Plurai
Plurai is an AI Agent Trust Platform that accelerates the development of production-ready agents by providing simulation, evaluation, …
Plurai is an AI Agent Trust Platform that accelerates the development of production-ready agents by providing simulation, evaluation, and guardrails. It reduces failure rates, policy violations, and costs compared to large language models.
Agenta
Agenta is an open-source LLMOps platform designed for teams to build reliable LLM applications. It integrates prompt management, …
Agenta is an open-source LLMOps platform designed for teams to build reliable LLM applications. It integrates prompt management, systematic evaluation, and observability into a single, collaborative workflow, helping developers, product managers, and domain experts move from scattered processes to structured development.
Athina
Athina is a collaborative AI development platform designed to help teams build, test, and monitor LLM applications 10x …
Athina is a collaborative AI development platform designed to help teams build, test, and monitor LLM applications 10x faster. It provides a comprehensive suite of tools for prompt engineering, evaluation, experimentation, annotation, and production monitoring. Athina supports both technical and non-technical users, ensuring seamless collaboration and the deployment of high-quality, reliable AI systems.

LangWatch
LangWatch is an all-in-one, open-source platform for monitoring, evaluating, and optimizing LLM applications. It specializes in AI agent …
LangWatch is an all-in-one, open-source platform for monitoring, evaluating, and optimizing LLM applications. It specializes in AI agent testing through simulated user environments, helping teams catch regressions and edge cases before production. The platform combines observability, evaluation, optimization, and guardrails to ensure AI applications are reliable, secure, and performant.
deepchecks
Deepchecks is an end-to-end platform for evaluating, validating, and monitoring LLM-based applications. It helps AI teams define, measure, …
Deepchecks is an end-to-end platform for evaluating, validating, and monitoring LLM-based applications. It helps AI teams define, measure, and validate AI progress, ensuring the release of high-quality, reliable applications by streamlining testing from development through CI/CD to production.
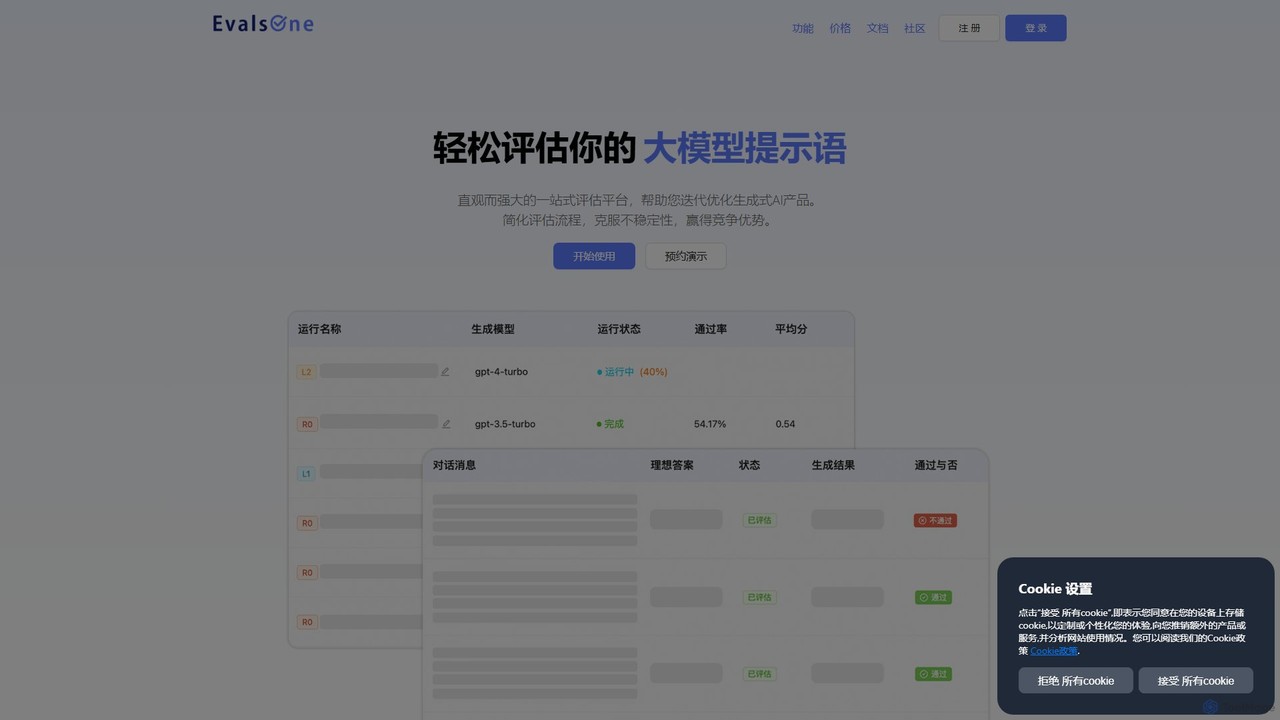
EvalsOne
EvalsOne is an all-in-one evaluation platform designed for generative AI applications. It empowers teams to effortlessly assess, iterate, …
EvalsOne is an all-in-one evaluation platform designed for generative AI applications. It empowers teams to effortlessly assess, iterate, and optimize LLM prompts, RAG pipelines, and AI agents through a powerful, intuitive interface, ensuring robust and competitive AI products.

Prompt Octopus
A VSCode extension for developers to streamline prompt engineering. It enables side-by-side comparison of responses from over 40 …
A VSCode extension for developers to streamline prompt engineering. It enables side-by-side comparison of responses from over 40 LLMs (like OpenAI, Anthropic, Mistral) directly within the codebase, helping you find the best model for any task efficiently.
usevelvet
Velvet is a developer gateway, now part of Arize AI, designed for analyzing, evaluating, and monitoring AI-powered features. …
Velvet is a developer gateway, now part of Arize AI, designed for analyzing, evaluating, and monitoring AI-powered features. It provides a comprehensive suite for AI observability, LLM tracing, and model performance management, helping developers build and perfect AI applications from development to production.

Ragas
Ragas is an open-source Python framework for evaluating and testing Retrieval-Augmented Generation (RAG) pipelines. It provides a suite …
Ragas is an open-source Python framework for evaluating and testing Retrieval-Augmented Generation (RAG) pipelines. It provides a suite of metrics to measure the performance of your LLM applications, from context retrieval to answer generation. Trusted by industry leaders like LangChain and LlamaIndex, Ragas helps developers build more robust, reliable, and accurate AI systems by identifying and mitigating issues like hallucinations and irrelevant responses.
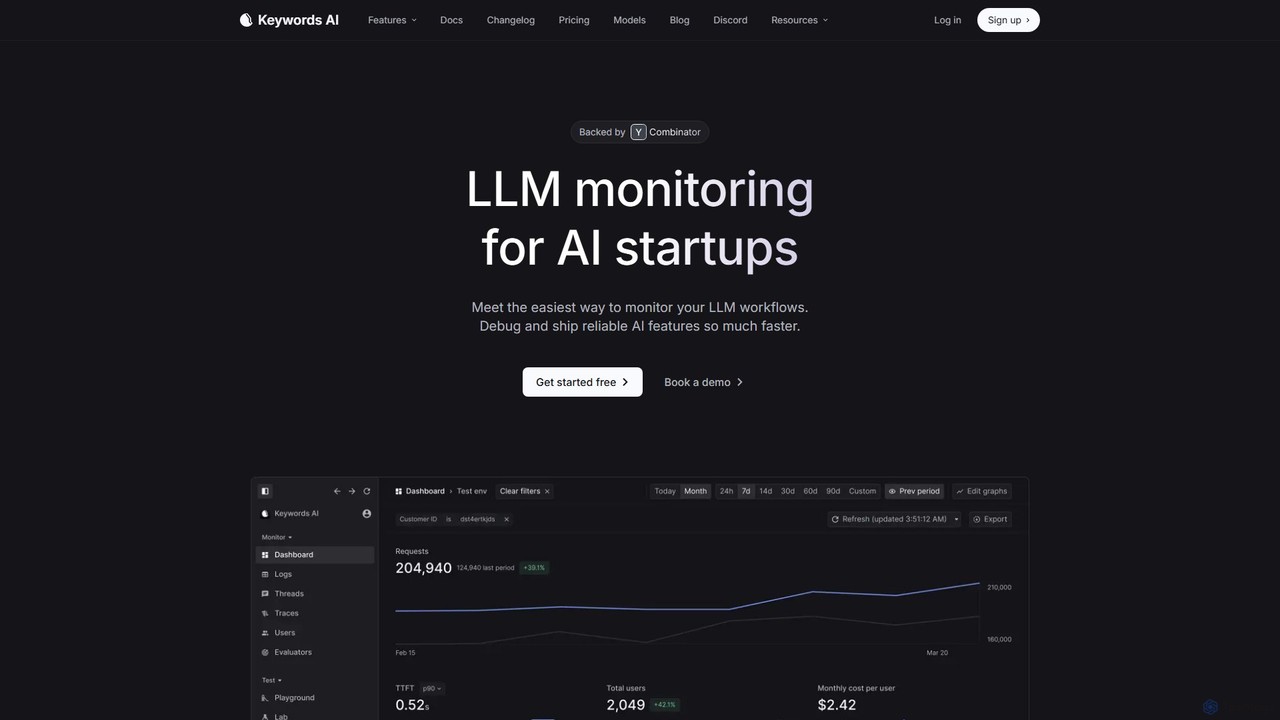
Keywords AI
Keywords AI is a comprehensive LLM observability and monitoring platform designed for AI startups and developers. It provides …
Keywords AI is a comprehensive LLM observability and monitoring platform designed for AI startups and developers. It provides a unified API to deploy, test, monitor, and optimize LLM workflows, supporting over 200 models with a simple, two-line integration to help teams build and ship reliable AI features faster.
withpi.ai
A developer-focused platform for creating tunable, fast, and cost-effective scoring and evaluation systems for AI applications. It transforms …
A developer-focused platform for creating tunable, fast, and cost-effective scoring and evaluation systems for AI applications. It transforms qualitative criteria into precise, quantitative metrics for model monitoring, ranking, and RAG optimization.
Basalt
Basalt is an end-to-end platform for developers and product teams to build, evaluate, and monitor reliable AI agents. …
Basalt is an end-to-end platform for developers and product teams to build, evaluate, and monitor reliable AI agents. It provides a comprehensive suite of tools, including automated evaluations, A/B testing, prompt engineering with an AI co-pilot, and a developer-friendly SDK to ensure your AI features are trustworthy and production-ready.
Evidently AI
Evidently AI is a comprehensive testing and evaluation platform for AI products, specializing in LLM and ML model …
Evidently AI is a comprehensive testing and evaluation platform for AI products, specializing in LLM and ML model monitoring. It helps teams ensure AI safety, reliability, and performance through automated evaluation, synthetic data generation, continuous testing, and adversarial attacks. Built on a powerful open-source library, it's designed for data scientists and MLOps engineers to detect issues like hallucinations, data drift, and PII leaks before they impact users.

Adaline
Adaline is an end-to-end platform for product and engineering teams to iterate, evaluate, deploy, and monitor Large Language …
Adaline is an end-to-end platform for product and engineering teams to iterate, evaluate, deploy, and monitor Large Language Models (LLMs). It streamlines the entire AI application lifecycle, enabling faster development, enhanced collaboration, and reliable deployment of AI-powered features.
Confident AI
Confident AI is an LLM evaluation and observability platform for engineering teams. Built by the creators of the …
Confident AI is an LLM evaluation and observability platform for engineering teams. Built by the creators of the open-source DeepEval library, it helps benchmark, safeguard, and improve LLM applications through comprehensive metrics, regression testing, and detailed tracing to ensure consistent AI performance.
RagaAI
RagaAI is a comprehensive AI testing and observability platform designed to help developers and enterprises build reliable AI …
RagaAI is a comprehensive AI testing and observability platform designed to help developers and enterprises build reliable AI applications. It offers a suite of tools for observing, evaluating, and debugging AI agents, LLMs, and RAG systems. Key features include agentic testing, real-time guardrails, synthetic data generation, and fine-tuning capabilities. RagaAI supports multimodal data (LLMs, computer vision, tabular) and aims to automate the entire AI quality assurance lifecycle, from issue detection to resolution, ensuring robust and trustworthy AI deployments.
AfterQuery
AfterQuery is an AI research lab dedicated to advancing foundational models by creating high-quality, human-generated datasets and contamination-free …
AfterQuery is an AI research lab dedicated to advancing foundational models by creating high-quality, human-generated datasets and contamination-free benchmarks. It focuses on improving model performance through superior training data and rigorous evaluation.
promptfoo
promptfoo is a comprehensive testing and evaluation framework for Large Language Models (LLMs). It helps developers and enterprises …
promptfoo is a comprehensive testing and evaluation framework for Large Language Models (LLMs). It helps developers and enterprises compare prompt quality, evaluate model performance, and enhance AI security through systematic testing, benchmarking, and AI-powered red teaming. It supports over 50 LLM providers, including local models, and offers a developer-friendly CLI for seamless integration into development workflows.
BenchLLM
A powerful open-source framework for AI engineers to evaluate and test Large Language Model (LLM) applications. BenchLLM provides …
A powerful open-source framework for AI engineers to evaluate and test Large Language Model (LLM) applications. BenchLLM provides a flexible API and a robust CLI to build test suites, generate quality reports, and integrate model evaluation into CI/CD pipelines, ensuring predictable and high-quality results.
getmaxim
getmaxim is a comprehensive GenAI evaluation and observability platform designed for AI development teams. It enables users to …
getmaxim is a comprehensive GenAI evaluation and observability platform designed for AI development teams. It enables users to test, monitor, and improve AI applications by running extensive evaluations on LLMs and RAG pipelines, automating testing, and providing real-time production monitoring to ensure high-quality, reliable, and responsible AI.
Giskard
Giskard is an AI testing platform designed to secure and validate LLM-based applications. It helps enterprise teams detect …
Giskard is an AI testing platform designed to secure and validate LLM-based applications. It helps enterprise teams detect and mitigate risks such as hallucinations, security vulnerabilities, bias, and performance issues before deployment. By automating test generation and enabling continuous red teaming, Giskard ensures AI agents are reliable, safe, and compliant.