
Milvus
Milvus is a high-performance, open-source vector database built for AI applications. It enables developers to manage and search …
Milvus is a high-performance, open-source vector database built for AI applications. It enables developers to manage and search through billions of high-dimensional vectors with minimal latency. Ideal for building scalable systems like retrieval-augmented generation (RAG), recommendation engines, and semantic search, Milvus offers flexible deployment options from local prototyping to large-scale distributed clusters.
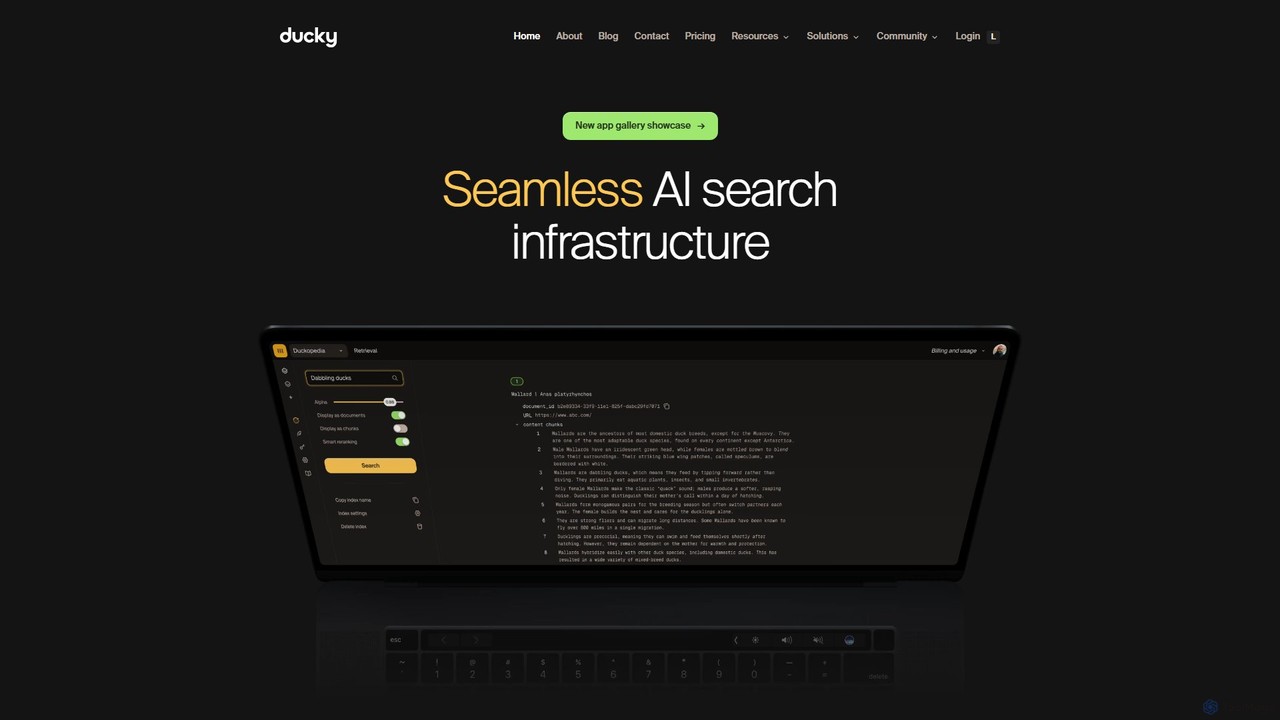
Ducky
Ducky is a fully managed AI search infrastructure designed for developers. It simplifies the implementation of Retrieval-Augmented Generation …
Ducky is a fully managed AI search infrastructure designed for developers. It simplifies the implementation of Retrieval-Augmented Generation (RAG) by handling complex tasks like data chunking, embedding, and reranking. With a simple Python SDK, Ducky enables developers to quickly build fast, accurate, and scalable semantic search capabilities into their applications, providing context-aware and hallucination-free responses from LLMs.
About Vector Search
Vector Search tools are a specialized class of data retrieval systems that find information based on semantic similarity, not just exact keyword matches. They work by converting data like text, images, or audio into numerical representations called vectors and then searching for the closest vectors in a high-dimensional space. This enables applications to understand context and meaning, powering more intuitive search experiences, recommendation engines, and AI-driven knowledge bases. Unlike traditional search, vector search excels at handling complex queries and unstructured data.
Core Features
- Semantic Similarity Search: Identifies conceptually related items even if they do not share keywords.
- High-Dimensional Indexing: Employs specialized algorithms (like HNSW) for fast retrieval from billions of vectors.
- Multi-modal Capabilities: Supports searching across different data types, such as using an image to find relevant text.
- Real-time Scalability: Designed to handle massive datasets and high query loads with low latency.
- Hybrid Search: Combines vector similarity with traditional metadata or keyword filtering for more precise results.
Use Cases
Vector Search is crucial for developers and data scientists building modern AI applications. It forms the backbone of Retrieval-Augmented Generation (RAG) systems for AI chatbots, e-commerce visual recommendation engines, and platforms for detecting duplicate content. It is also applied in security for anomaly detection and in scientific research for pattern matching in complex datasets.
How to Choose
When selecting a Vector Search tool, consider its scalability and performance under your expected load. Evaluate the supported indexing algorithms and their trade-offs between speed and accuracy. Assess its integration capabilities with embedding models and existing data infrastructure. Also, compare deployment options (cloud-managed, self-hosted) and the associated pricing models and technical overhead.
Vector SearchUse Cases
Powering AI Chatbot Knowledge Bases (RAG)
An AI developer is tasked with building a customer support chatbot that can answer complex questions based on a large library of technical documents. Instead of fine-tuning a large language model, they use a vector search system. First, all documents are chunked and converted into vector embeddings. When a user asks a question, the question is also converted into a vector. The system then performs a vector search to find the most semantically similar document chunks. These relevant chunks are provided as context to a language model, which then generates an accurate, source-based answer. This approach, known as Retrieval-Augmented Generation (RAG), significantly improves answer accuracy and reduces hallucinations.
Visual Product Recommendation for E-commerce
An e-commerce platform wants to improve its 'similar products' feature. Traditional methods based on tags and categories often fail to capture visual nuances. By implementing a vector search engine, they convert each product image into a vector embedding. When a customer views a product, its image vector is used to query the database for the nearest neighbors. The result is a list of products that are visually similar in style, color, and pattern, even if their metadata descriptions are completely different. This leads to a more engaging user experience, increased product discovery, and higher conversion rates as customers can easily find alternatives that match their aesthetic preferences.
Content Deduplication and Discovery
A large media company manages millions of articles and images. They face two challenges: preventing duplicate content uploads and helping users discover related articles. They use a vector search database to store embeddings of all their content. When a new article is submitted, its content is converted to a vector and checked against the database. If a very close vector already exists, the article is flagged as a potential duplicate, saving editorial time. For readers, when they finish an article, its vector is used to find other articles with similar semantic content, providing more relevant 'read next' suggestions than simple category-based links.
Anomaly Detection in Cybersecurity
A cybersecurity analyst needs to monitor network traffic for unusual activities that might indicate a threat. They use a vector search system to model normal network behavior. Each network event (like a login attempt or data transfer) is converted into a vector based on its attributes. Over time, these vectors form clusters representing normal operations. The system continuously converts new events into vectors and searches for their nearest neighbors. If a new event's vector is far from any existing cluster (i.e., it has no close neighbors), it is flagged as an anomaly for immediate investigation. This allows for the detection of novel, zero-day threats that signature-based systems would miss.
Reverse Image Search Engines
A journalist needs to verify the authenticity of a photo circulating on social media. They use a reverse image search tool powered by vector search. The journalist uploads the image, which is instantly converted into a vector embedding by the tool. This vector is then used to search a massive, pre-indexed database of images from across the web. The search returns visually similar images in milliseconds, allowing the journalist to identify the original source, context, and date of the photo. This process helps combat misinformation by quickly debunking fake or out-of-context images, a task that would be impossible with keyword-based search.
Accelerating Drug Discovery and Genomics
A bioinformatician is searching for chemical compounds with properties similar to a newly discovered molecule. Representing molecules as vector embeddings based on their structural and chemical properties allows for similarity searches at a massive scale. The researcher inputs the new molecule's vector into a vector search database containing millions of known compounds. The system returns a ranked list of the most similar molecules, drastically narrowing down the candidates for laboratory testing. This same principle applies to genomics, where vector search can identify gene sequences with similar functional patterns, accelerating research into diseases and treatments.