system designed to efficiently store, manage, and search high-dimensional vector embeddings. Unlike traditional databases that index data based on exact values, vector databases use Approximate Nearest Neighbor (ANN) algorithms to find the most similar items based on their vector representations. This capability is fundamental for powering advanced AI applications such as semantic search, recommendation engines, and retrieval-augmented generation (RAG) for large language models. They offer exceptional speed and scalability for similarity search tasks on massive, unstructured datasets like text, images, and audio.
Core Features
- High-Dimensional Vector Indexing: Efficiently organizes vector data using algorithms like HNSW or IVF for rapid retrieval.
- Similarity Search: Performs searches based on vector proximity (e.g., cosine similarity, Euclidean distance) to find semantically similar items.
- Scalability and Performance: Designed to handle billions of vectors and high query loads with low latency, crucial for real-time applications.
- Metadata Filtering: Combines vector similarity search with traditional metadata filtering for more precise and context-aware results.
Use Cases
Vector databases are essential for AI/ML engineers, data scientists, and developers building applications that require understanding semantic relationships in data. They are widely used in e-commerce for visual search and recommendations, in enterprise systems for intelligent knowledge base search, and in generative AI to provide factual context to large language models, reducing inaccuracies.
How to Choose
When selecting a vector database, evaluate its indexing algorithms and performance benchmarks for your specific data type. Consider the deployment model—cloud-managed services offer ease of use, while self-hosted options provide more control. Also, check for robust SDKs in your preferred programming languages and integrations with popular AI frameworks like LangChain or LlamaIndex. Finally, assess its scalability and pricing model to ensure it meets your long-term needs.
Vector DatabaseUse Cases
Powering AI Chatbots with Retrieval-Augmented Generation (RAG)
An AI developer is tasked with building a customer support chatbot that must provide accurate answers from a private knowledge base, such as product manuals and internal FAQs. To achieve this, documents are segmented, converted into vector embeddings, and stored in a vector database. When a user asks a question, their query is vectorized and used to search the database for the most relevant document chunks. These retrieved chunks are then passed to a Large Language Model (LLM) as context, enabling the chatbot to generate precise, context-aware answers based on proprietary data and significantly reducing the risk of hallucinations.
Implementing Semantic Search for Internal Documents
A knowledge manager in a large corporation needs to improve how employees find information across thousands of internal reports and policy documents. Traditional keyword search is inefficient, often failing to surface conceptually related content. By implementing a vector database, all documents are vectorized to capture their semantic meaning. Employees can now search using natural language questions. The system performs a similarity search to retrieve documents based on conceptual relevance, not just keyword matches. This leads to an 80% improvement in information retrieval speed, boosting productivity and knowledge sharing.
Building a Visual Search Engine for E-commerce
An e-commerce developer for an online fashion retailer wants to create a 'shop the look' feature, allowing customers to find products by uploading an image. To enable this, the entire product image catalog is processed by a vision model to generate vector embeddings, which are then stored in a vector database. When a user uploads an image, it is similarly converted into a vector. The database then performs a high-speed similarity search to find and display product images with the closest vectors. This intuitive search experience significantly improves product discovery and has been shown to increase conversion rates by helping customers find visually similar items instantly.
Creating Personalized Content Recommendation Systems
A data scientist at a media streaming service aims to increase user engagement by providing highly relevant content recommendations. They represent each piece of content (e.g., movies, articles) and each user's profile as high-dimensional vectors. When a user interacts with content, their profile vector is updated. A vector database is used to perform real-time similarity searches, finding content vectors that are closest to a user's interest vector. This allows the platform to deliver dynamic, personalized recommendations that adapt to the user's evolving tastes, resulting in longer session durations and higher user retention.
Detecting Anomalies in Cybersecurity Network Traffic
A cybersecurity analyst needs to identify potential threats within vast amounts of network traffic data in real-time. Normal operational data, such as log entries and network packets, is converted into vector embeddings to establish a baseline cluster of 'normal' activity in the vector space. A vector database continuously ingests new data, converts it to vectors, and compares it against this baseline. Any data point whose vector falls far from the normal cluster is instantly flagged as an anomaly. This approach enables the rapid detection of zero-day threats or system failures that don't match known signatures, providing a critical layer of proactive security.
De-duplication of Large-Scale Image Datasets
A machine learning engineer is preparing a massive dataset of images to train a computer vision model. To ensure data quality and prevent model bias, it's crucial to remove duplicate or near-duplicate images. Each image in the dataset is converted into a vector embedding and indexed in a vector database. The engineer then runs a similarity search for each image to find others within a very small distance threshold. This process efficiently identifies and flags all sets of near-duplicates for removal, resulting in a cleaner, more diverse training dataset. This improves the final model's accuracy and generalization capabilities.