Neosync
Neosync is an open-source platform for data anonymization and synthetic data generation. It helps developers and data scientists …
Neosync is an open-source platform for data anonymization and synthetic data generation. It helps developers and data scientists create safe, privacy-compliant, and realistic datasets for testing, development, and AI model training, ensuring referential integrity across databases.
ezML
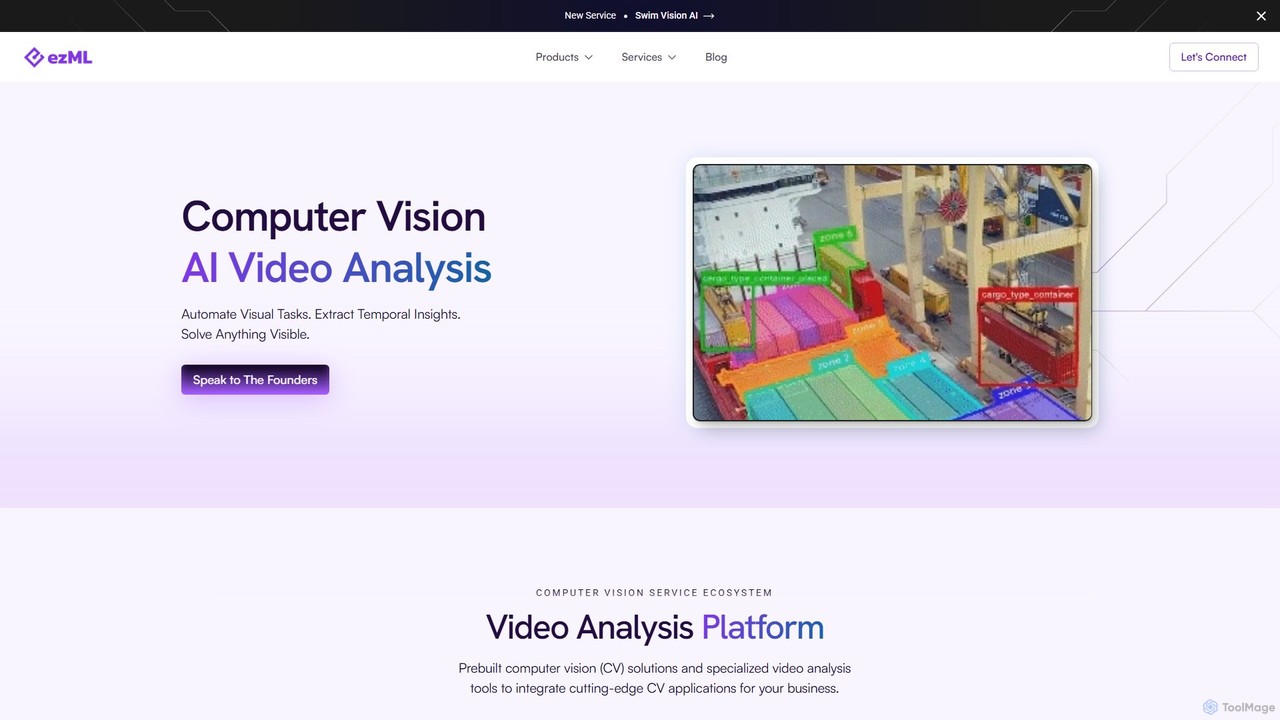
ezML is an enterprise-grade computer vision platform specializing in advanced video analysis. It offers a suite of tools …
ezML is an enterprise-grade computer vision platform specializing in advanced video analysis. It offers a suite of tools including pre-built models, multi-modal search, synthetic data generation, and custom CV solutions. With a strong focus on sports analytics, like its Swim Vision AI, ezML helps businesses automate visual tasks, extract deep insights from video data, and deploy high-performance, scalable CV applications.
About Data Generation
Data Generation tools are AI-powered solutions that create new, synthetic datasets. These tools leverage advanced algorithms, often including generative adversarial networks (GANs) or variational autoencoders (VAEs), to produce data that mirrors the statistical properties and patterns of real-world data. They are crucial for addressing data scarcity, enhancing privacy, and generating diverse, unbiased datasets for machine learning model training and testing. By simulating complex data distributions, they enable robust development without relying solely on sensitive or limited real data.
Core Features
- Synthetic Data Creation: Generate realistic, statistically similar data points across various modalities like images, text, or tabular data.
- Privacy Preservation: Create data that retains analytical utility while anonymizing or protecting sensitive information.
- Data Augmentation: Expand existing datasets with diverse variations to improve model robustness and generalization.
- Bias Mitigation: Generate balanced datasets to reduce inherent biases present in real-world data, leading to fairer AI models.
- Customizable Parameters: Offer controls to specify data characteristics, volume, distribution, and specific scenarios for generation.
Applicable Scenarios
Data Generation tools are widely adopted by machine learning engineers, data scientists, and software testers. They are essential for training robust AI models in data-scarce domains, creating realistic test data for applications without compromising privacy, and producing anonymized datasets for compliance in regulated industries like healthcare and finance.
How to Choose
When selecting a Data Generation tool, consider the required data type and fidelity, ensuring it can produce data with sufficient realism for your use case. Evaluate its privacy and security features for sensitive information, and assess its scalability and performance for generating large data volumes efficiently. Finally, check for customization options to control data characteristics and specific scenarios.
Data GenerationUse Cases
Generate Synthetic Image Data for AI Model Training
Machine learning engineers require vast amounts of diverse image data to train computer vision models, but real data collection is costly and often privacy-restricted. Data generation tools can automatically create millions of synthetic images with varying backgrounds, lighting, poses, and features based on a small set of real images or specific descriptions. This not only solves data scarcity but also enhances model generalization and robustness in real-world applications by introducing diversity, significantly accelerating the model development cycle.
Create Privacy-Compliant Customer Transaction Test Data
Financial institutions need vast amounts of customer transaction data for functional and performance testing when developing new products or systems. However, using real customer data poses strict privacy compliance risks. Data generation tools can produce completely anonymous synthetic transaction data with the same structure and characteristics as existing transaction data, based on its statistical patterns. This allows development teams to conduct comprehensive testing in a secure and compliant environment, avoiding data leakage risks while ensuring testing effectiveness.
Automate Generation of User Behavior Data for Software Testing
Software testers need to simulate various user interaction behaviors within an application for user interface (UI) and user experience (UX) testing. Manually creating these complex behavior paths is time-consuming and often fails to cover all edge cases. Data generation tools can automatically produce synthetic data simulating a series of user actions like clicks, inputs, and navigation, based on preset user behavior patterns or historical logs. This significantly increases test coverage and efficiency, helping to uncover potential bugs and performance bottlenecks.
Expand Low-Resource Text Datasets to Improve NLP Model Performance
Natural Language Processing (NLP) models often face insufficient data in low-resource languages or specific domains (e.g., legal, medical), leading to poor model performance. Content creators or AI researchers can leverage data generation tools to produce large volumes of grammatically correct, semantically coherent synthetic text data based on a small amount of seed text and linguistic rules. This data can be used to pre-train or fine-tune NLP models, effectively mitigating data scarcity and significantly improving the accuracy of tasks like translation, sentiment analysis, and Q&A systems in low-resource language environments.
Generate Diverse Sensor Simulation Data for Autonomous Driving Systems
The development of autonomous vehicles requires massive amounts of sensor data (e.g., radar, lidar, cameras) to train perception and decision-making models. Real-world data collection is extremely costly and struggles to cover all extreme or rare scenarios. Data generation tools can simulate complex traffic environments, weather conditions, and obstacles, producing realistic synthetic sensor data. This enables engineers to safely and efficiently test and validate autonomous driving algorithms in virtual environments, accelerating technological iteration and enhancing safety.
Fill Missing Data or Balance Datasets to Reduce Model Bias
Many real-world datasets suffer from missing data or class imbalance, which can lead to biased or underperforming AI models. Data analysts and data scientists can use data generation tools to intelligently fill missing values or generate synthetic data for minority classes based on existing data distribution patterns. By creating more complete and balanced datasets, these tools effectively reduce bias in model training and improve the fairness and predictive accuracy of models, especially crucial in fields like medical diagnosis or financial risk assessment.