
EvalsOne Overview
EvalsOne is a comprehensive, one-stop evaluation platform engineered to streamline the optimization of generative AI applications. It acts as a 'Swiss army knife' for developers, AI engineers, and product teams, providing a robust suite of tools to tackle the inherent instability of AI models and gain a competitive edge. The platform is designed to simplify the entire evaluation workflow, from data preparation to final analysis, making it accessible for all team members regardless of their technical role.
By offering a unified environment for testing and refinement, EvalsOne helps you overcome the challenges of developing reliable AI products. It supports a wide array of evaluation scenarios, ensuring that whether you are fine-tuning a simple prompt or assessing a complex AI agent, you have the right tools at your disposal. The platform's focus on collaboration, integration, and extensibility makes it a central hub for your entire AI development lifecycle.
How to use EvalsOne
EvalsOne features an intuitive, guided workflow that simplifies the evaluation process:
- Prepare Evaluation Data: Start by preparing your sample data. You can synthesize datasets using templates and variable lists, import existing OpenAI Evals sample sets, or even use the platform's LLM capabilities to intelligently expand your test cases.
- Create an Evaluation Run: Use the guided interface to easily set up and organize your evaluation runs. You can create multiple template versions to compare and optimize prompts side-by-side.
- Configure Models and Metrics: Integrate with a wide range of LLM providers like OpenAI, Claude, and Gemini, or connect to cloud containers (Azure, Bedrock) and local models (via Ollama or API). Select from over 10 pre-set evaluation metrics or create custom ones tailored to your specific needs.
- Execute and Iterate: Run your evaluation. The unique 'Fork run' feature allows for rapid iteration and in-depth analysis, enabling you to quickly test variations and pinpoint improvements.
- Analyze Results: Review the clear and intuitive evaluation reports. The results are presented in an easy-to-understand format, complete with justifications for each assessment, allowing your team to make data-driven decisions.
- Collaborate and Optimize: Share the findings with your team. The platform's collaborative features ensure everyone is aligned, facilitating a continuous cycle of optimization for your generative AI project.
Core Features of EvalsOne
- Versatile Evaluation Targets: Capable of evaluating LLM prompts, Retrieval-Augmented Generation (RAG) pipelines, and complex AI agents.
- Hybrid Evaluation Methods: Seamlessly combines automated evaluation using rules or LLMs with manual human assessment to leverage expert judgment.
- Streamlined Workflow: An intuitive UI with guided setup, 'Fork run' for rapid iteration, and template versioning for easy prompt comparison.
- Flexible Data Preparation: Multiple ways to create evaluation samples, including data synthesis, importing standard datasets, and LLM-powered data expansion.
- Comprehensive Model Integration: Supports major LLM providers (OpenAI, Claude, Gemini), cloud platforms (Azure, Bedrock, Hugging Face), local models (Ollama), and agent orchestration tools (Coze, FastGPT, Dify).
- Extensible Metrics Framework: Comes with 10+ out-of-the-box metrics and allows for the creation of custom metrics using templates to fit unique scenarios. Provides not just scores but also the reasoning behind them.
- Collaborative Environment: Designed for team-based projects, allowing members with different roles to participate in the optimization process.
Use Cases for EvalsOne
EvalsOne is ideal for teams working on various generative AI projects:
- Prompt Engineering: Systematically test and compare different versions of prompts to find the most effective, reliable, and safe wording.
- RAG System Optimization: Evaluate the end-to-end performance of your RAG pipeline, from retrieval accuracy to the quality of the generated answer.
- AI Agent Assessment: Test the behavior and decision-making capabilities of AI agents across a range of scenarios to ensure they perform as expected.
- Model Comparison: Run the same test suite across different LLMs (e.g., GPT-4 vs. Claude 3) to benchmark performance and select the best model for your application.
- Regression Testing: Create a standardized set of evaluations to run automatically after every update to your AI application, preventing performance degradation.
Advantages of EvalsOne
EvalsOne offers a significant competitive advantage by simplifying complexity and fostering quality. Its main strengths include its all-in-one nature, which eliminates the need for multiple disparate tools. The platform's flexibility in integrating with virtually any model—cloud or local—ensures it fits into any existing tech stack. Furthermore, the blend of automated and manual evaluation provides a holistic view of performance, combining scalable, objective metrics with nuanced human insight. The focus on a smooth, collaborative workflow empowers the entire team to contribute to building better AI products faster.
Pricing and Plans
EvalsOne's pricing information is available upon request. Prospective users are encouraged to 'Book a Demo' through the official website to receive a personalized walkthrough from one of the founders. This approach suggests custom enterprise plans tailored to the specific needs, scale, and integration requirements of your team or organization.
EvalsOne Comments (0)
Log in to post comments
Log in nowEvalsOneWebsite Traffic Analysis
Latest Traffic
Status
Monthly Traffic Trend
Geography
Top 5 Countries/Regions
-
🇺🇸 United States70.80%
-
🇮🇳 India29.20%
Popular Keywords
| Keyword | Cost Per Click |
|---|---|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
|
|
$0.00
|
EvalsOne Alternatives
View All
Basalt
Basalt is an end-to-end platform for developers and product teams to build, evaluate, and monitor reliable AI agents. …
Basalt is an end-to-end platform for developers and product teams to build, evaluate, and monitor reliable AI agents. It provides a comprehensive suite of tools, including automated evaluations, A/B testing, prompt engineering with an AI co-pilot, and a developer-friendly SDK to ensure your AI features are trustworthy and production-ready.
Confident AI
Confident AI is an LLM evaluation and observability platform for engineering teams. Built by the creators of the …
Confident AI is an LLM evaluation and observability platform for engineering teams. Built by the creators of the open-source DeepEval library, it helps benchmark, safeguard, and improve LLM applications through comprehensive metrics, regression testing, and detailed tracing to ensure consistent AI performance.

parseprompt.ai
ParsePrompt is an advanced platform for prompt engineering, designed for developers and AI teams. It allows you to …
ParsePrompt is an advanced platform for prompt engineering, designed for developers and AI teams. It allows you to parse, analyze, manage, and optimize your LLM prompts. Transform unstructured text prompts into structured, reusable templates, track versions, and collaborate effectively to build more reliable and cost-efficient AI applications.
nonfinito
nonfinito is a comprehensive platform for evaluating and comparing multimodal AI models. It enables developers, researchers, and businesses …
nonfinito is a comprehensive platform for evaluating and comparing multimodal AI models. It enables developers, researchers, and businesses to test various LLMs side-by-side on custom prompts, assess their performance with pass/fail ratings, and analyze raw outputs. Create public or private benchmarks to find the best model for any task.

Prompt Octopus
A VSCode extension for developers to streamline prompt engineering. It enables side-by-side comparison of responses from over 40 …
A VSCode extension for developers to streamline prompt engineering. It enables side-by-side comparison of responses from over 40 LLMs (like OpenAI, Anthropic, Mistral) directly within the codebase, helping you find the best model for any task efficiently.
Vellum AI
Vellum AI is an end-to-end enterprise platform for building, evaluating, and deploying mission-critical AI agents and applications. It …
Vellum AI is an end-to-end enterprise platform for building, evaluating, and deploying mission-critical AI agents and applications. It provides a unified environment for orchestration, prompt engineering, RAG, evaluation, and monitoring, enabling teams to build reliable AI solutions 10x faster.
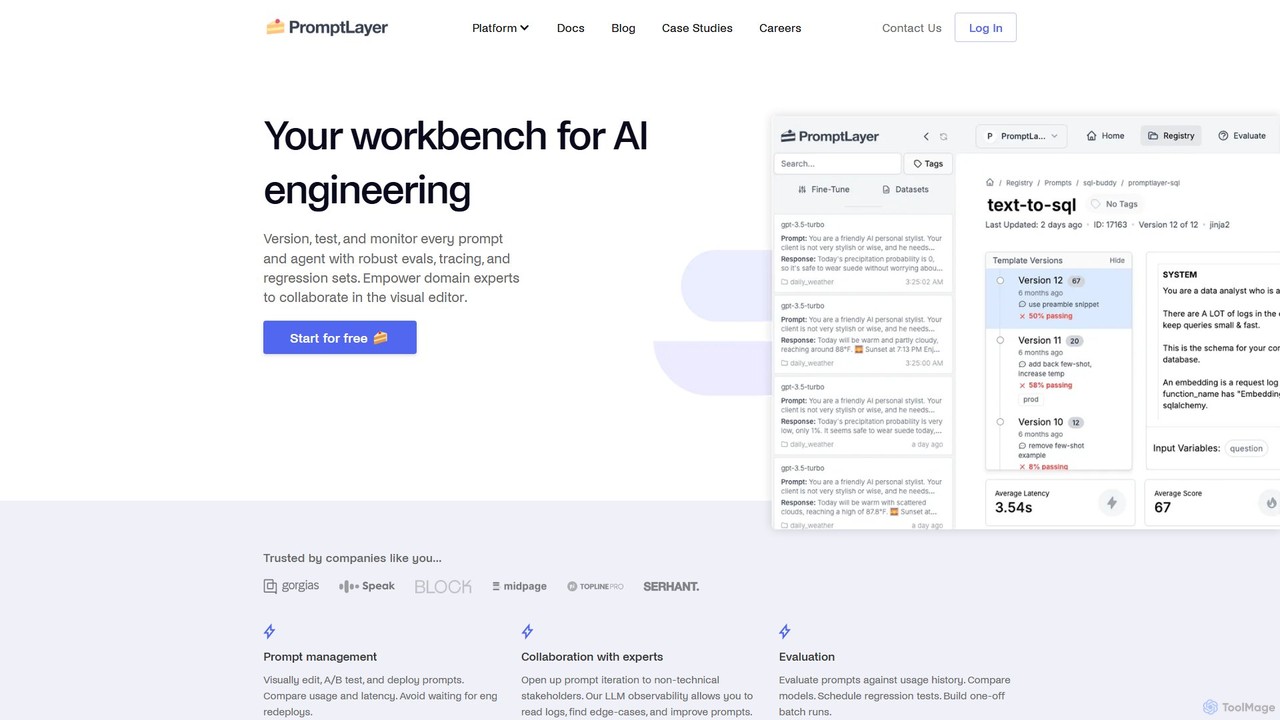
PromptLayer
PromptLayer is your comprehensive workbench for AI engineering, providing a unified platform for prompt management, evaluation, and LLM …
PromptLayer is your comprehensive workbench for AI engineering, providing a unified platform for prompt management, evaluation, and LLM observability. It empowers teams to version, test, and monitor every prompt and agent, fostering collaboration between technical and non-technical stakeholders to build and scale production-ready AI applications efficiently.
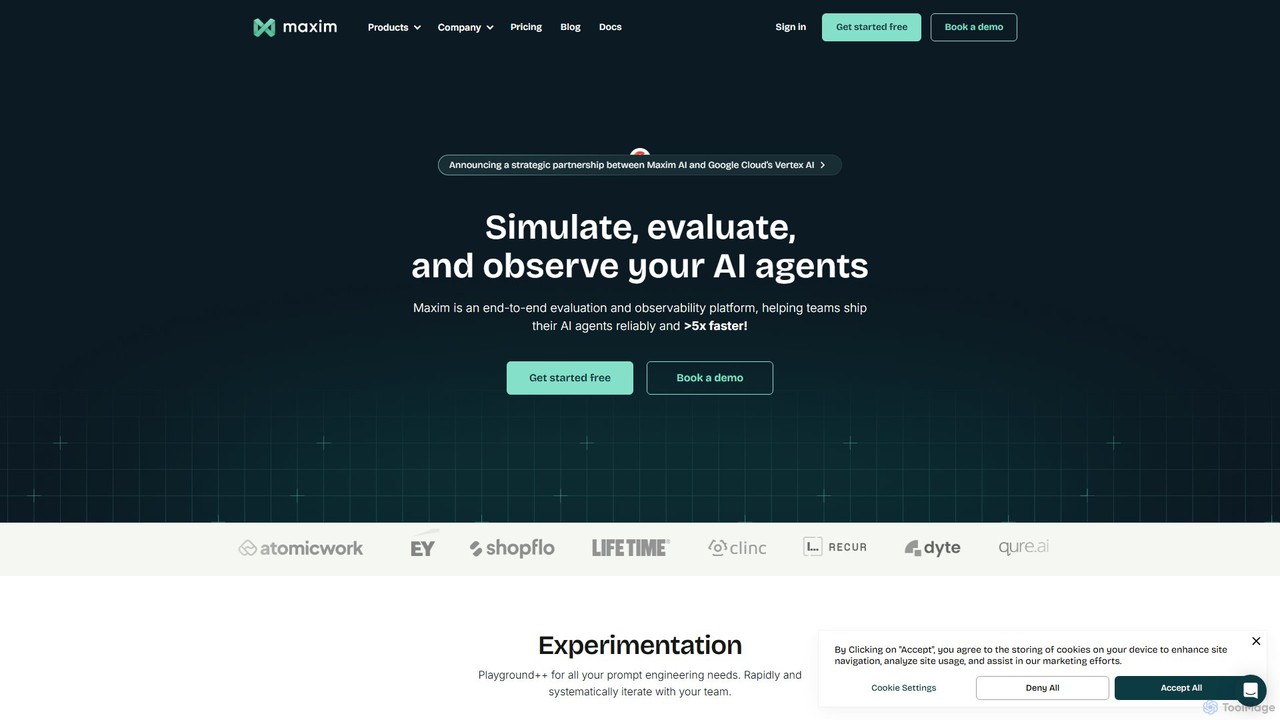
getmaxim
getmaxim is a comprehensive GenAI evaluation and observability platform designed for AI development teams. It enables users to …
getmaxim is a comprehensive GenAI evaluation and observability platform designed for AI development teams. It enables users to test, monitor, and improve AI applications by running extensive evaluations on LLMs and RAG pipelines, automating testing, and providing real-time production monitoring to ensure high-quality, reliable, and responsible AI.
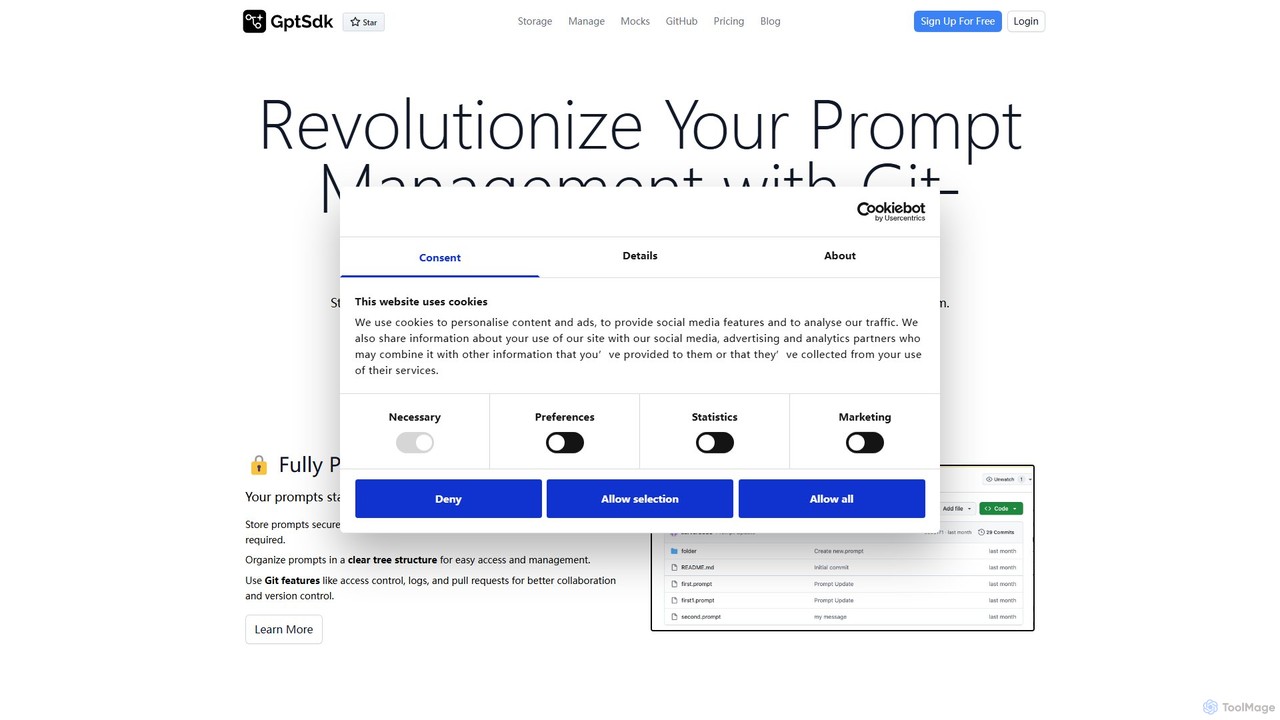
gpt_sdk
A developer-first platform for managing Large Language Model (LLM) prompts using Git-based version control. Streamline your prompt engineering …
A developer-first platform for managing Large Language Model (LLM) prompts using Git-based version control. Streamline your prompt engineering workflow, collaborate with your team, and deploy changes seamlessly without altering code.

PromptPilot
PromptPilot by Volcengine is an enterprise-grade platform for prompt engineering and management. It enables teams to create, test, …
PromptPilot by Volcengine is an enterprise-grade platform for prompt engineering and management. It enables teams to create, test, manage, and deploy LLM prompts with features like version control, A/B testing, performance analytics, and seamless collaboration. Streamline your AI application development by decoupling prompt logic from application code, ensuring consistency, and optimizing performance across various large language models.
EvalsOne Category
EvalsOne Tag
EvalsOne AI Tool Comparison
EvalsOne Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!