
Browserless
Browserless is a powerful Browser-as-a-Service (BaaS) platform designed for scalable web scraping and browser automation. It helps developers …
Browserless is a powerful Browser-as-a-Service (BaaS) platform designed for scalable web scraping and browser automation. It helps developers bypass CAPTCHAs and bot detectors effortlessly using Puppeteer, Playwright, or its proprietary BrowserQL language. The service manages browser infrastructure, allowing users to focus on building automation scripts without worrying about updates, memory leaks, or scaling.

Crawlbase
Crawlbase is an AI-powered web crawling and data scraping platform for developers and businesses. It provides a suite …
Crawlbase is an AI-powered web crawling and data scraping platform for developers and businesses. It provides a suite of tools, including a Crawling API and Smart Proxy, to anonymously extract data from any website at scale, bypassing blocks and CAPTCHAs with a high success rate. It simplifies data collection for SEO, market research, e-commerce intelligence, and training AI models.

Scrappey
Scrappey is an advanced web scraping API designed for developers to effortlessly extract data from any website. It …
Scrappey is an advanced web scraping API designed for developers to effortlessly extract data from any website. It handles all complexities like rotating proxies, headless browsers, and bypassing anti-bot measures such as Cloudflare and CAPTCHAs. With a high success rate and a simple pay-as-you-go model, Scrappey streamlines data collection for various applications.

Apify
Apify is a full-stack web scraping and automation platform that enables developers to build, deploy, and publish data …
Apify is a full-stack web scraping and automation platform that enables developers to build, deploy, and publish data extraction tools, known as 'Actors'. It offers a vast marketplace of pre-built scrapers for popular websites like Google Maps, Instagram, and TikTok, alongside a robust cloud infrastructure for creating custom solutions. With support for Python and JavaScript, open-source libraries, and seamless integrations, Apify simplifies collecting web data at any scale.

Crawlbase
Crawlbase is an AI-powered web scraping and crawling platform designed for developers and businesses. It simplifies data extraction …
Crawlbase is an AI-powered web scraping and crawling platform designed for developers and businesses. It simplifies data extraction by handling proxies, CAPTCHAs, and anti-bot systems, allowing you to anonymously crawl any website and retrieve clean, structured data at scale. It offers a suite of tools including a Crawling API, Smart Proxy, and Cloud Storage.
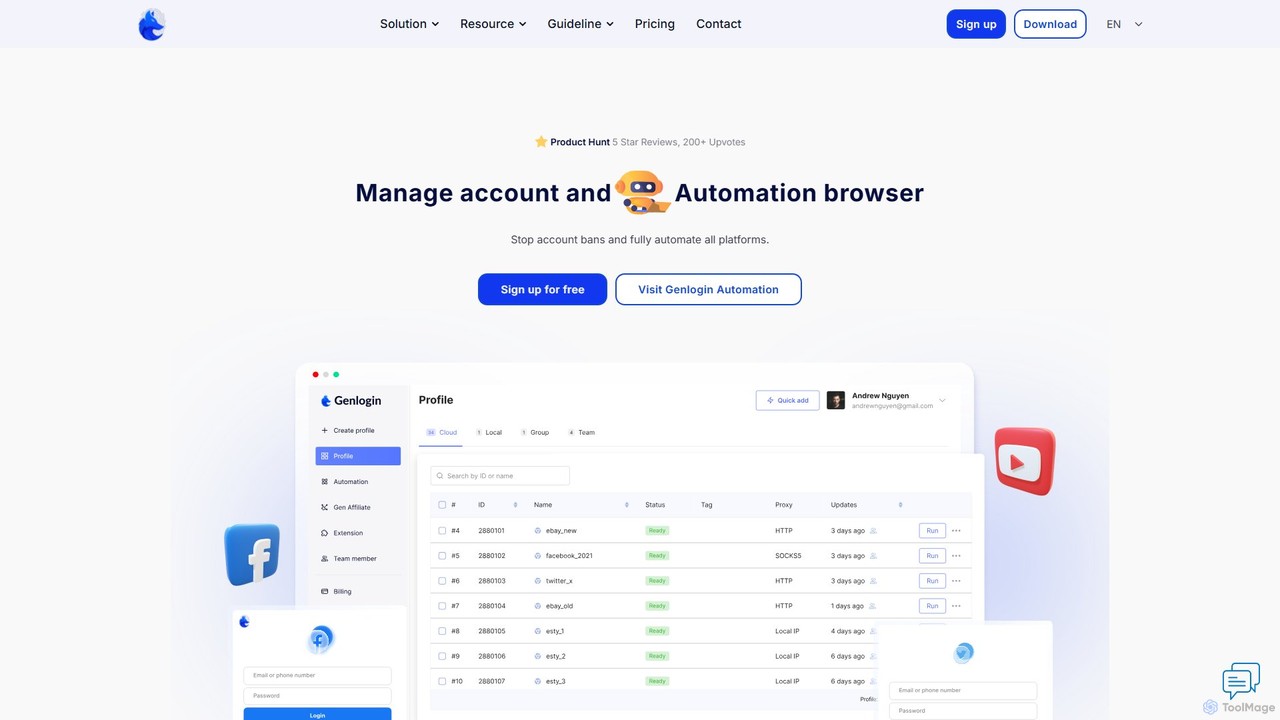
Genlogin
Genlogin is an advanced antidetect browser designed for managing multiple online accounts securely and efficiently. It prevents account …
Genlogin is an advanced antidetect browser designed for managing multiple online accounts securely and efficiently. It prevents account bans by creating unique, real-data-based browser fingerprints for each profile. With features like no-code automation, real-time action synchronization, and a built-in proxy service, Genlogin is ideal for e-commerce, social media marketing, data scraping, and affiliate marketing, empowering users to scale their online operations.

WebScraping.AI
WebScraping.AI is an advanced API for developers that simplifies web scraping using AI. It features rotating proxies, JavaScript …
WebScraping.AI is an advanced API for developers that simplifies web scraping using AI. It features rotating proxies, JavaScript rendering, and geotargeting to bypass blocks and access dynamic content. Its core strength lies in its LLM-powered tools, which can extract unstructured data, generate summaries, and answer questions directly from web pages, streamlining data collection for any project.

FetchFox
FetchFox is an AI-powered web scraping tool that allows users to extract data from any website using simple …
FetchFox is an AI-powered web scraping tool that allows users to extract data from any website using simple text prompts. It eliminates the need for complex coding or CSS selectors, automatically handling anti-bot measures. Available as an API, JavaScript library, and Chrome extension, it's designed for both developers and non-technical users to automate data collection effortlessly.

CapSolver
CapSolver is an AI-powered, automatic CAPTCHA solving service designed for developers and RPA professionals. It provides a high-accuracy, …
CapSolver is an AI-powered, automatic CAPTCHA solving service designed for developers and RPA professionals. It provides a high-accuracy, fast, and scalable solution to bypass various types of CAPTCHAs, including reCAPTCHA, hCaptcha, and FunCaptcha, facilitating seamless web scraping, data extraction, and process automation.
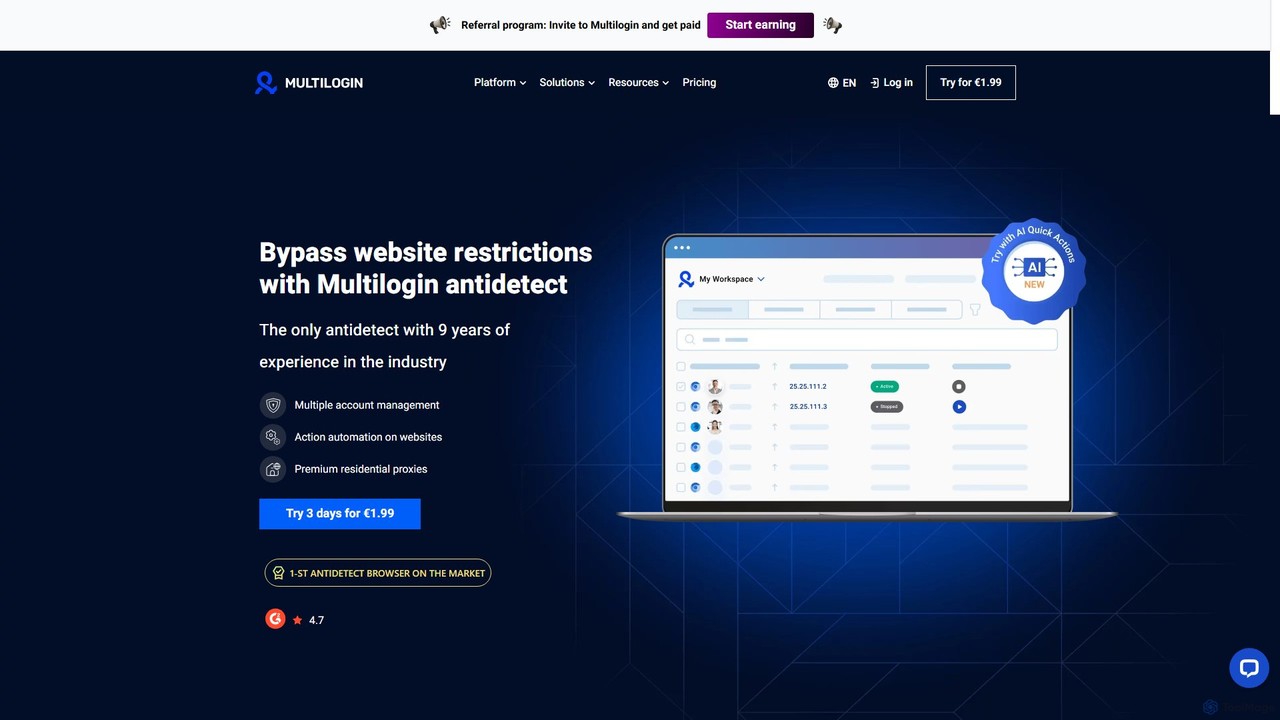
Multilogin
Multilogin is a leading antidetect browser that allows users to create and manage multiple unique browser profiles. It's …
Multilogin is a leading antidetect browser that allows users to create and manage multiple unique browser profiles. It's designed to prevent website restrictions and account bans by masking digital fingerprints, making it ideal for social media marketing, e-commerce, web scraping, and other multi-account operations. It includes features like team collaboration, automation support, and built-in residential proxies.
Horseman
Horseman is an endlessly configurable desktop web crawler for developers, SEOs, and performance analysts. It leverages custom JavaScript …
Horseman is an endlessly configurable desktop web crawler for developers, SEOs, and performance analysts. It leverages custom JavaScript snippets and integrated GPT-3.5 to extract, analyze, and manipulate website data, offering deep insights across entire sites without requiring advanced coding knowledge.

ScrapingBee
ScrapingBee is a powerful web scraping API that handles headless browsers and proxy rotation to prevent getting blocked. …
ScrapingBee is a powerful web scraping API that handles headless browsers and proxy rotation to prevent getting blocked. It features an innovative AI-powered extractor that lets you describe the data you need in plain English, eliminating the need for complex CSS selectors. Ideal for developers, marketers, and data analysts for tasks like price monitoring, lead generation, and SERP analysis.

PageLlama
PageLlama is an AI-powered tool designed for developers and researchers. It effortlessly converts any web page content into …
PageLlama is an AI-powered tool designed for developers and researchers. It effortlessly converts any web page content into clean, structured, and LLM-ready Markdown. By removing clutter like ads and navigation, it provides high-fidelity data, optimizing token usage and improving the accuracy of AI applications like RAG systems and data analysis models.
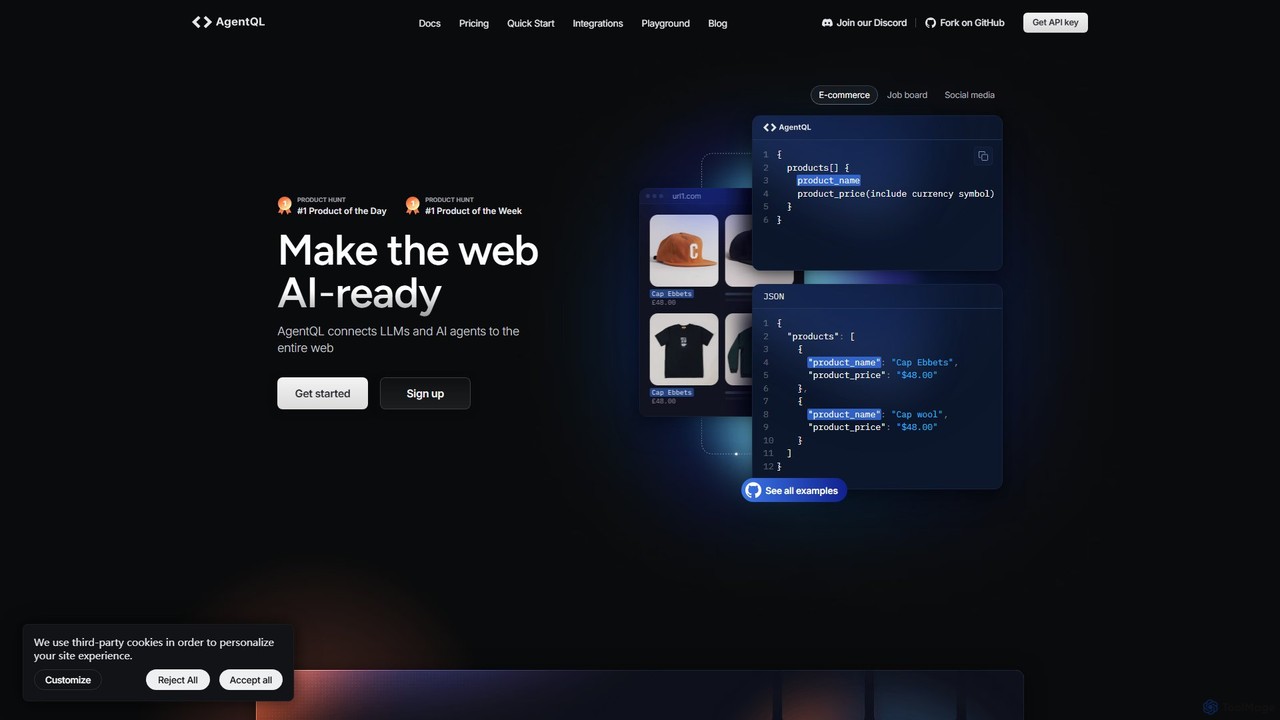
AgentQL
AgentQL is a developer toolset that connects LLMs and AI agents to the web. It uses an AI-powered …
AgentQL is a developer toolset that connects LLMs and AI agents to the web. It uses an AI-powered query language to robustly extract structured data and automate web interactions, serving as a powerful, self-healing alternative to fragile XPath and CSS selectors.
URLtoText
URLtoText is an AI-powered tool that extracts clean, structured text from any website or PDF. It intelligently removes …
URLtoText is an AI-powered tool that extracts clean, structured text from any website or PDF. It intelligently removes ads, sidebars, and other clutter to provide only the main content. Featuring JavaScript rendering, residential IP proxies, and a developer API, it's designed for researchers, developers, and businesses needing reliable data extraction from both static and dynamic web pages.
About Web Scraping
Web Scraping tools are AI-powered solutions designed to automatically extract data from websites. These tools leverage advanced algorithms, often incorporating natural language processing and machine learning, to navigate web pages, identify, and collect structured or unstructured information. They are essential for automating tedious manual data collection, providing scalable and efficient data acquisition for various analytical needs. This capability makes them invaluable for businesses and researchers seeking to gather insights from the vast amount of public web data.
Core Features
- Automated Data Extraction: Systematically collects specific data points like text, images, and links from web pages.
- Dynamic Content Handling: Interacts with JavaScript-rendered content, forms, and pagination to access all relevant data.
- Anti-Scraping Bypass: Employs techniques to circumvent common anti-bot measures such as CAPTCHAs and IP blocking.
- Data Structuring & Export: Organizes extracted data into usable formats like CSV, JSON, or XML for easy analysis and integration.
- Scheduling & Monitoring: Allows users to schedule scraping tasks and monitor websites for new or updated information.
Applicable Scenarios
Web scraping tools are widely used in market intelligence gathering for businesses, enabling them to monitor competitor pricing and product information. They are also crucial for academic researchers collecting large datasets from public sources for statistical analysis. E-commerce platforms utilize these tools for real-time price monitoring and inventory tracking across various online retailers.
How to Choose
When selecting a web scraping tool, consider its ability to handle the complexity of target websites, including dynamic content and anti-scraping measures. Evaluate its scalability and scheduling capabilities based on your required data volume and frequency. Assess the ease of use, whether through a no-code interface or a robust API for developers. Finally, ensure the tool supports ethical scraping practices and compliance with data privacy regulations.
Web ScrapingUse Cases
Competitive Price Monitoring for E-commerce
E-commerce businesses utilize web scraping tools to continuously monitor competitor pricing across various online platforms. This allows them to track price changes, identify promotional offers, and adjust their own pricing strategies in real-time to remain competitive. By automating this process, businesses can save significant manual effort and ensure their product offerings are always optimally priced, leading to increased sales and market share.
Lead Generation and Sales Intelligence
Sales and marketing teams leverage web scraping to extract valuable lead information from public directories, professional networking sites, or industry-specific portals. This includes contact details, company profiles, and job titles, which are then used to build targeted prospect lists. Automating lead generation significantly reduces the time spent on manual data entry, allowing sales professionals to focus on engagement and conversion, thereby improving sales pipeline efficiency.
Market Research and Trend Analysis
Researchers and analysts use web scraping to gather vast amounts of public data from news articles, forums, social media, and review sites. This data is then processed for sentiment analysis, trend identification, and competitive intelligence. By automating data collection, they can quickly acquire up-to-date information on consumer opinions, emerging market trends, and public perception of brands or products, enabling more informed strategic decisions.
Content Aggregation for News Portals
Media companies and news aggregators employ web scraping tools to automatically collect articles, headlines, images, and videos from various news sources and blogs. This enables them to populate their own news feeds or content platforms with fresh, diverse content without manual curation. The automation ensures a constant flow of information, keeping their audience engaged and informed, while significantly reducing editorial workload.
Real Estate Listing Analysis
Real estate professionals and investors use web scraping to collect property listings from multiple online platforms, including real estate portals and classifieds. This aggregated data allows for comprehensive market analysis, identifying trends in property values, rental rates, and availability across different regions. By automating this data collection, they can make faster, more informed decisions on property acquisitions, sales, and investment strategies, gaining a competitive edge.
Academic Research Data Collection
Academics and researchers frequently use web scraping to build large datasets for their studies. This involves extracting information from scientific publications, government databases, public archives, and specialized forums. The ability to quickly gather and structure vast amounts of data from diverse online sources is crucial for empirical research, statistical analysis, and validating hypotheses, significantly accelerating the research process and enabling deeper insights.