BenchLLM
Visit Website
BenchLLM Overview
BenchLLM is a specialized, open-source evaluation framework meticulously crafted by AI engineers for AI engineers. It directly addresses the critical challenge of ensuring reliability and predictability in applications powered by Large Language Models (LLMs). As AI models become more powerful and integrated into products, the need for systematic testing moves from a 'nice-to-have' to an essential part of the development lifecycle. BenchLLM provides the tools to bridge the gap between the probabilistic nature of LLMs and the demand for deterministic, high-quality performance.
The framework is designed to be both powerful and flexible, allowing developers to create, manage, and execute comprehensive test suites. These tests can assess various aspects of model performance, from factual accuracy and hallucination detection to adherence to specific output formats. By integrating these evaluations directly into the development workflow, teams can build with confidence, catch regressions early, and consistently deliver a superior user experience.
How to use BenchLLM
Using BenchLLM is straightforward and designed to fit into existing development workflows. The process typically involves a few key steps:
- Installation: As a Python library, BenchLLM can be easily installed into your project environment using a package manager like pip.
- Define Tests: You can define your test cases intuitively using simple, human-readable formats like YAML or JSON. Each test case consists of an input prompt and one or more expected outputs. This allows for easy versioning and collaboration, as tests can be stored alongside your source code.
- Integrate with Your Code: BenchLLM provides a simple API to wrap your LLM-calling functions. Whether you are using the OpenAI library directly, Langchain agents, or a custom API, you can easily connect it to the BenchLLM tester.
- Run Tests: Tests can be executed using either the powerful Command Line Interface (CLI) or programmatically via the Python API. The CLI command `bench run` will execute your defined test suites and generate predictions from your model.
- Evaluate and Report: After running the tests, you use an `Evaluator` (e.g., `SemanticEvaluator`) to compare the model's actual outputs against the expected ones. BenchLLM then generates insightful reports that clearly show which tests passed and which failed, providing the context needed for debugging and improvement.
Core Features of BenchLLM
- Flexible Test Definition: Create and organize tests in easy-to-manage YAML or JSON files, allowing for clear, version-controlled test suites.
- Powerful CLI: A robust command-line interface allows you to run evaluations, generate reports, and seamlessly integrate testing into CI/CD pipelines for full automation.
- Versatile API: A developer-friendly Python API enables on-the-fly testing and custom evaluation logic directly within your application code.
- Multiple Evaluation Strategies: Supports various evaluation methods, including exact match, regex, and advanced semantic similarity checks, to accurately assess model output quality.
- Broad Compatibility: Offers out-of-the-box support for popular libraries like OpenAI and Langchain, and is extensible to work with any custom LLM API.
- Comprehensive Reporting: Generates clear and actionable evaluation reports that highlight failures, performance metrics, and regressions, which can be easily shared with your team.
- Production Monitoring: The framework can be used to monitor model performance in production, helping to detect performance drift and ensure ongoing reliability.
Use Cases for BenchLLM
BenchLLM is versatile and can be applied in numerous scenarios throughout the AI development lifecycle. Key use cases include: Regression Testing in CI/CD, where it automatically verifies that new changes haven't degraded the model's performance; Hallucination Detection, by creating tests with questions that have no known answer (e.g., future events) to ensure the model responds appropriately; Model Benchmarking, allowing you to run the same test suite against different LLMs (e.g., GPT-4 vs. Claude 3) or prompt variations to objectively measure and compare their performance; and Quality Assurance, by establishing a baseline of quality that all model versions must meet before deployment.
Advantages of BenchLLM
The primary advantage of BenchLLM is that it is built with a developer-first mindset. It's an open and flexible tool that gives engineers full control over the evaluation process, unlike some closed-box solutions. Being open-source, it offers maximum transparency and customizability. It transforms LLM development into a more structured, predictable engineering discipline, moving away from trial-and-error. By automating the tedious and error-prone task of manual testing, it significantly streamlines the development cycle, improves product quality, and boosts developer productivity.
Pricing and Plans
BenchLLM is a completely free and open-source tool, built and maintained by the team at V7. It is available for anyone to download, use, and contribute to via its GitHub repository. There are no paid plans, subscriptions, or hidden costs required to use its full feature set, making it an accessible choice for individual developers, startups, and large enterprises alike.
BenchLLM Comments (0)
Log in to post comments
Log in nowBenchLLMWebsite Traffic Analysis
Latest Traffic
Status
Monthly Traffic Trend
Geography
Top 5 Countries/Regions
-
🇮🇳 India100.00%
BenchLLM Alternatives
View All
TestZeus
TestZeus is an AI-powered, no-code test automation platform specifically designed for Salesforce. It utilizes autonomous AI agents to …
TestZeus is an AI-powered, no-code test automation platform specifically designed for Salesforce. It utilizes autonomous AI agents to write, execute, and maintain tests from natural language inputs, achieving up to 100% test coverage in days while eliminating maintenance overhead.
codegate
Codegate is an open-source security gateway and multiplexing framework for AI agentic systems. Developed by Stacklok, it provides …
Codegate is an open-source security gateway and multiplexing framework for AI agentic systems. Developed by Stacklok, it provides secure workspaces and policy-based access control, enabling developers to build and manage complex multi-agent applications safely and efficiently.
vocode
Vocode is an open-source platform for building, deploying, and scaling hyperrealistic voice AI agents. It provides developers with …
Vocode is an open-source platform for building, deploying, and scaling hyperrealistic voice AI agents. It provides developers with a core framework and an enterprise-grade API to create sophisticated voice-based LLM applications for tasks like automated customer service, sales calls, and interactive voice response (IVR) systems.
Confident AI
Confident AI is an LLM evaluation and observability platform for engineering teams. Built by the creators of the …
Confident AI is an LLM evaluation and observability platform for engineering teams. Built by the creators of the open-source DeepEval library, it helps benchmark, safeguard, and improve LLM applications through comprehensive metrics, regression testing, and detailed tracing to ensure consistent AI performance.
CrewAI
CrewAI is an advanced open-source framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, it enables …
CrewAI is an advanced open-source framework for orchestrating role-playing, autonomous AI agents. By fostering collaborative intelligence, it enables agents with distinct roles and tools to work together seamlessly to solve complex tasks. This multi-agent system simplifies the development of sophisticated applications, from automated content creation to complex data analysis, by managing agent interactions, task delegation, and workflow processes.
CopilotKit
CopilotKit is an open-source, full-stack framework for developers to build, deploy, and customize in-app AI copilots and agentic …
CopilotKit is an open-source, full-stack framework for developers to build, deploy, and customize in-app AI copilots and agentic applications. It provides front-end components, back-end logic, and seamless integrations with any LLM or agent framework, enabling the creation of powerful, user-facing AI assistants.
phidata
phidata is an open-source Python framework for building autonomous AI Assistants. It simplifies the integration of LLMs with …
phidata is an open-source Python framework for building autonomous AI Assistants. It simplifies the integration of LLMs with memory, knowledge bases, and external tools, enabling developers to create powerful, stateful AI applications with ease.
Blaxel
Blaxel is a serverless computing platform designed for AI developers, providing the infrastructure and tools to build, deploy, …
Blaxel is a serverless computing platform designed for AI developers, providing the infrastructure and tools to build, deploy, and scale agentic AI applications efficiently. It offers sandboxed VMs, a unified LLM gateway, and deep observability.
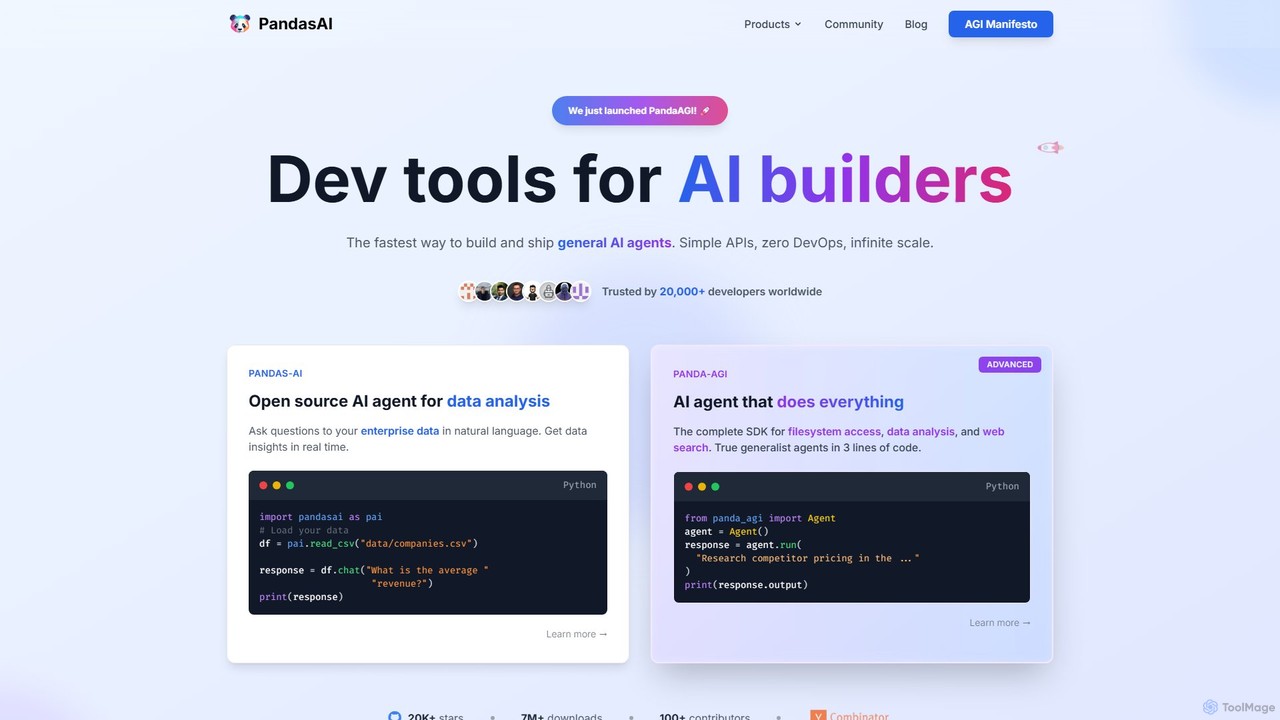
PandasAI
PandasAI offers a suite of developer tools for building AI applications. It features an open-source library for conversational …
PandasAI offers a suite of developer tools for building AI applications. It features an open-source library for conversational data analysis using natural language and PandaAGI, an advanced SDK for creating generalist AI agents that can perform complex tasks like web searches and filesystem access.
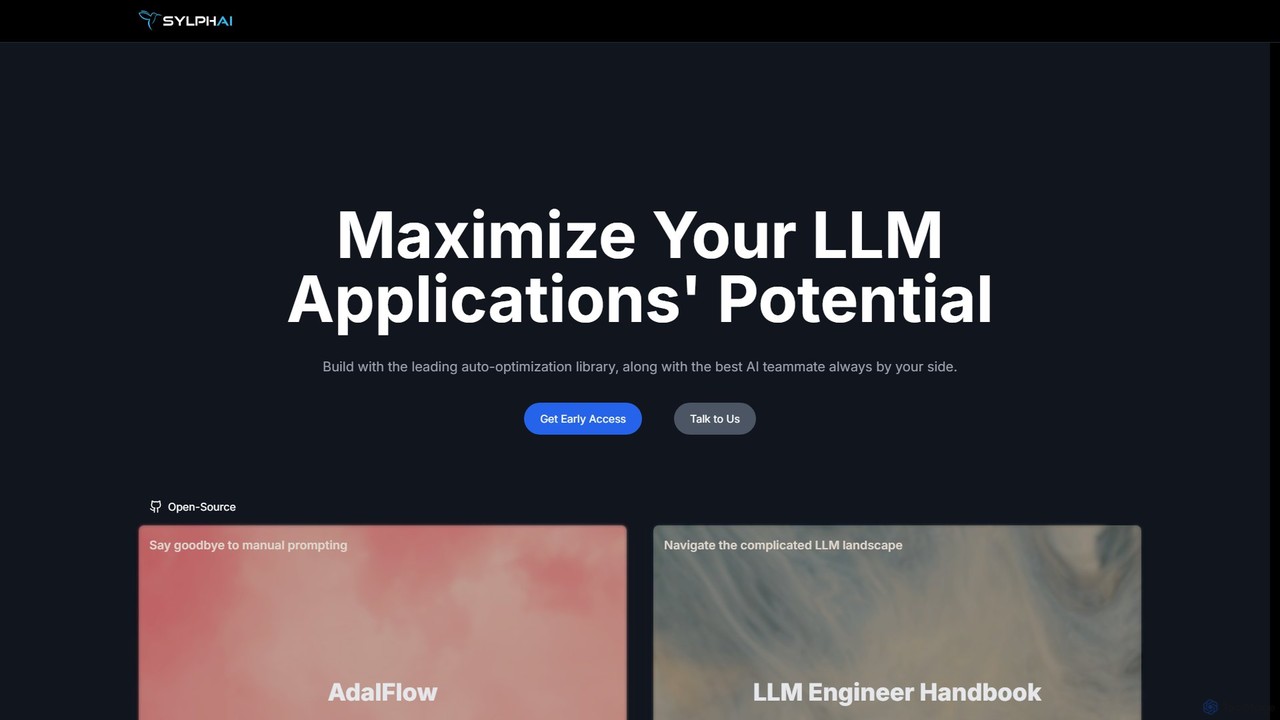
Sylph AI
Sylph AI is a development platform designed to maximize the potential of LLM applications. It features AdalFlow, a …
Sylph AI is a development platform designed to maximize the potential of LLM applications. It features AdalFlow, a leading open-source library for building and auto-optimizing LLM task pipelines, and an AI Teammate that provides expert guidance throughout the entire development workflow, from ideation to production.
BenchLLM Category
BenchLLM Tag
BenchLLM AI Tool Comparison
BenchLLM Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!