FinetuneFast
Visit Website
FinetuneFast Overview
FinetuneFast is an essential toolkit designed for ML engineers, developers, and indie makers who want to accelerate their AI development lifecycle. It offers a comprehensive collection of ML boilerplates that streamline the entire process, from model training and data preparation to deployment and scaling. The core mission of FinetuneFast, created by experienced ML and SRE engineer Patrick, is to eliminate the repetitive and time-consuming tasks associated with setting up AI infrastructure, allowing creators to focus on what truly matters: building and refining powerful AI models.
The platform addresses common pain points in the ML workflow, such as configuring environments, cleaning data, integrating APIs, and deploying models. By providing pre-configured, production-ready solutions, FinetuneFast claims to save developers over 20 hours of work on a typical project, transforming a multi-week endeavor into a matter of days.
How to use FinetuneFast
Using FinetuneFast is a straightforward process for anyone with programming experience. After purchasing a plan, you will receive manual access to a private GitHub repository within 24 hours. Inside, you'll find a well-organized collection of boilerplates and templates. The typical workflow is as follows:
- Select a Boilerplate: Choose the appropriate template for your project, whether it's fine-tuning an LLM like Llama-3, a text-to-image model like Flux-Schnell, or implementing a RAG (Retrieval-Augmented Generation) system.
- Setup and Configuration: Follow the detailed documentation to set up your environment and configure the scripts with your specific parameters and data paths.
- Data Preparation: Utilize the efficient data loading pipelines to prepare and format your training data.
- Model Training: Run the pre-configured training scripts. The boilerplates include support for multi-GPU training and hyperparameter optimization tools to achieve the best results.
- Deployment: Once your model is fine-tuned, use the deployment boilerplates for one-click deployment. This generates a scalable API endpoint for your model, complete with monitoring and logging.
- Support: For technical questions, the 'All In' plan provides access to a dedicated Discord community for support from the creator and other users.
Core Features of FinetuneFast
- Finetuning Boilerplates: Production-ready scripts for fine-tuning various models, including LLMs (OpenAI, Mistral, Llama-3.2), text-to-image models (Flux-Schnell), and text-to-speech (Fish-Speech).
- Inference and Deployment Boilerplates: Simplified, one-click deployment solutions to create auto-scaling, production-ready API endpoints for your models.
- RAG Examples and Templates: Ready-to-use templates for building advanced Retrieval-Augmented Generation systems, allowing models to access external knowledge.
- Efficient Data Pipelines: Optimized scripts for loading and processing data, a critical but often lengthy part of the ML process.
- Multi-GPU Support: Out-of-the-box support for training on multiple GPUs, significantly speeding up the training process.
- Best Practices Included: The code incorporates best practices in ML and SRE, ensuring your models are not only powerful but also reliable and scalable.
Use Cases for FinetuneFast
FinetuneFast is versatile and can be used for a wide range of projects:
- AI SaaS Products: Indie developers can rapidly build and launch niche AI-SaaS applications, such as a specialized content generator or a custom image creation tool.
- Custom Chatbots: Businesses can fine-tune an open-source LLM on their internal documents to create a private knowledge base or a customer support bot.
- AI Art Generation: Artists and designers can fine-tune image models on their unique style to produce consistent and original artwork.
- Rapid Prototyping: ML engineers can quickly test and validate new ideas without getting bogged down in setting up the underlying infrastructure.
- Specialized AI Services: Building specific tools like background removal (RMBG-1.4) or multimodal applications (Molmo-7B) using the provided boilerplates.
Advantages of FinetuneFast
The primary advantage of FinetuneFast is speed. It drastically reduces development time. Other key benefits include:
- Cost-Effective: A one-time payment provides access to all materials for unlimited projects, making it much more affordable than subscription-based platforms or hiring for setup.
- Production-Ready: The boilerplates are not just for academic exercises; they are built to handle real-world traffic and scale automatically.
- Expert-Built: Designed by an engineer with deep expertise in both Machine Learning and Site Reliability Engineering, ensuring high standards of quality and reliability.
- Comprehensive Solution: Covers the end-to-end ML lifecycle, from training to deployment and monitoring.
Pricing and Plans
FinetuneFast offers a simple, one-time payment model.
- Starter Plan: Priced at $99.99 (on sale from $159.99). This plan includes Finetuning Boilerplates, Production-ready Inference Boilerplates, RAG Examples and Templates, and Best Practices guides.
- All In Plan: Priced at $119.99 (on sale from $199.99). This includes everything in the Starter plan, plus access to the private Discord Community for support and Lifetime Updates to the repository.
Both plans offer a 'pay once, build unlimited projects' license.
FinetuneFast Comments (0)
Log in to post comments
Log in nowFinetuneFast Alternatives
View All
thundercompute
Thunder Compute offers an ultra-low-cost GPU cloud platform designed for AI and machine learning developers. It provides on-demand …
Thunder Compute offers an ultra-low-cost GPU cloud platform designed for AI and machine learning developers. It provides on-demand GPU instances like the NVIDIA A100 and T4 at prices up to 80% lower than major cloud providers. With features like one-click setup, VS Code integration, and seamless scalability, it dramatically simplifies the development workflow, from prototyping to production, allowing developers to focus on building models rather than managing infrastructure.

Paperspace
Paperspace is a high-performance cloud computing platform designed for AI and Machine Learning. It provides effortless access to …
Paperspace is a high-performance cloud computing platform designed for AI and Machine Learning. It provides effortless access to powerful cloud GPUs, managed Jupyter notebooks, and a complete MLOps platform (Gradient) to build, train, and deploy models. Ideal for developers, data scientists, and enterprises looking to accelerate their AI workflows without the complexity of managing infrastructure.
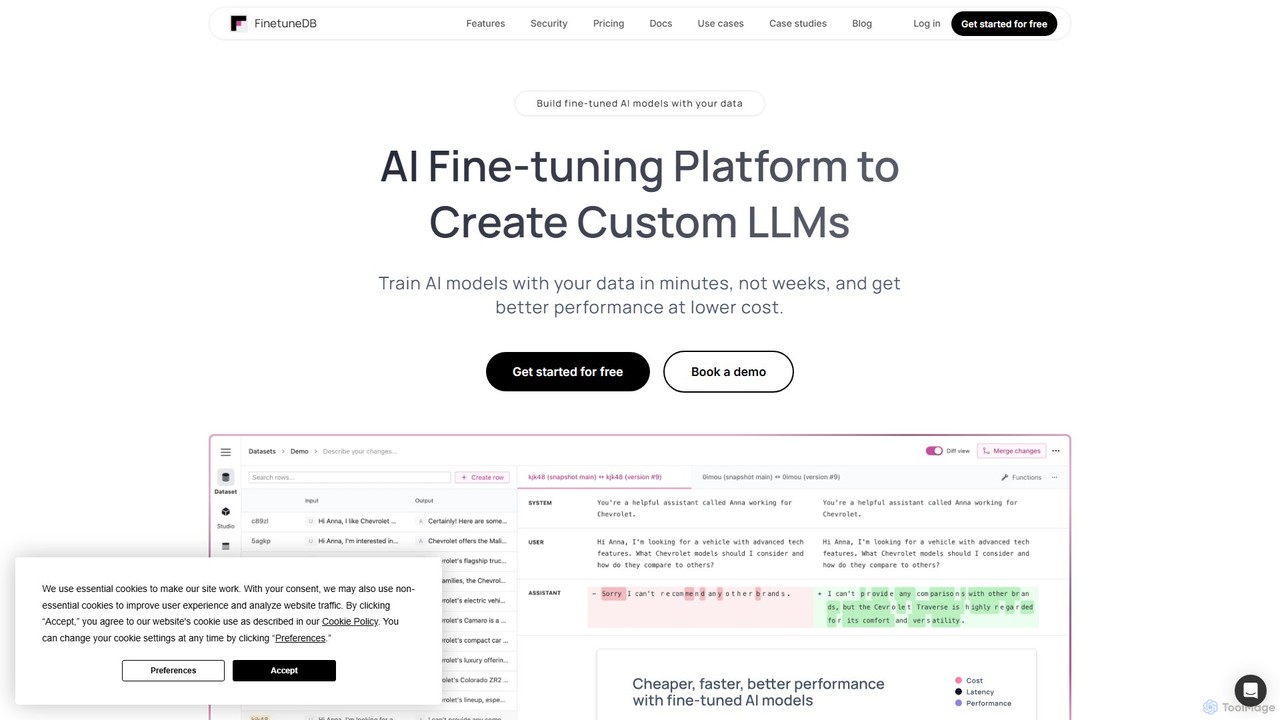
FinetuneDB
FinetuneDB is an all-in-one AI fine-tuning platform for developers. It simplifies the entire workflow of creating custom Large …
FinetuneDB is an all-in-one AI fine-tuning platform for developers. It simplifies the entire workflow of creating custom Large Language Models (LLMs), from building high-quality datasets and fine-tuning models like Llama 3 and GPT-4o mini, to deployment and continuous evaluation on a single, secure platform.

Ollama
Ollama is a powerful open-source framework for running large language models (LLMs) like Llama 3, Mistral, and Gemma …
Ollama is a powerful open-source framework for running large language models (LLMs) like Llama 3, Mistral, and Gemma locally on your own hardware. Available for macOS, Windows, and Linux, it simplifies the setup and management of open-source models, enabling private, offline, and cost-effective AI development and usage.

LAION
LAION (Large-scale Artificial Intelligence Open Network) is a non-profit organization dedicated to democratizing AI research. It provides massive, …
LAION (Large-scale Artificial Intelligence Open Network) is a non-profit organization dedicated to democratizing AI research. It provides massive, open-source datasets, pre-trained models, and tools to the public, fostering open research, education, and resource-efficient development in machine learning.
deepsense.ai
deepsense.ai is a premier AI consulting and custom software development company. They specialize in creating tailored AI solutions …
deepsense.ai is a premier AI consulting and custom software development company. They specialize in creating tailored AI solutions for businesses, leveraging expertise in LLMs, RAG, computer vision, MLOps, and predictive analytics. They partner with enterprises and startups to embed AI into products, optimize operations, and gain a competitive edge through advanced, production-ready AI systems.

xTuring
xTuring is an open-source Python library designed to simplify the process of building, fine-tuning, and controlling Large Language …
xTuring is an open-source Python library designed to simplify the process of building, fine-tuning, and controlling Large Language Models (LLMs). It provides a user-friendly interface for developers and researchers to personalize AI models for specific data and applications with high efficiency and customizability.

Pydantic
Pydantic is a comprehensive platform for developers, offering powerful data validation, AI development tools, and a full-stack observability …
Pydantic is a comprehensive platform for developers, offering powerful data validation, AI development tools, and a full-stack observability solution. It enables faster, more robust application development in Python and other languages by leveraging type hints for runtime data validation and providing deep insights from local development to production.
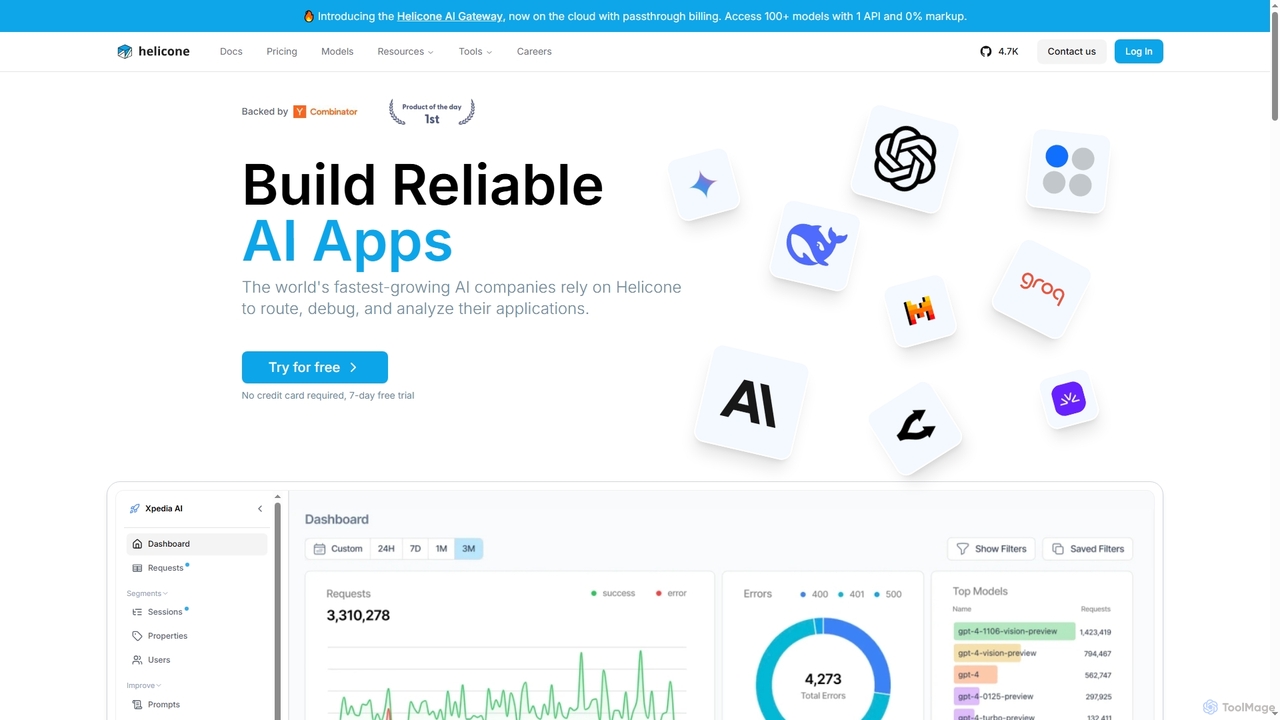
Helicone
Helicone is an open-source platform offering an AI Gateway and LLM Observability for developers. It helps build reliable …
Helicone is an open-source platform offering an AI Gateway and LLM Observability for developers. It helps build reliable AI applications by providing tools to route, monitor, debug, and analyze LLM usage. Key features include a unified API for 100+ models, intelligent caching, rate limiting, prompt management, and detailed performance analytics.

hyperficient
hyperficient is an open-source AI tool for developers and ML engineers that automates the search for the most …
hyperficient is an open-source AI tool for developers and ML engineers that automates the search for the most efficient fine-tuning strategies for neural networks. It significantly reduces computational costs, GPU time, and manual effort, enabling optimal model performance on limited resources.
FinetuneFast Category
FinetuneFast Tag
FinetuneFast AI Tool Comparison
FinetuneFast Embed Feature
Just copy the embed code below and paste this beautiful badge on your blog, article, or official app website to drive traffic directly to this tool's detail page and quickly boost your exposure and user count!

No comments yet, be the first to comment!