Langtrace
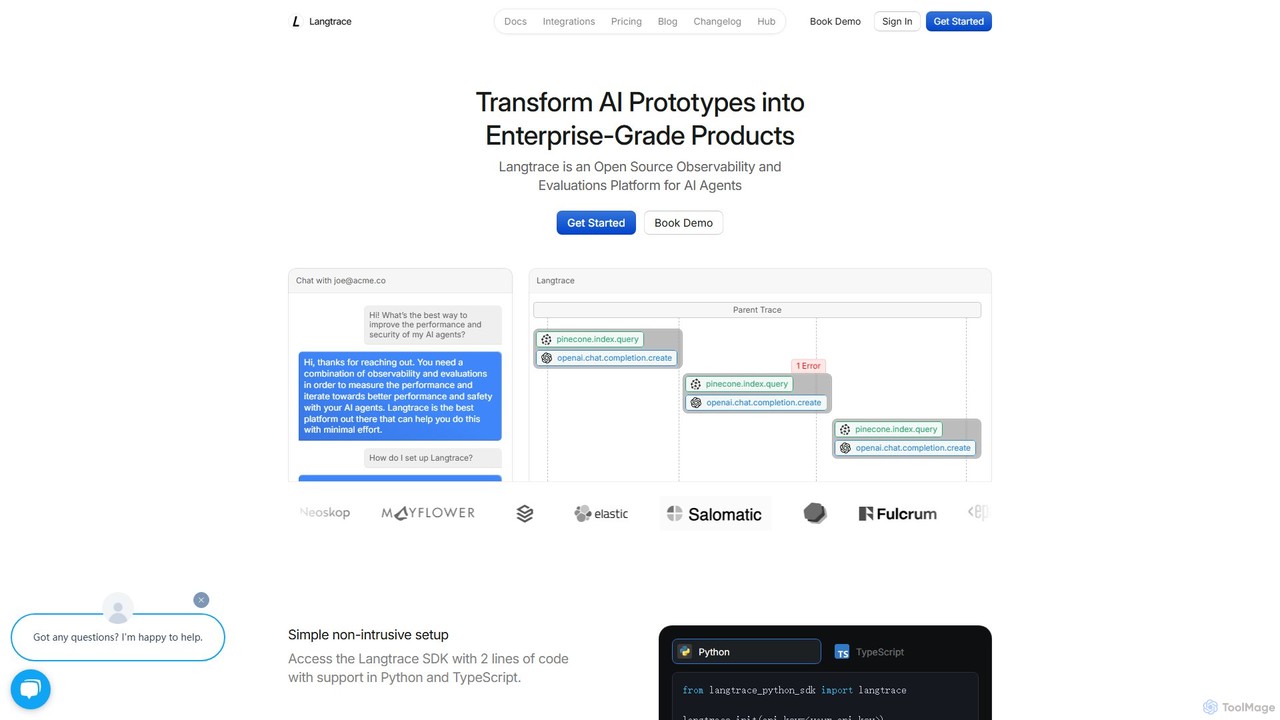
Langtrace is an open-source observability and evaluation platform for AI agents and LLM applications. It helps developers monitor, …
Langtrace is an open-source observability and evaluation platform for AI agents and LLM applications. It helps developers monitor, debug, and improve performance, transforming AI prototypes into enterprise-grade products with features like tracing, prompt management, and robust security.
About Model Training & Evaluation
Model Training & Evaluation tools are specialized AI platforms designed to build, refine, and assess the performance of machine learning models. These tools provide comprehensive environments for data preparation, algorithm selection, hyperparameter tuning, and rigorous testing, ensuring models are robust, accurate, and ready for deployment. They are crucial for data scientists, machine learning engineers, and developers aiming to create high-performing AI solutions within the broader context of productivity enhancement.
Core Features
- Automated Data Preprocessing: Tools to clean, transform, and normalize raw data, making it suitable for model ingestion and reducing manual effort.
- Algorithm Selection & Tuning: Offers a range of machine learning algorithms and facilitates hyperparameter optimization to achieve optimal model performance.
- Performance Metrics & Visualization: Provides various metrics (e.g., accuracy, precision, recall, F1-score) and visual aids (e.g., confusion matrices, ROC curves) for in-depth model assessment.
- Version Control & Experiment Tracking: Manages different model iterations and tracks experiment parameters, results, and metadata for reproducibility and comparison.
- Scalable Infrastructure: Supports distributed training and leverages cloud resources to handle large datasets and complex models efficiently.
Use Cases
These tools are essential for organizations developing custom AI applications, from predictive analytics to natural language processing. They enable data science teams to iterate rapidly on model designs, compare different approaches, and ensure the deployed models meet stringent performance and reliability standards. For example, a financial institution might use these tools to train and evaluate fraud detection models, while a healthcare provider could develop diagnostic AI systems.
How to Choose
When selecting a Model Training & Evaluation tool, consider its compatibility with your existing data infrastructure and programming languages. Evaluate the range of supported algorithms, the flexibility of hyperparameter tuning, and the comprehensiveness of evaluation metrics. Scalability for future data growth and the availability of collaboration features for team-based projects are also critical factors. Finally, assess the ease of integration with deployment pipelines and the overall cost-effectiveness.
Model Training & EvaluationUse Cases
Optimizing Predictive Analytics Models
A data scientist in an e-commerce company uses these tools to train and fine-tune a customer churn prediction model. By experimenting with different algorithms and hyperparameters, they can achieve higher accuracy in identifying at-risk customers, allowing the marketing team to implement targeted retention strategies and significantly reduce customer attrition.
Developing Robust Computer Vision Systems
An AI engineer at an autonomous vehicle company leverages model training and evaluation platforms to develop and test object detection models. They can efficiently manage large image datasets, train models on various architectures, and rigorously evaluate performance metrics like mean Average Precision (mAP) to ensure the safety and reliability of the vehicle's perception system.
Refining Natural Language Processing (NLP) Models
A machine learning researcher in a tech firm utilizes these tools to train and evaluate a sentiment analysis model for social media monitoring. They can preprocess vast amounts of text data, experiment with different transformer models, and assess the model's ability to accurately classify positive, negative, and neutral sentiments, providing valuable insights for brand reputation management.
Automating Quality Control in Manufacturing
A manufacturing engineer employs model training and evaluation tools to build an AI system for defect detection on assembly lines. By training models on images of both flawless and defective products, they can automate the inspection process, significantly reduce manual errors, and improve product quality consistency, leading to cost savings and increased efficiency.
Personalizing User Experiences in Applications
A product manager at a streaming service uses these platforms to train and evaluate recommendation engines. They can experiment with collaborative filtering and content-based models, measure metrics like click-through rates and user engagement, and continuously refine the algorithms to deliver highly personalized content suggestions, enhancing user satisfaction and retention.
Benchmarking and Comparing AI Model Performance
An academic researcher or a competitive AI team uses these tools to systematically train multiple models on a standardized dataset and compare their performance across various metrics. This allows for objective benchmarking of new algorithms against existing state-of-the-art solutions, contributing to advancements in the field and identifying superior approaches for specific tasks.