
Groq Overview
Groq is an AI technology company that has developed a groundbreaking infrastructure for AI inference, designed from the ground up for speed, quality, and cost-effectiveness. At the heart of Groq's offering is its proprietary Language Processing Unit (LPU™), a new type of processor built specifically for the computational demands of running AI models, particularly large language models (LLMs). Unlike GPUs, which were adapted from graphics processing, the LPU is purpose-built for inference, enabling it to deliver predictable, sub-millisecond latency and exceptionally high throughput in tokens per second. This makes it possible to build truly real-time, conversational AI applications that were previously unfeasible.
The technology is accessible through GroqCloud™, a full-stack platform that allows developers and enterprises to leverage the power of LPUs via a simple and robust API. Groq supports a wide range of popular open-source models, including various versions of Llama, Mistral, Qwen, and Gemma, as well as specialized models for Automatic Speech Recognition (ASR) like Whisper and Text-to-Speech (TTS). This focus on speed and efficiency aims to fuel a new wave of innovation by making high-performance AI accessible and affordable for a global community of over 1.9 million developers.
How to use Groq
Getting started with Groq is designed to be straightforward for developers. The primary method of interaction is through the GroqCloud™ API.
- Sign Up: Create a free account on the Groq website to access the developer console.
- Get API Key: Once registered, you can generate an API key from your dashboard. This key will authenticate your requests.
- Integration: With the API key, you can start making calls to Groq's model endpoints. The integration process is simple, often requiring just a few lines of code to replace an existing API endpoint (e.g., from OpenAI or another provider) with the Groq endpoint. The platform provides clear documentation and SDKs to facilitate this process.
- Choose a Model: Select from a diverse list of supported LLM, ASR, or TTS models based on your application's needs for speed, context window, and capability.
- Batch Processing: For large-scale, non-real-time tasks, developers can use the Batch API. This allows for submitting thousands of requests asynchronously at a 50% cost reduction, without affecting standard rate limits.
- Enterprise Deployment: For large enterprises with specific security or performance needs, Groq also offers on-premise deployment solutions.
Core Features of Groq
- LPU™ Inference Engine: A custom-designed processor specifically for AI language inference, delivering deterministic, ultra-low latency performance.
- Unmatched Inference Speed: Achieves industry-leading speeds, often measured in hundreds of tokens per second, enabling real-time interactions with large models.
- GroqCloud™ Platform: A fully managed, scalable cloud service that provides API access to the LPU-powered infrastructure.
- Broad Open-Source Model Support: Offers a curated selection of top-tier LLMs (Llama, Mistral, Qwen), ASR models (Whisper), and TTS models.
- Cost-Effective Pricing: A highly competitive pay-as-you-go pricing model based on tokens, characters, or time, designed to offer the lowest cost per token without sacrificing performance.
- Batch API: An asynchronous API for processing large workloads at a significant discount, ideal for offline data processing and analysis.
- Scalability and Consistency: The architecture ensures that performance remains consistent and fast, even as traffic and workloads scale.
- Developer-Friendly API: A simple, easy-to-integrate API that is largely compatible with existing standards, making it easy to switch and build.
Use Cases for Groq
The extreme speed of Groq's LPU opens up a wide range of applications that require real-time AI responses:
- Conversational AI & Chatbots: Building highly responsive customer service bots, virtual assistants, and interactive companions that can understand and reply instantly.
- Content Creation: Generating blog posts, social media content, marketing copy, and even entire books in seconds.
- Real-Time Transcription & Summarization: Transcribing audio from meetings or live events and generating summaries on the fly.
- Voice-Controlled Applications: Powering voice-activated UIs, drafting emails via dictation, and controlling software with voice commands.
- Interactive Learning Tools: Creating dynamic, personalized lesson plans and educational journeys that adapt to user input in real time.
- Financial Analysis: Developing AI agents that can provide live stock chart analysis, financial news summaries, and market screening.
- Code Generation & Assistance: Providing developers with instant code suggestions, debugging help, and explanations.
Advantages of Groq
Groq's primary advantage lies in its purpose-built hardware, which translates into several key benefits for users:
- Blazing Speed: By eliminating the bottlenecks of traditional GPU architectures, Groq provides the fastest inference speeds on the market, which is critical for user-facing applications.
- Superior Price-Performance: The efficiency of the LPU allows Groq to offer its services at a lower cost per token, making powerful AI more economically viable for businesses of all sizes.
- Predictable Performance: Unlike some systems that slow down under heavy load, Groq's latency remains consistently low, ensuring a reliable user experience at any scale.
- Future-Proof Technology: As AI models grow larger and more complex, Groq's specialized architecture is designed to handle the next generation of AI workloads efficiently.
- Ease of Adoption: The developer-focused approach with a simple API ensures that teams can quickly integrate Groq's speed into their existing or new applications with minimal effort.
Pricing and Plans
Groq operates on a freemium and on-demand pricing model, making it accessible for individual developers and scalable for large enterprises.
- Free Tier: Users can sign up and start building for free to test the platform and its capabilities.
- Pay-As-You-Go: After the free tier, pricing is on-demand. For Large Language Models (LLMs), costs are calculated per million tokens, with different rates for input and output tokens. For example, a fast model like Llama 3 8B is priced at approximately $0.05 per million input tokens and $0.08 per million output tokens.
- ASR & TTS Pricing: Automatic Speech Recognition (ASR) models like Whisper are priced per hour of transcribed audio (e.g., around $0.02-$0.11/hour). Text-to-Speech (TTS) models are priced per million characters.
- Batch API Discount: Using the Batch API for large, asynchronous jobs provides a 50% discount on standard on-demand rates.
- Enterprise Solutions: Custom pricing and deployment options, including on-premise solutions, are available for enterprise customers upon request.
Groq Comments (0)
Log in to post comments
Log in nowGroqWebsite Traffic Analysis
Latest Traffic
Status
Monthly Traffic Trend
Geography
Top 5 Countries/Regions
-
🇮🇳 India46.80%
-
🇺🇸 United States25.05%
-
🇧🇷 Brazil14.86%
-
🇵🇰 Pakistan6.67%
-
🇮🇩 Indonesia6.62%
Traffic source
| Source Type | Percentage |
|---|---|
|
Direct Access
|
77.78% |
|
Referral
|
20.42% |
|
Email
|
1.80% |
Popular Keywords
| Keyword | Cost Per Click |
|---|---|
|
$1.75
|
|
|
$1.72
|
|
|
$2.67
|
|
|
$1.49
|
|
|
$1.80
|
Groq Alternatives
View All
OpenAI
OpenAI is a leading AI research and deployment company dedicated to ensuring that artificial general intelligence (AGI) benefits …
OpenAI is a leading AI research and deployment company dedicated to ensuring that artificial general intelligence (AGI) benefits all of humanity. It develops state-of-the-art models like GPT-5, ChatGPT for conversational AI, Sora for text-to-video, and DALL-E for image generation. Through its robust API platform, OpenAI empowers developers and businesses to integrate powerful AI capabilities into their applications, driving innovation across various industries.
TextSynth
TextSynth offers developers powerful, cost-effective access to a suite of AI models, including large language models (LLMs), text-to-image, …
TextSynth offers developers powerful, cost-effective access to a suite of AI models, including large language models (LLMs), text-to-image, text-to-speech, and speech-to-text, through a flexible REST API and an interactive playground. It features models like Llama, Mistral, Stable Diffusion, and Whisper, optimized for speed and affordability.

Inception Labs
Inception Labs introduces a new generation of Diffusion Large Language Models (dLLMs) that are up to 10x faster …
Inception Labs introduces a new generation of Diffusion Large Language Models (dLLMs) that are up to 10x faster and cheaper than traditional models. Leveraging a parallel, diffusion-based approach, it offers unprecedented speed, quality, and control for text and code generation, ideal for enterprise-grade applications.
fal.ai
A generative media platform for developers, providing lightning-fast APIs for running and fine-tuning advanced AI models for images, …
A generative media platform for developers, providing lightning-fast APIs for running and fine-tuning advanced AI models for images, video, and 3D. Access state-of-the-art models with up to 4x faster inference speeds.

Ollama
Ollama is a powerful open-source framework for running large language models (LLMs) like Llama 3, Mistral, and Gemma …
Ollama is a powerful open-source framework for running large language models (LLMs) like Llama 3, Mistral, and Gemma locally on your own hardware. Available for macOS, Windows, and Linux, it simplifies the setup and management of open-source models, enabling private, offline, and cost-effective AI development and usage.
SiliconFlow
SiliconFlow is a unified AI infrastructure platform designed for high-performance inference of Large Language Models (LLMs) and multimodal …
SiliconFlow is a unified AI infrastructure platform designed for high-performance inference of Large Language Models (LLMs) and multimodal models. It provides developers and enterprises with scalable, cost-effective, and flexible deployment options, including serverless APIs, reserved GPUs, and fine-tuning capabilities, all accessible through a single, OpenAI-compatible API.
Outspeed
An API and SDK for developers to build and deploy AI voice companions with real-time emotion and memory. …
An API and SDK for developers to build and deploy AI voice companions with real-time emotion and memory. Easily integrate natural, low-latency voice interactions into web and mobile applications.
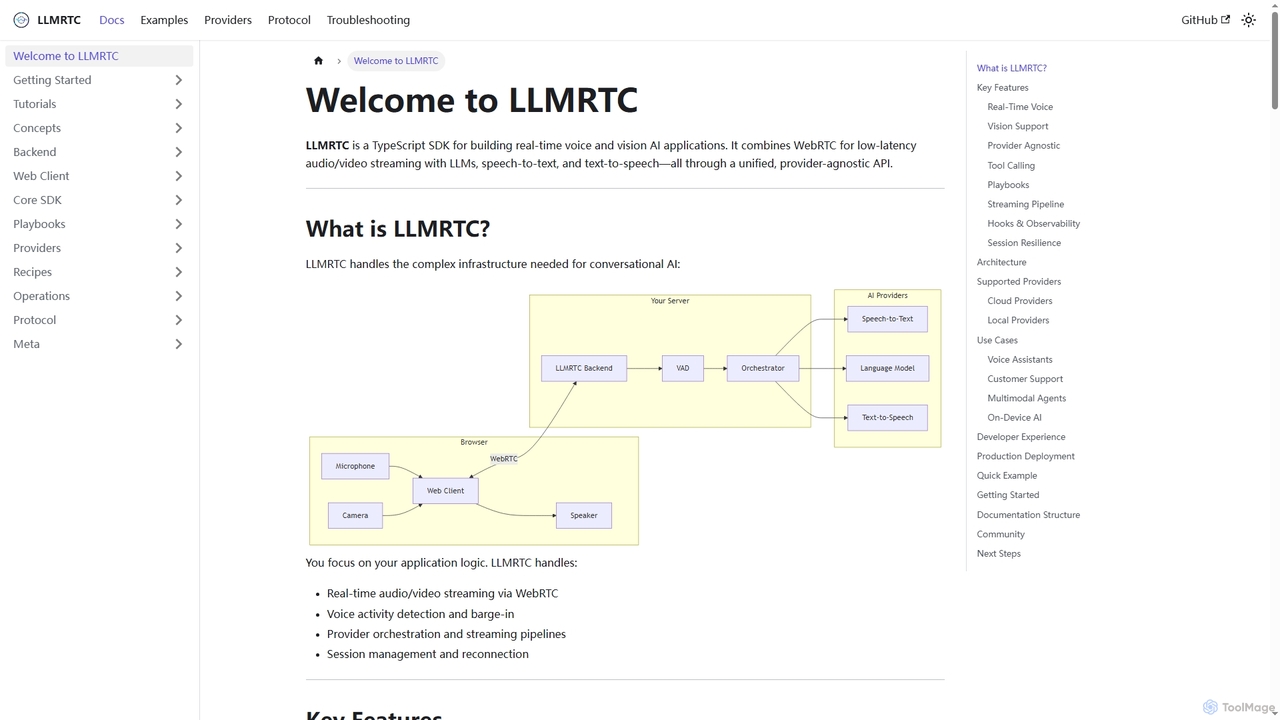
LLMRTC
LLMRTC is a TypeScript SDK for building real-time voice and vision AI applications. It integrates WebRTC for low-latency …
LLMRTC is a TypeScript SDK for building real-time voice and vision AI applications. It integrates WebRTC for low-latency audio/video streaming with LLMs, speech-to-text, and text-to-speech technologies through a unified, provider-agnostic API. Developers can focus on application logic while LLMRTC handles complex conversational AI infrastructure.

InternAI (Shusheng)
InternAI (Shusheng) is a comprehensive suite of open-source, high-performance foundation models developed by Shanghai AI Laboratory. It covers …
InternAI (Shusheng) is a comprehensive suite of open-source, high-performance foundation models developed by Shanghai AI Laboratory. It covers language, multimodality, weather forecasting, aerospace design, 3D modeling, finance, and scientific research, aiming to empower global innovation.
ComfyOnline
A cloud-based platform for running ComfyUI workflows online without expensive hardware. It offers a serverless environment, one-click API …
A cloud-based platform for running ComfyUI workflows online without expensive hardware. It offers a serverless environment, one-click API deployment for AI applications, and pay-as-you-go access to high-performance GPUs like H100 and A100. It simplifies the entire process from workflow creation to scalable deployment.
Groq Category
Groq Tag
Groq AI Tool Comparison
Groq Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!