Confident AI
Visit Website
Confident AI Overview
Confident AI is a comprehensive LLM Evaluation and Observability Platform, developed by the creators of the popular open-source library DeepEval and backed by Y Combinator. It is specifically designed for engineering teams to systematically benchmark, safeguard, and enhance their Large Language Model (LLM) applications. The platform provides an end-to-end solution for managing the entire LLM lifecycle, from development and testing to production monitoring, ensuring that AI systems are reliable, cost-effective, and continuously improving.
By integrating best-in-class metrics and advanced tracing capabilities, Confident AI empowers teams to move beyond anecdotal evidence and make data-driven decisions. It helps prevent performance regressions, optimize prompts and models, and provides clear, actionable insights for both technical and non-technical stakeholders. The platform is trusted by leading companies and has a strong open-source community, performing hundreds of thousands of evaluations daily.
How to use Confident AI
Setting up and using Confident AI is a streamlined, developer-first process that can be completed in minutes:
- Install DeepEval: The first step is to install the open-source DeepEval library into your existing development environment, regardless of the framework you are using. The command is a simple `pip install deepeval`.
- Choose Metrics: Select from over 30 pre-built, LLM-as-a-judge metrics tailored to your specific use case, such as RAG evaluation, summarization, or answer relevancy. You can also create custom metrics to fit unique requirements.
- Plug It In: Integrate evaluations directly into your code by using a simple decorator (`@observe`) on your LLM application function. This allows you to apply your chosen metrics and configure test cases programmatically.
- Run an Evaluation: Execute your evaluation script to generate detailed test reports. These reports help you catch regressions in your CI/CD pipeline, and you can use the integrated tracing observability to dissect and debug individual components of your LLM pipeline, pinpointing weaknesses and areas for improvement.
Core Features of Confident AI
- End-to-End Evaluation: Measure and compare the performance of different prompts, models, and configurations to identify the optimal setup for your application.
- Regression Testing: Implement automated unit tests in your CI/CD pipelines to mitigate LLM regressions, ensuring that new changes don't break existing functionality and allowing for confident deployments.
- Component-Level Evaluation with Tracing: Dissect your LLM pipeline into individual components (e.g., retrieval, generation) and apply tailored metrics to each. Tracing provides deep visibility to debug and iterate effectively.
- DeepEval Integration: Built on the robust and widely adopted DeepEval open-source library, offering a familiar and powerful foundation for developers.
- Dataset and Prompt Management: Includes a cloud-based dataset editor for curating and annotating evaluation datasets, as well as tools for versioning and managing prompts.
- Enterprise-Grade Security & Compliance: Offers HIPAA and SOC2 compliance, multi-data residency options (US and EU), role-based access control (RBAC), data masking, and options for on-premise hosting.
- No-Code Prompt Playground: An intuitive interface for non-technical team members to experiment with and evaluate prompts without writing code.
Use Cases for Confident AI
Confident AI is versatile and supports a wide range of LLM applications, including:
- Retrieval-Augmented Generation (RAG) Systems: Evaluate the quality of retrieved context, the faithfulness of the generated answer to the context, and overall answer relevancy.
- LLM Chatbots & Virtual Assistants: Test for conversational quality, task completion, safety, and consistency across multi-turn dialogues.
- LLM Agents: Assess agentic reasoning, tool usage, and the ability to complete complex, multi-step tasks.
- Cost Optimization: By comparing different models and prompts, teams can identify configurations that meet performance requirements while cutting inference costs by up to 80%.
- Stakeholder Alignment: Generate clear, shareable reports that demonstrate AI performance improvements over time, convincing stakeholders and justifying product decisions.
Advantages of Confident AI
The platform offers significant advantages for teams building with LLMs:
- Time and Cost Savings: Automates the tedious process of manual evaluation, saving teams hundreds of hours per week and reducing unnecessary inference costs.
- Increased Confidence: Enables teams to deploy changes, even on Fridays, with the confidence that regressions will be caught automatically.
- Developer-Friendly & Team-Accessible: While built for developers with code-first integration, its intuitive dashboards and no-code tools make insights accessible to product managers and other team members.
- Trusted & Open-Source: Leverages the credibility and active community of DeepEval, ensuring a reliable and continuously improving evaluation framework.
- Secure & Scalable: Provides enterprise-ready features for security, compliance, and scalability, including on-premise deployment for maximum data control.
Pricing and Plans
Confident AI offers a tiered pricing structure to scale with your needs:
- Free: A forever-free plan for individuals exploring the platform. It includes DeepEval testing reports, LLM tracing, and prompt versioning, limited to 1 project, 5 test runs per week, and 1-week data retention.
- Starter (from $19.99/user/month): Designed for teams proving ROI. Includes everything in Free, plus a full unit/regression testing suite, custom metrics, human-in-the-loop feedback, and email support. Starts with 20k LLM traces/month and 1-month data retention.
- Premium (from $139.99/user/month): For teams shipping mission-critical products. Includes everything in Starter, plus online performance alerting, dataset revision history, multi-turn simulation, a no-code prompt playground, and a dedicated support channel. Starts with 75k LLM traces/month and 6-months data retention.
- Enterprise (Custom Pricing): For high-scale, security, and compliance needs. Includes everything in Premium plus unlimited users, projects, and traces, on-prem deployment, SSO, SOC2, dedicated 24/7 support, and custom integrations.
Confident AI Comments (0)
Log in to post comments
Log in nowConfident AIWebsite Traffic Analysis
Latest Traffic
Status
Monthly Traffic Trend
Geography
Top 5 Countries/Regions
-
🇮🇳 India30.95%
-
🇺🇸 United States23.35%
-
🇵🇹 Portugal19.66%
-
🇬🇭 Ghana13.88%
-
🇬🇧 United Kingdom12.16%
Traffic source
| Source Type | Percentage |
|---|---|
|
Direct Access
|
80.70% |
|
Referral
|
18.67% |
|
Email
|
0.63% |
Popular Keywords
| Keyword | Cost Per Click |
|---|---|
|
$5.23
|
|
|
$4.67
|
|
|
$2.23
|
|
|
$2.45
|
|
|
$3.09
|
Confident AI Alternatives
View All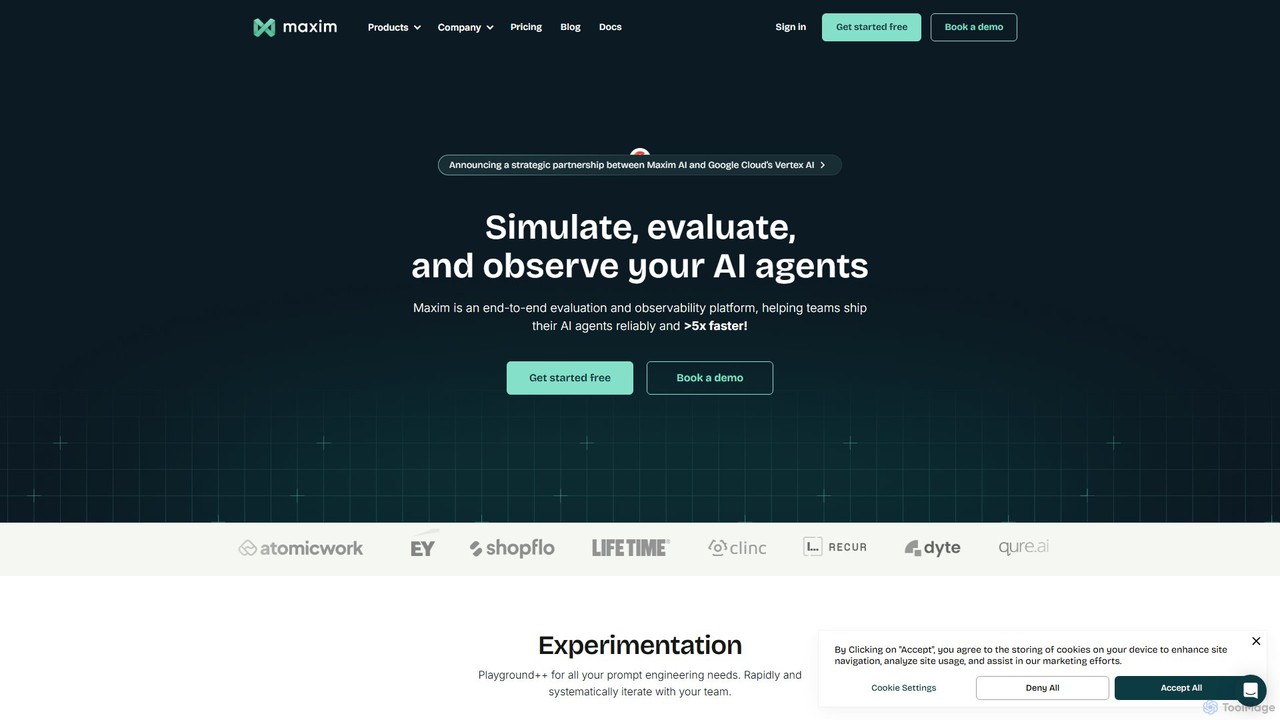
getmaxim
getmaxim is a comprehensive GenAI evaluation and observability platform designed for AI development teams. It enables users to …
getmaxim is a comprehensive GenAI evaluation and observability platform designed for AI development teams. It enables users to test, monitor, and improve AI applications by running extensive evaluations on LLMs and RAG pipelines, automating testing, and providing real-time production monitoring to ensure high-quality, reliable, and responsible AI.

LangWatch
LangWatch is an all-in-one, open-source platform for monitoring, evaluating, and optimizing LLM applications. It specializes in AI agent …
LangWatch is an all-in-one, open-source platform for monitoring, evaluating, and optimizing LLM applications. It specializes in AI agent testing through simulated user environments, helping teams catch regressions and edge cases before production. The platform combines observability, evaluation, optimization, and guardrails to ensure AI applications are reliable, secure, and performant.
Openlayer
Openlayer is an enterprise-grade platform for AI evaluation and observability. It empowers teams to test, monitor, and govern …
Openlayer is an enterprise-grade platform for AI evaluation and observability. It empowers teams to test, monitor, and govern both traditional machine learning models and large language models (LLMs) throughout their entire lifecycle, from development to production, ensuring reliability and compliance.
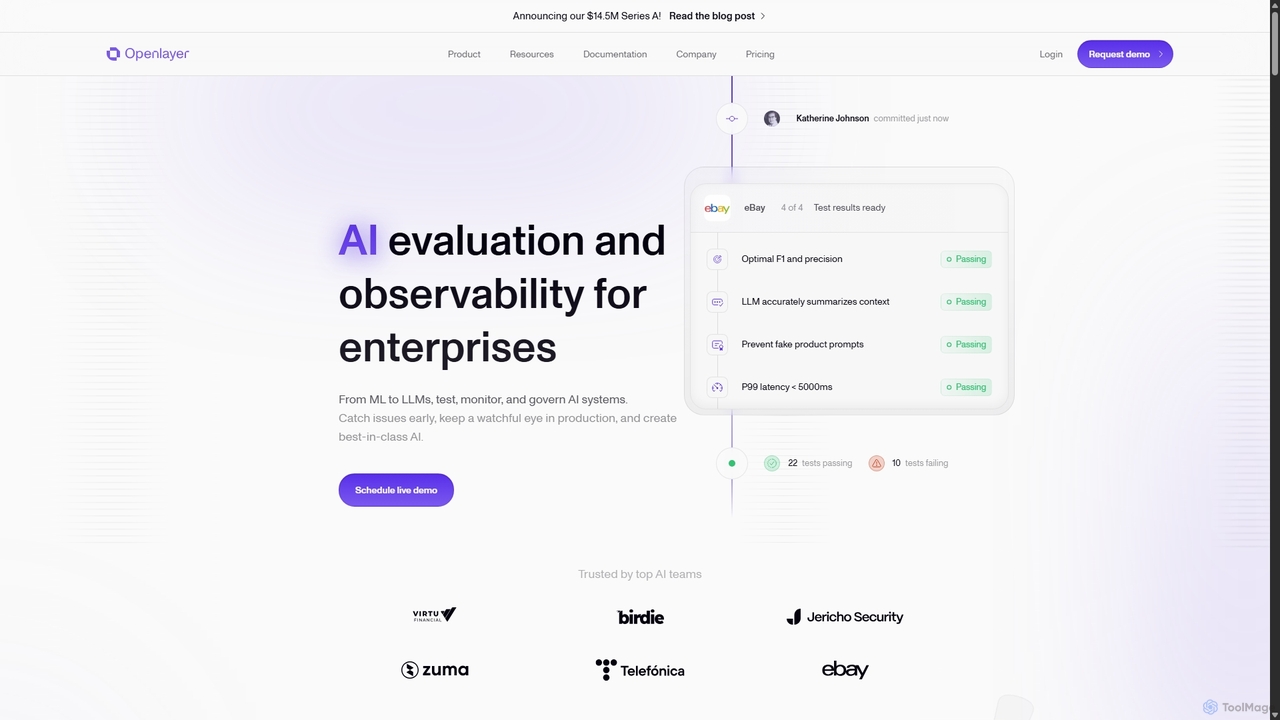
Evidently AI
Evidently AI is a comprehensive testing and evaluation platform for AI products, specializing in LLM and ML model …
Evidently AI is a comprehensive testing and evaluation platform for AI products, specializing in LLM and ML model monitoring. It helps teams ensure AI safety, reliability, and performance through automated evaluation, synthetic data generation, continuous testing, and adversarial attacks. Built on a powerful open-source library, it's designed for data scientists and MLOps engineers to detect issues like hallucinations, data drift, and PII leaks before they impact users.
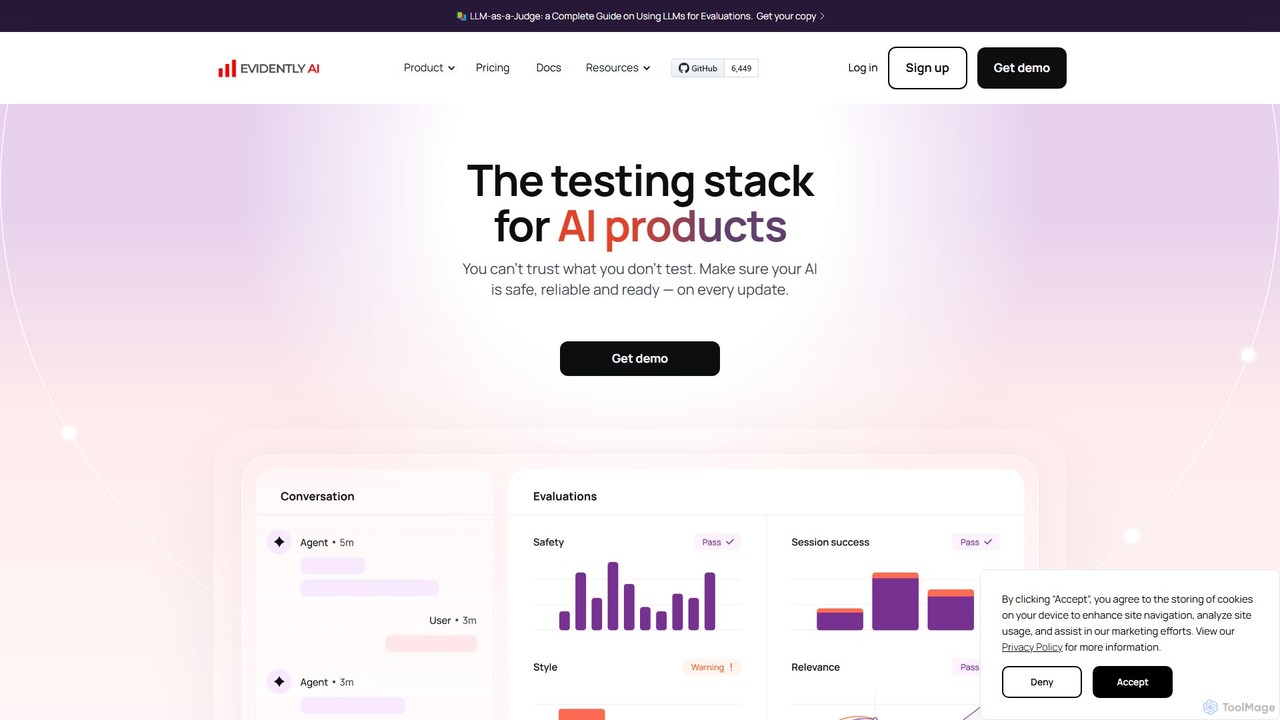
Keywords AI
Keywords AI is a comprehensive LLM observability and monitoring platform designed for AI startups and developers. It provides …
Keywords AI is a comprehensive LLM observability and monitoring platform designed for AI startups and developers. It provides a unified API to deploy, test, monitor, and optimize LLM workflows, supporting over 200 models with a simple, two-line integration to help teams build and ship reliable AI features faster.

mabl
mabl is an AI-powered test automation platform that simplifies end-to-end testing for web applications. It uses AI to …
mabl is an AI-powered test automation platform that simplifies end-to-end testing for web applications. It uses AI to accelerate test creation, execution, and maintenance, enabling agile and DevOps teams to deliver high-quality software faster. With features like self-healing tests and AI-driven root cause analysis, mabl reduces the effort of maintaining brittle test suites.
EvalsOne
EvalsOne is an all-in-one evaluation platform designed for generative AI applications. It empowers teams to effortlessly assess, iterate, …
EvalsOne is an all-in-one evaluation platform designed for generative AI applications. It empowers teams to effortlessly assess, iterate, and optimize LLM prompts, RAG pipelines, and AI agents through a powerful, intuitive interface, ensuring robust and competitive AI products.
Arize
Arize is an AI & Agent Engineering Platform designed for development, observability, and evaluation. It provides a unified …
Arize is an AI & Agent Engineering Platform designed for development, observability, and evaluation. It provides a unified solution for teams to build, monitor, debug, and improve LLM and ML models faster. By closing the loop between development and production, Arize helps ensure AI systems are reliable, trustworthy, and high-performing at scale.
Testsigma
Testsigma is a unified, AI-powered test automation platform that enables teams to create, run, and maintain tests for …
Testsigma is a unified, AI-powered test automation platform that enables teams to create, run, and maintain tests for web, mobile, API, and ERP applications without code. It uses AI agents to accelerate test generation, reduce maintenance by 90%, and achieve end-to-end testing on a massive scale.
HoneyHive
HoneyHive is an all-in-one AI observability and evaluation platform for developers building with LLMs and AI agents. It …
HoneyHive is an all-in-one AI observability and evaluation platform for developers building with LLMs and AI agents. It provides a unified solution to build, test, debug, and monitor AI applications, from initial experiments to enterprise-scale deployment. The platform helps teams systematically measure AI quality, gain deep visibility into agent interactions, monitor performance metrics like cost and latency, and collaborate on essential assets like prompts and datasets, ensuring the confident shipment of reliable AI products.
Confident AI Category
Confident AI Tag
Confident AI AI Tool Comparison
Confident AI Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!